版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/fanfan4569/article/details/81749118
逻辑回归的类及默认参数:
LogisticRegression(penalty='l2', dual=False, tol=0.0001, C=1.0, fit_intercept=True,
intercept_scaling=1, class_weight=None, random_state=None, solver='liblinear', max_iter=100,
multi_class='ovr', verbose=0, warm_start=False, n_jobs=1)介绍其中几个常用的参数,其余使用默认即可:
penalty: 惩罚项,默认为 范数。dual: 对偶化,默认为 False。tol: 数据解算精度。fit_intercept: 默认为 True,计算截距项。random_state: 随机数发生器。max_iter: 最大迭代次数,默认为 100。
另外,solver 参数用于指定求解损失函数的方法。默认为 liblinear,适合于小数据集。除此之外,还有适合多分类问题的 newton-cg, sag, saga 和 lbfgs 求解器。这些方法都来自于一些学术论文,有兴趣可以自行搜索了解。
(1)加载数据
import pandas as pd
from matplotlib import pyplot as plt
import numpy as np
from sklearn.linear_model import LogisticRegression
# !wget http://labfile.oss.aliyuncs.com/courses/1081/course-8-data.csv
df = pd.read_csv("course-8-data.csv", header=0) # 加载数据集
df.head()
x = df[['X0','X1']].values
y = df['Y'].values(2)实现
model = LogisticRegression(tol=0.001, max_iter=10000) # 设置一样的学习率和迭代次数
model.fit(x, y)
model.coef_, model.intercept_
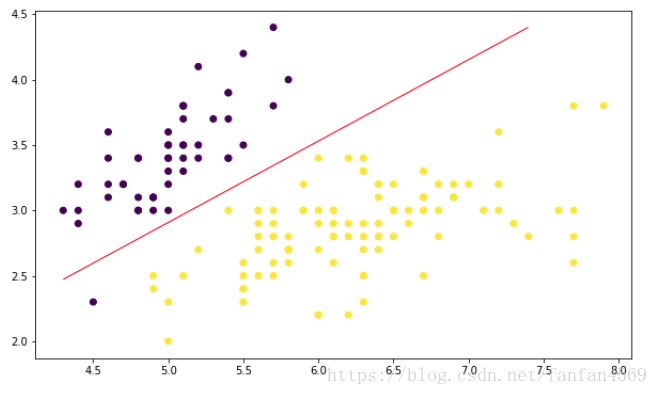
"""将上方得到的结果绘制成图
"""
plt.figure(figsize=(10, 6))
plt.scatter(df['X0'],df['X1'], c=df['Y'])
x1_min, x1_max = df['X0'].min(), df['X0'].max(),
x2_min, x2_max = df['X1'].min(), df['X1'].max(),
xx1, xx2 = np.meshgrid(np.linspace(x1_min, x1_max), np.linspace(x2_min, x2_max))
grid = np.c_[xx1.ravel(), xx2.ravel()]
probs = (np.dot(grid, model.coef_.T) + model.intercept_).reshape(xx1.shape)
plt.contour(xx1, xx2, probs, levels=[0], linewidths=1, colors='red');
model.score(x, y)