案例一:解析出全国所有城市名称
代码如下:
import requests
from lxml import etree
if __name__ == "__main__":
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'
}
url = 'https://www.aqistudy.cn/historydata/'
page_text = requests.get(url=url, headers=headers).text
tree = etree.HTML(page_text)
#解析到热门城市和所有城市对应的a标签
# //div[@class="bottom"]/ul/li/ 热门城市a标签的层级关系
# //div[@class="bottom"]/ul/div[2]/li/a 全部城市a标签的层级关系
a_list = tree.xpath('//div[@class="bottom"]/ul/li/a | //div[@class="bottom"]/ul/div[2]/li/a')
all_city_names = []
for a in a_list:
city_name = a.xpath('./text()')[0]
all_city_names.append(city_name)
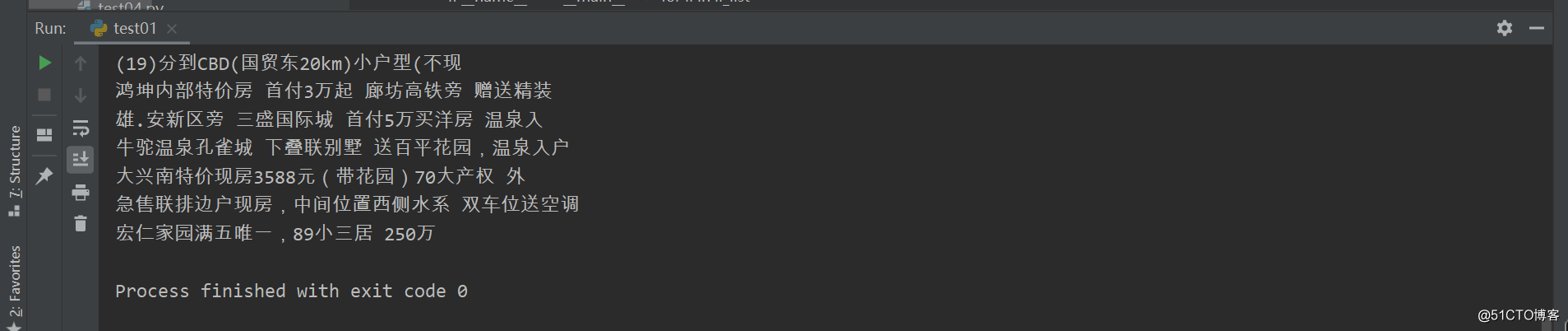
print(all_city_names,len(all_city_names))
运行效果:

案例二:爬取58二手房中的房源信息
代码如下:
import requests
from lxml import etree
if __name__ == "__main__":
headers = {
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'
}
#爬取到页面源码数据
url = 'https://bj.58.com/ershoufang/'
page_text = requests.get(url=url,headers=headers).text
#数据解析
tree = etree.HTML(page_text)
#存储的就是li标签对象
li_list = tree.xpath('//ul[@class="house-list-wrap"]/li')
fp = open('58.txt','w',encoding='utf-8')
for li in li_list:
#局部解析
title = li.xpath('./div[2]/h2/a/text()')[0]
print(title)
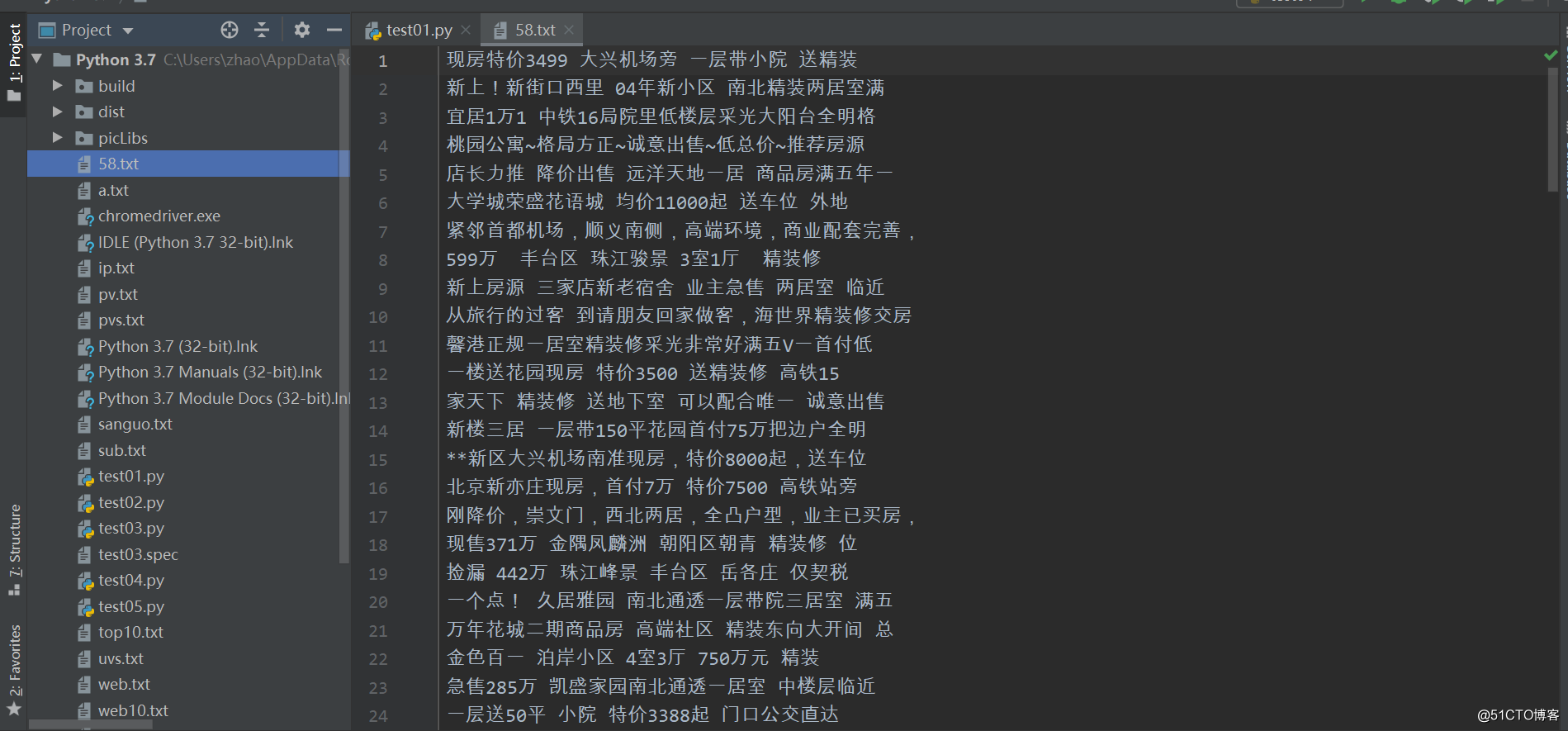
fp.write(title+'\n')
运行效果: