文章目录
正则解析
下载requests库
pip install requests
请求传参之params参数
作用:关键字传参
标准写法如下
import requests
param = {
"kw":"python"
}
res = requests.get("https://www.baidu.com/",params=param)
res
Re解析_正则表达式
练习工具
开源中国中Tool中的正则工具
常用元字符
| 字符 | 作用 |
|---|---|
| . | 通配符,匹配除换行符之外的任意字符 |
| \ | 正则转义 |
| ^ | 匹配字符串的开始位置,在 []中 表示不取字符 |
| $ | 匹配字符串的结束位置 |
| {} | 匹配次数 {n} n表示0到+∞,自定义匹配次数 |
| * | 匹配 0 次或 多次 |
| + | 匹配 1 次或 多次 |
| ? | 匹配 0 次或 1 次 |
| [] | 字符集合 数字集合:[^0-9] 英文字符集合:[^a-z] [A-Z] |
| () | 分组匹配 |
| | | 或运算 分支条件 |
转义字符
\s 空白符
\S
\w 大小写数字下划线
\W
\n 换行符
\d 数字
\D
量词
作用: 控制元字符出现的次数
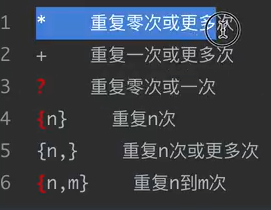
贪婪模式和非贪婪模式
贪婪模式下最长匹配
非贪婪模式最短匹配扫描二维码关注公众号,回复: 17207211 查看本文章
- 案例
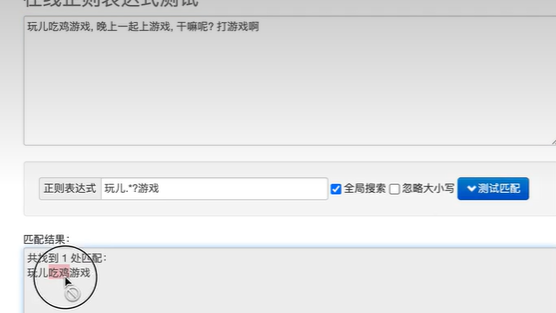
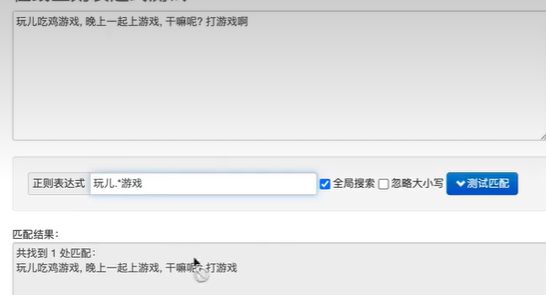
正则匹配的限制
正则表达式中*和{}无法一起使用,否则报一下错误

单次匹配和多次匹配
re.search()–>匹配一次
re.findall()–>匹配多次
实战–天堂电影
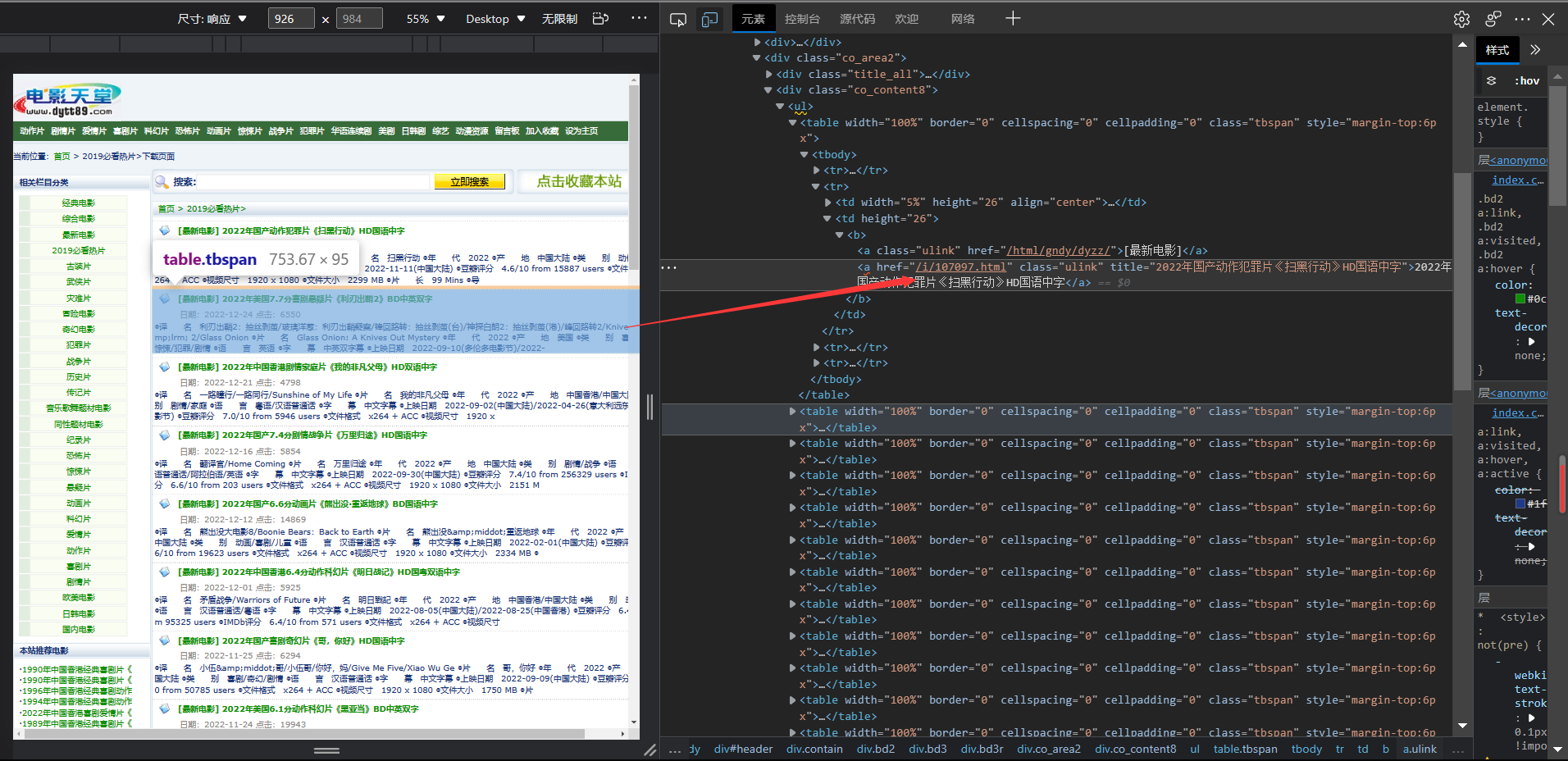
- 抓包—>以2023必看热片为例
- 找到元素位置
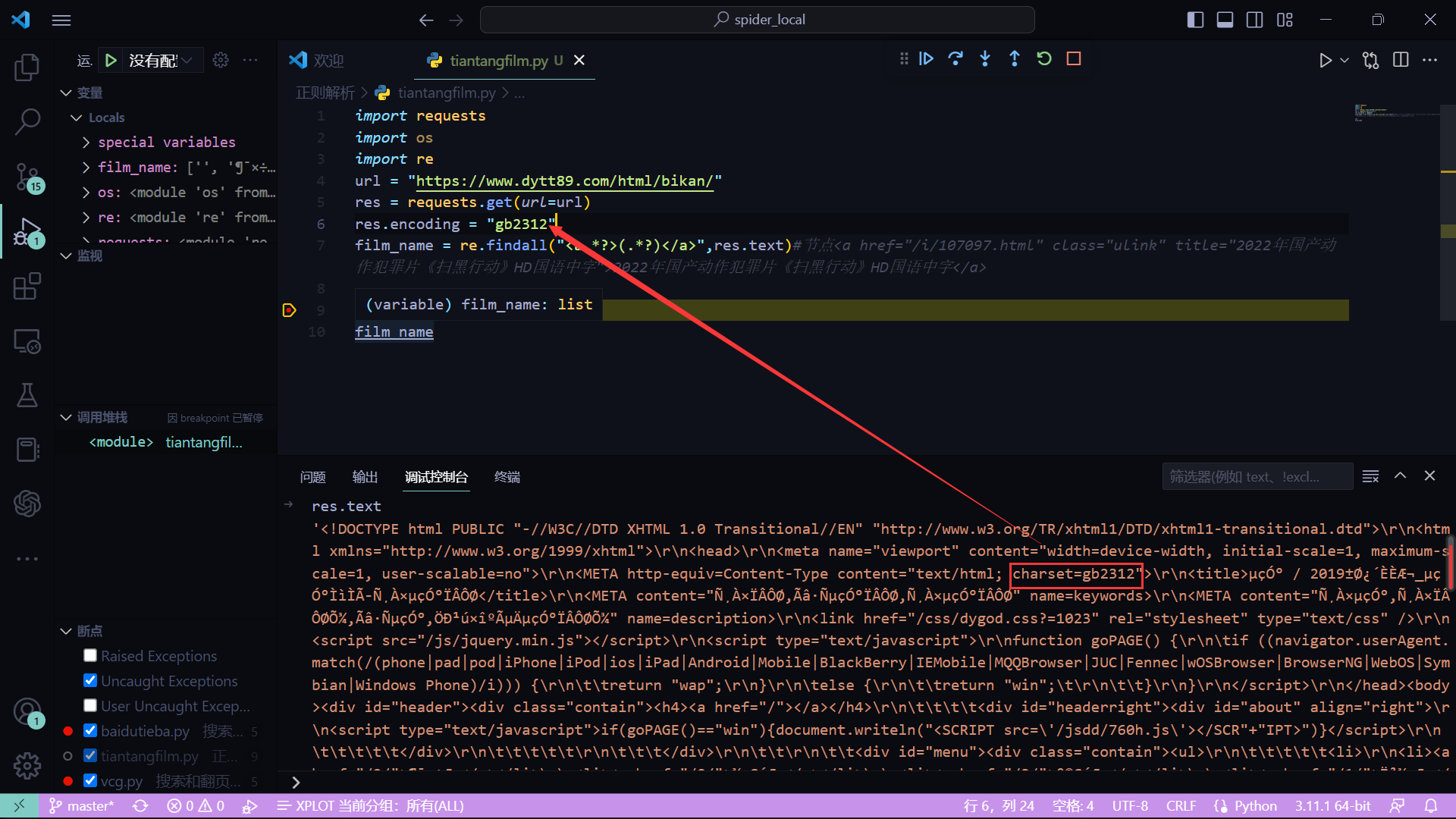
- 注意编码
import requests
import os
import re
url = "https://www.dytt89.com/html/bikan/"
res = requests.get(url=url)
res.encoding = "gb2312"
film_name = re.findall("<a href.*?>(.*?)</a>",res.text)#节点<a href="/i/107097.html" class="ulink" title="2022年国产动作犯罪片《扫黑行动》HD国语中字">2022年国产动作犯罪片《扫黑行动》HD国语中字</a>
film_href = re.findall("<a (href=.*?).html",res.text)
data = {
}
i = 0
for every_name in film_name:
data[every_name]=film_href[i]
i+=1
data
data
实战–百度文库
-
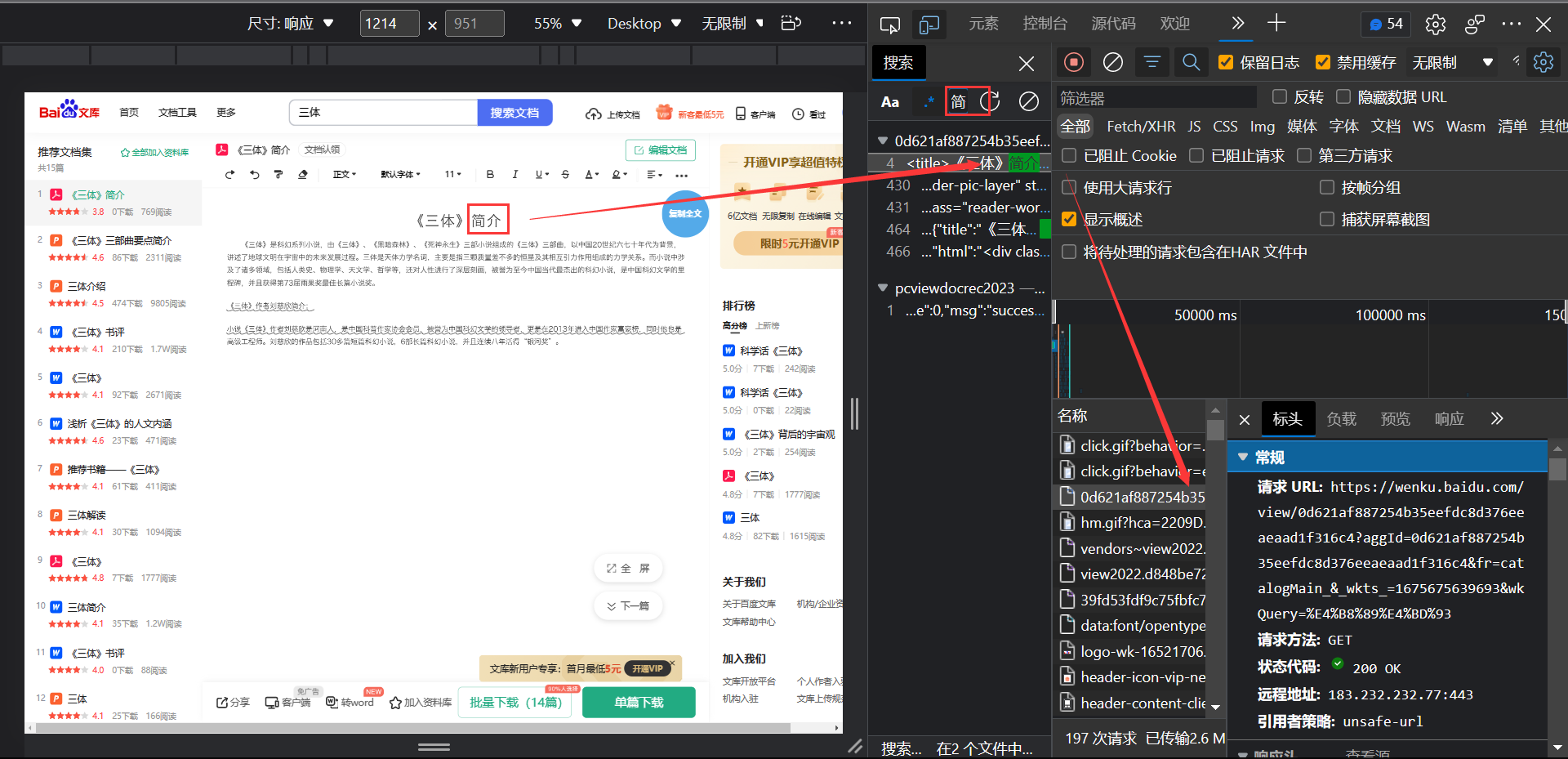
抓包
-
存储响应内容到vscode(新建一个index.html)–>右键格式化文档–>
ctrl+k+ctrl+0折叠文档 -
清洗一下响应数据(包括css和javascrip)—>只留html相关
-
-
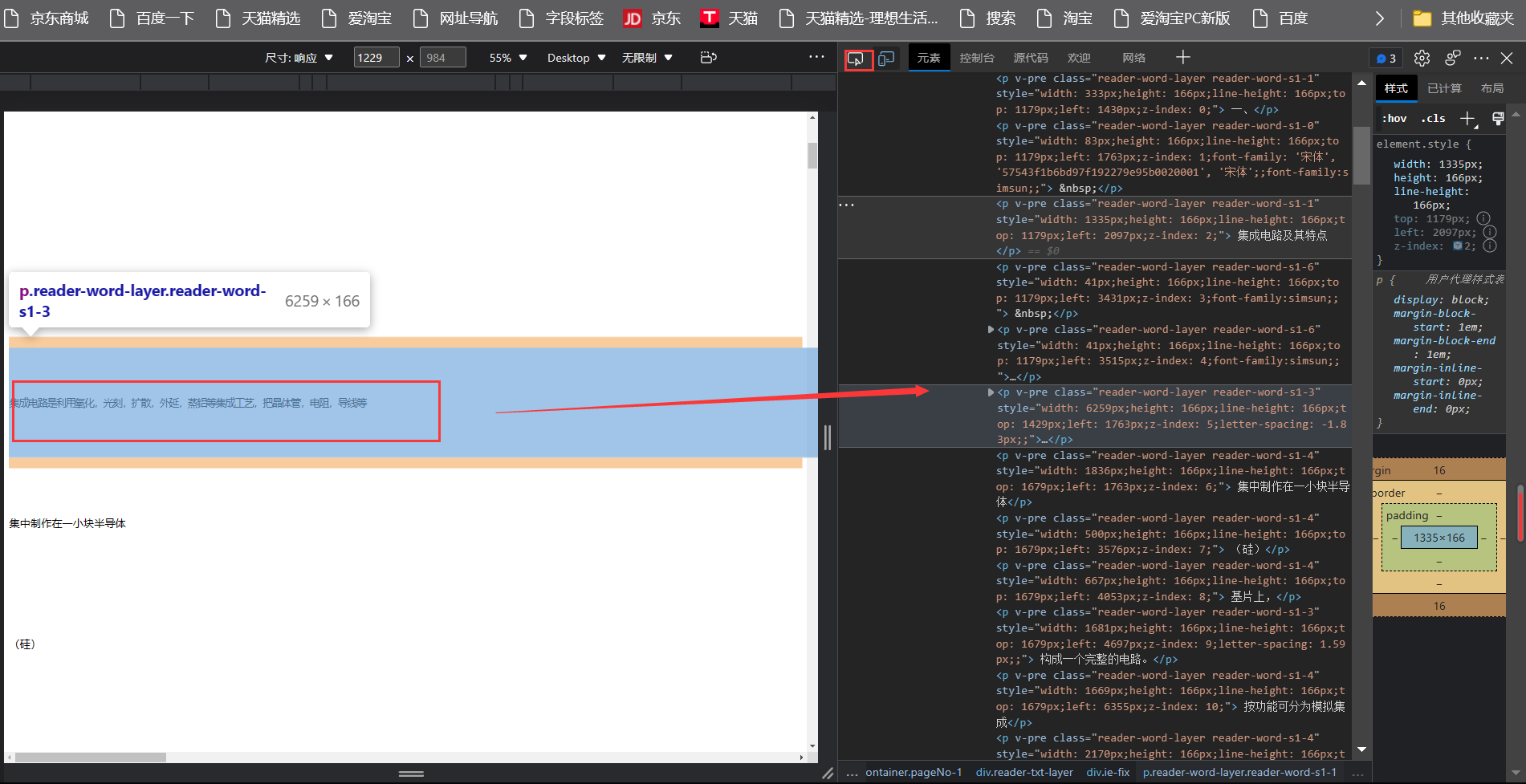
通过元素定位按钮找到文字所在位置
-
-
代码示例如下 -
import requests import os import re url = "https://wenku.baidu.com/view/57543f1b6bd97f192279e95b.html?fr=income1-doc-search&_wkts_=1675677743981&wkQuery=%E9%9B%86%E6%88%90%E7%94%B5%E8%B7%AF" dir_name = os.path.dirname(__file__) res = requests.get(url=url) index_html = os.path.join(dir_name,"集成电路.html") with open(index_html,mode="w") as f: f.write(res.text) data = re.findall("<p.*?>(.*?)</p>",res.text) data = ''.join(data) data data = re.sub(' ','',data)#将空白符替换为空 data = re.sub(r'\\n',r"\n",data) data_txt = os.path.join(dir_name,"集成电路.txt") with open(data_txt,mode="w") as f: f.write(data)