Topic:
- LASSO 回归 的 几何意义
- LASSO 代码
- LASSO 的 正则项 与 岭回归 的 有什么不同?
一、LASSO回归的几何意义
与岭回归相似,LASSO 回归优化的目标函数也等价于:
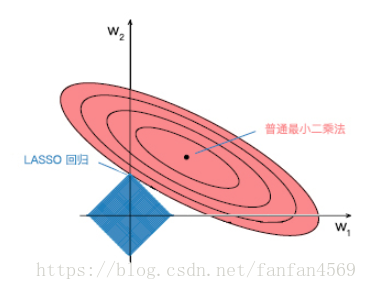
其中, 是 对于的一个常数,这里通过限制 的大小来避免过拟合的发生。所以,假设我们有 2 个变量, 残差平方和 是一个二次函数,代表三维空间中的抛物面,几何上用等值线表示(下图红色)。
当抛物面受到 约束条件时,就相当于在二维平面下的矩形(下图蓝色)。这个时候等值线与矩形定点相切的点便是在约束条件下的最优点,如下图所示。
二、LASSO 代码
LASSO 回归通过添加正则项来改进普通的最小二乘法,这里添加的是 正则项。
同样通过 scikit-learn 提供的 LASSO 回归方法 Lasso() 来进行数据拟合。
sklearn.linear_model.Lasso(alpha=1.0, fit_intercept=True, normalize=False, precompute=False,
copy_X=True, max_iter=1000, tol=0.0001, warm_start=False, positive=False, random_state=None, selection='cyclic')alpha: 正则化强度,默认为 1.0。fit_intercept: 默认为 True,计算截距项。normalize: 默认为 False,不针对数据进行标准化处理。precompute: 是否使用预先计算的 Gram 矩阵来加速计算。copy_X: 默认为 True,即使用数据的副本进行操作,防止影响原数据。max_iter: 最大迭代次数,默认为 1000。tol: 数据解算精度。warm_start: 重用先前调用的解决方案以适合初始化。positive: 强制系数为正值。random_state: 随机数发生器。selection: 每次迭代都会更新一个随机系数。
"""使用 LASSO 回归拟合并绘图
"""
from sklearn.linear_model import Lasso
alphas = np.linspace(-2,2,10)
lasso_coefs = []
for a in alphas:
lasso = Lasso(alpha=a, fit_intercept=False)
lasso.fit(x, y)
lasso_coefs.append(lasso.coef_)
plt.plot(alphas, lasso_coefs) # 绘制不同 alpha 参数下的 w 拟合值
plt.scatter(np.linspace(0,0,10), parameters[0]) # 普通最小二乘法拟合的 w 值放入图中
plt.xlabel('alpha')
plt.ylabel('w')
plt.title('Lasso Regression')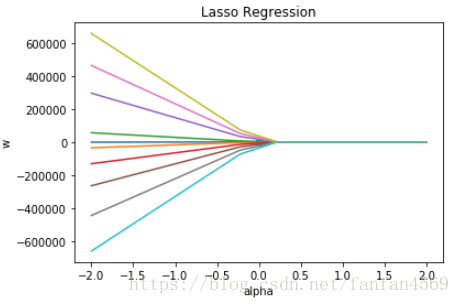
三、LASSO 的 正则项 与 岭回归 的 有什么不同?
当我们使用普通最小二乘法进行回归拟合时,如果特征变量间的相关性较强,则可能会导致某些
w系数很大,而另一些系数变成很小的负数。岭回归添加 正则项来解决这个问题,LASSO 回归 添加的是 正则项
emmmm, 这块先 block 吧,功力不够啊~