Python 爬虫 xpath 数据解析基本用法
免责声明:自本文章发布起, 本文章仅供参考,不得转载,不得复制等操作。浏览本文章的当事人如涉及到任何违反国家法律法规造成的一切后果由浏览本文章的当事人自行承担与本文章博客主无关。以及由于浏览本文章的当事人转载,复制等操作涉及到任何违反国家法律法规引起的纠纷和造成的一切后果由浏览本文章的当事人自行承担与本文章博客主无关。
xpath 解析比 bs4 解析常用.
import requests
from lxml import etree
1. 基本语法
1.1 解析 html 语法
解析本地文件
# 解析本地 html 文件
parser = etree.HTMLParser(encoding="utf-8")
tree = etree.parse("./data/base/taobao.html", parser=parser)
解析网页文件
# url, UA
url = "https://www.aqistudy.cn/historydata/"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:84.0) Gecko/20100101 Firefox/84.0"
}
text = requests.get(url=url, headers=headers).text
# 解析
tree = etree.HTML(text, etree.HTMLParser(encoding="utf-8"))
tree.xpath()进行定为标签, 返回为 List.
1.2 获取标签
/: 表示一个层级, 从根结点开始定位.
//: 表示多个层级, 可以从任意一个位置开始定位.
[n]: 表示定位第一个标签, 索引从1开始.
xpath = tree.xpath("/html/body/div")
print(xpath)
print(tree.xpath("/html//div"))
print(tree.xpath("/html/body/div[2]"))

1.3 获取标签中的内容
定位某个属性标签
[@attribute='attributeValue']: 完全匹配, 而不是包含.
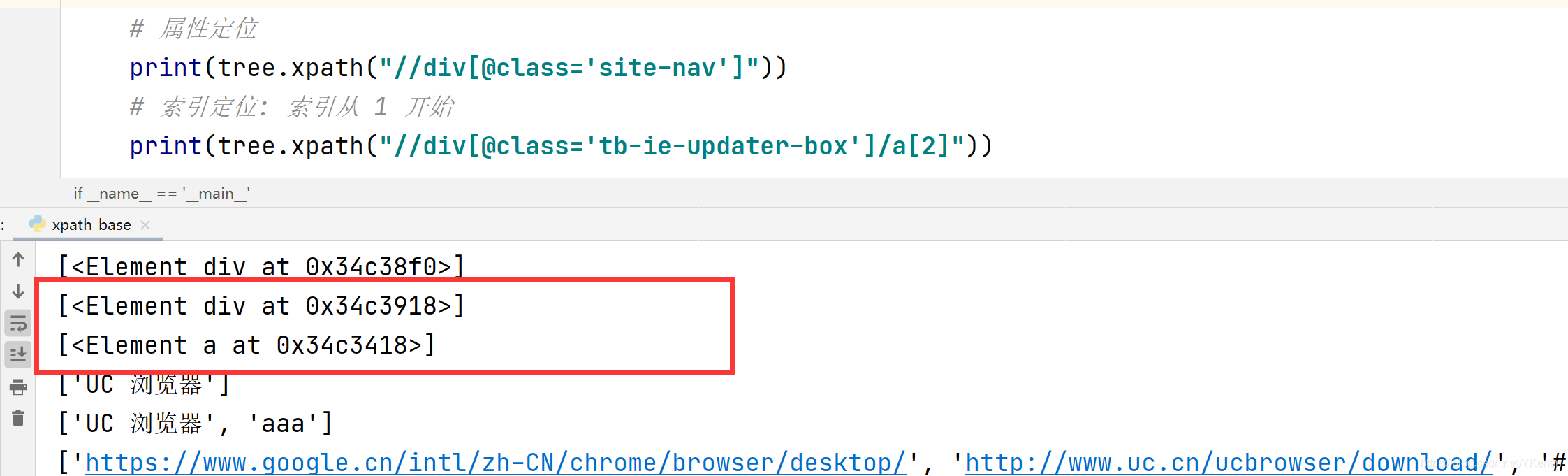
# 属性定位
print(tree.xpath("//div[@class='site-nav']"))
# 索引定位: 索引从 1 开始
print(tree.xpath("//div[@class='tb-ie-updater-box']/a[2]"))
1.4 获取标签中的属性
/text(): 直系内容, 返回 List.
//text(): 所有内容, 返回 List.
/@attribute: 取属性值, 返回 List.
# 取数据 /text(): 直系内容, 返回 List. //text(): 所有内容, 返回 List.
print(tree.xpath("//div[@class='tb-ie-updater-box']/a[2]/text()"))
print(tree.xpath("//div[@class='tb-ie-updater-box']/a[2]//text()"))
# 取属性值
print(tree.xpath("//div[@class='tb-ie-updater-box']/a/@href"))

1.5 通过内容寻找结点
模糊匹配:
[contains(text(),"text")]
精准匹配:[text()="text"]
2. 实例
爬取城市
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
import requests
from lxml import etree
if __name__ == '__main__':
# url, UA
url = "https://www.aqistudy.cn/historydata/"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:84.0) Gecko/20100101 Firefox/84.0"
}
text = requests.get(url=url, headers=headers).text
# 解析
tree = etree.HTML(text, etree.HTMLParser(encoding="utf-8"))
ul = tree.xpath("//div[@class='all']/div[@class='bottom']/ul")
# 建立文件
fp = open("./data/city/city_zm.txt", "w", encoding="utf-8")
# 循环 ul
for ul_zm in ul:
zm = ul_zm.xpath("./div[1]/b/text()")[0]
fp.write(zm + " " + ", ".join(ul_zm.xpath("./div[2]/li/a/text()")) + "\n")
print(zm + " 添加完成")
fp.close()

二手房信息
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
import requests
from lxml import etree
import re
if __name__ == '__main__':
# url, UA
url = "https://bj.58.com/ershoufang/"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:82.0) Gecko/20100101 Firefox/82.0"
}
# 爬取
text = requests.get(url=url, headers=headers).text
# 解析
tree = etree.HTML(text, etree.HTMLParser(encoding="utf-8"))
xpath = tree.xpath("//ul[@class='house-list-wrap']/li")
# 建立文件
fp = open("data/esf/ershoufang.txt", "w", encoding="utf-8")
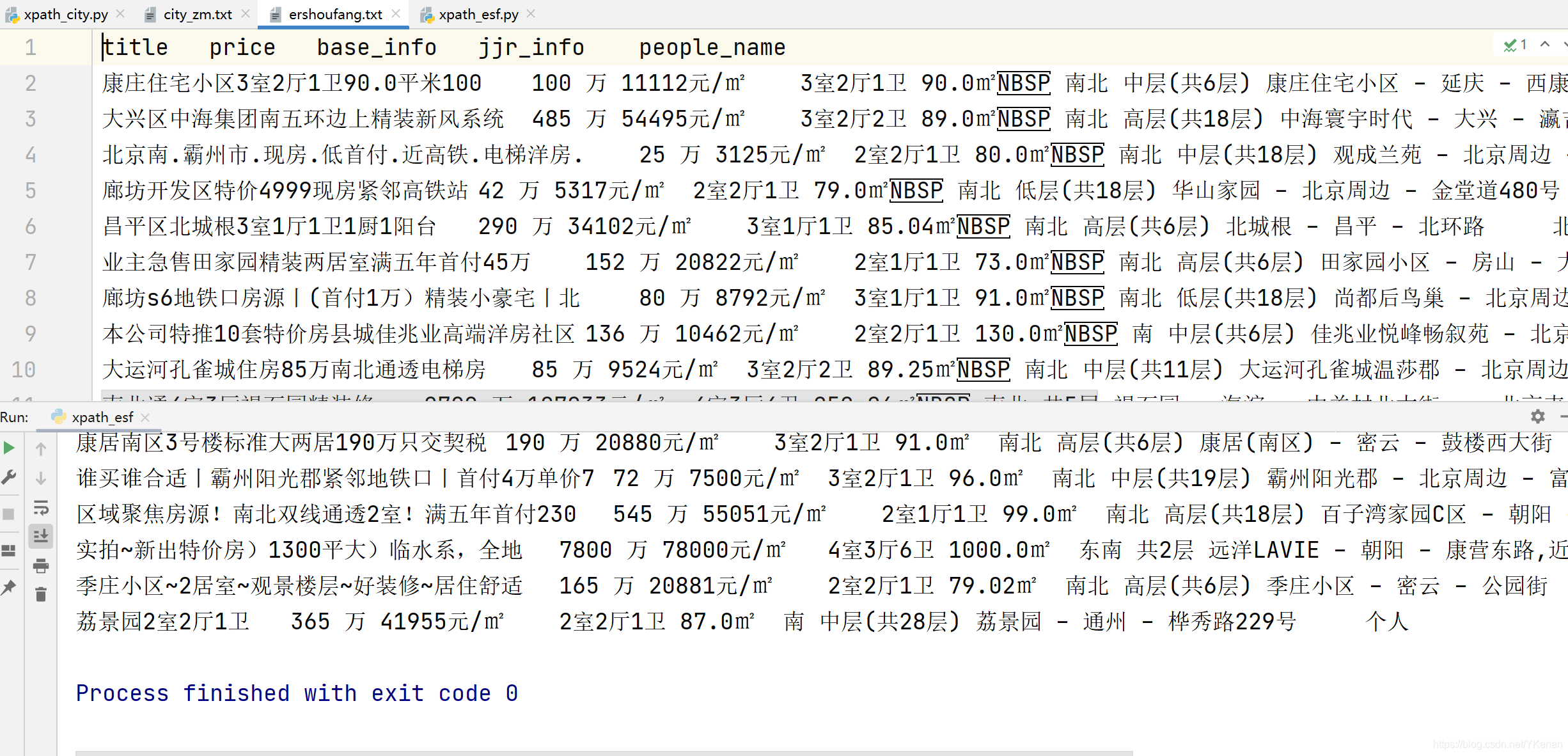
fp.write("title\tprice\tbase_info\tjjr_info\tpeople_name\n")
# 循环二手房的 li 标签
for li_path in xpath:
# 得到相应的内容
title = li_path.xpath("./div[@class='list-info']/h2/a/text()")
price = li_path.xpath("./div[@class='price']/p//text()")
base_info = li_path.xpath("./div[@class='list-info']/p/span//text()")
jjr_info = li_path.xpath("./div[@class='list-info']/div/span[1]/text()")
people_name = li_path.xpath("./div[@class='list-info']/div/a/span/text()")
replace_base_info = re.sub(" +", " ", re.sub("[\t|\n]", "", " ".join(base_info)))
replace_jjr_info = re.sub(" +", " ", re.sub("[\t|\n]", "", " ".join(jjr_info)))
# 写入内容
fp.write(f"{''.join(title[0].split())}\t{' '.join(price)}\t{replace_base_info}\t{replace_jjr_info}\t{' '.join(people_name)}\n")
print(f"{''.join(title[0].split())}\t{' '.join(price)}\t{replace_base_info}\t{replace_jjr_info}\t{' '.join(people_name)}")
fp.close()
爬取美女照片
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
import requests
from lxml import etree
import os
if __name__ == '__main__':
for page in range(1, 172):
# url, UA
# url = page == 1 ? "http://pic.netbian.com/4kmeinv/" : f"http://pic.netbian.com/4kmeinv/index_{page}.html"
url = "http://pic.netbian.com/4kmeinv/" if page == 1 else f"http://pic.netbian.com/4kmeinv/index_{page}.html"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:82.0) Gecko/20100101 Firefox/82.0"
}
# 爬取
response = requests.get(url=url, headers=headers)
# 解决乱码问题
response.encoding = response.apparent_encoding
text = response.text
# 解析
tree = etree.HTML(text, etree.HTMLParser(encoding="utf-8"))
xpath = tree.xpath("//ul[@class='clearfix']/li")
# 建立文件夹
if not os.path.exists("./data/mn/%d" % page):
os.makedirs("./data/mn/%d" % page)
# 循环美女图片的 li 标签
for li_path in xpath:
img_url = "http://pic.netbian.com" + li_path.xpath(".//img/@src")[0]
# 生成图片
with open("./data/mn/%d/%s.jpg" % (page, li_path.xpath(".//img/@alt")[0]), "wb") as f:
f.write(requests.get(url=img_url, headers=headers).content)
print("%d 页下载完成" % page)
