1.bouding box regression总结:
rcnn使用l2-loss
首先明确l2-loss的计算规则:
L∗=(f∗(P)−G∗)2,∗代表x,y,w,h
整个loss : L=Lx+Ly+Lw+Lh
也就是说,按照l2-loss的公式分别计算x,y,w,h的loss,然后把4个loss相加就得到总的bouding box regression的loss。这样的loss是直接预测bbox的
绝对坐标与绝对长宽。
改进1:
问题:如果直接使用上面的l2-loss,loss的大小会收到图片的大小影响。
解决方案:loss上进行规范化(normalization)处理。
Lx=(fx(P)−Gx)W)2,Ly=(fy(P)−Gy)H)2,Lw=(fw(P)−Gw)W)2,Lh=(fh(P)−Gh)H)2,其中, W,H分别为输入图片的宽与高
这种改进没有被采纳
改进2:
rcnn直接使用的是下面这个公式,也使用了规范化,但除以的是proposal的wh,并且wh的loss用的log函数
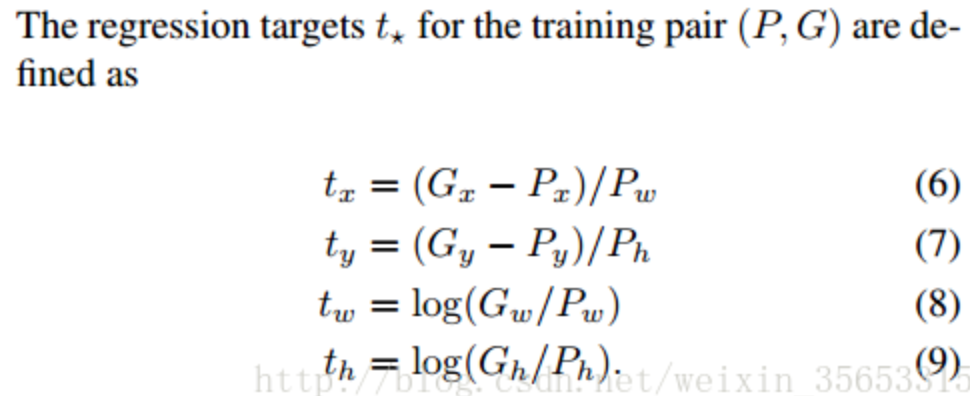
cascade论文说这个改进的目的是:“To encourage a regression invariant to scale and location”,也就是增加scale和location的不变性
位置不变性:delta_x = [(g_x + a) - (b_x + a)] / b_w。不管平移量a是多少,delta_x都是一样的
尺寸不变性:delta_w = log((g_w * b) / (b_w * b))。不管图片缩放b是多少,delta_w都是一样的
至于为什么用log,有个博客说是:是为了降低w,hw,h产生的loss的数量级, 让它在loss里占的比重小些。 这个解释还有待观察
改进3:
问题:当预测值与目标值相差很大时, 梯度容易爆炸, 因为梯度里包含了x−t
解决方案:smoothl1代替l2-loss,当差值太大时, 原先L2梯度里的x−t被替换成了±1, 这样就避免了梯度爆炸
改进4:
问题:由于bouding box regression经常只在proposal上做微小的改变,导致bouding box regression的loss比较小,所以bouding box regression的loss一般比classification
的loss小很多。(整个loss是一个multi-task learning,也就是分类和回归)
解决方案:标准化

2.
https://blog.csdn.net/weixin_35653315/article/details/54571681