模式识别课程中已经学习了EM算法和高斯混合模型,但是听课的时候感觉十分茫然,课程中乃至的概率论等内容和数学中的内容有些脱节,直接套用数学中的内容甚至会导致前后矛盾。课后反复研究之后,发现是不正规的甚至是错误的数学语言的使用导致的公式晦涩难懂。因此在此做一些笔记,努力让公式简单一些。
高斯混合模型
从一个例子说起。
一片树林中有A、B、C三种树木,每种树木的叶子的面积与最大宽度分别服从联合高斯分布(具体参数未知)。如何通过收集一定量的树叶(不知道这些树叶属于哪种树木),试对这些树叶进行分类,并估算出三种树木的联合高斯分布的参数。
首先要对这个例子进行数学描述。每个叶子可以用一个二维向量表示:
例如,以下Mathematica代码实现了500个示例数据的生成(三种树木的概率分别为0.2,0.3,0.5):

图1
Mathematica代码,用于生成高斯混合模型的示例数据。
效果如图2所示:
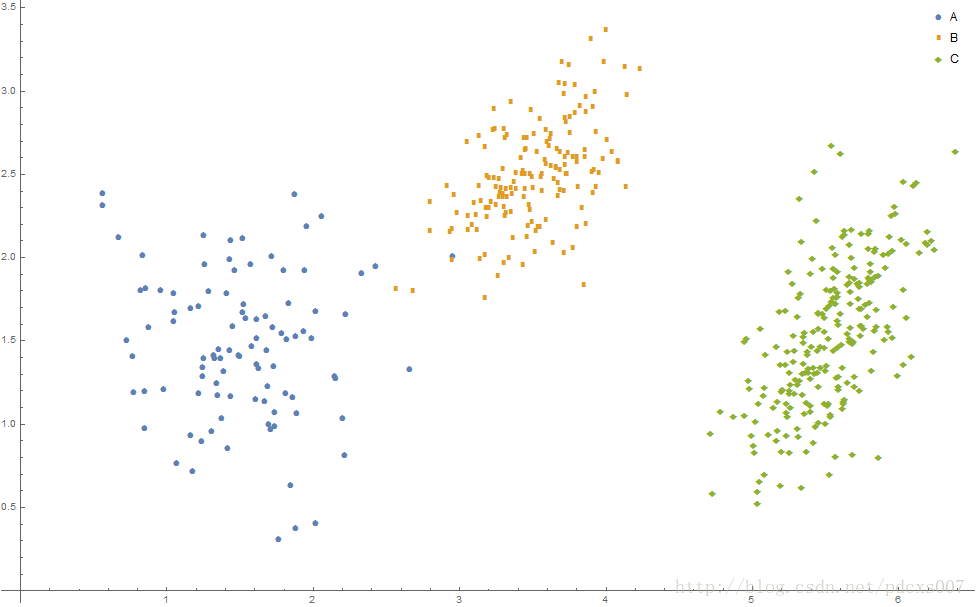
图2 高斯混合模型示例数据
在了解了实际例子后,展示一下“官方”的高斯混合模型的定义,并指明其含混和错误的地方。
Suppose that we are given a training set
{x(1),…,x(m)} as usual. Since we are in the unsupervised learning setting, these points do net come with any labels.We wish to model the data by specifying a joint distribution
p(x(i),z(i))=p(x(i)|z(i))p(z(i)) . Here,z(i)∼Multinomial(ϕ) , (whereϕj≥0,∑kj=1ϕj=1 , and parameterϕj givesp(z(i)=j) ,) andx(i)|z(i)∼N(μj,Σj) . We letk denote the number of values that thez(i) ’s can take on. Thus our model posits that eachx(i) was generated by randomly choosingz(i) from{1,…,k} , and thenx(i) was drawn from one ofk Gaussians depending onz(i) . This is called the mixture of Gaussians model.
大体一看会有很多难以理解的地方,这里做一下说明。首先,训练集用的是小写字体加目标的形式,不符合常理。且不加粗会误认为是标题,因此改用上文的方式,训练集记为:
“官方文档”中的
式中,
由此,可以注意到,多项式分布的变量显然是一个
zi∼Multinomial(1,ϕ) ,其中,ϕ=(ϕi1,…,ϕik) ,其中的ϕj 代表xi 属于第j 类(即z(i)=j )的概率。此时,显然有∑kj=1ϕj=1
当
另外,对于某个具体分类的数据,都服从联合高斯分布(因为数据一般是多维的)。这就是混合高斯模型了:有若干个分类,每一类都服从联合高斯分布,每次实验数据都是这些实验的结果,服从
Jensen’s Inequality
在介绍Jensen不等式之前,先要说明一下凸函数。凸函数的数学定义为,函数
注意,凸函数的图像在直观的印象中是“凹”的,如下图:
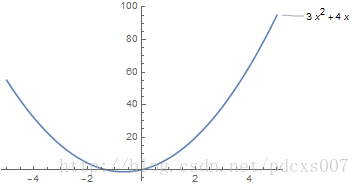
图3 凸函数是“凹”的。
以上式子很容易的可以推广:
推广思路展示由2到3的推广,可以用归纳法得到一般情形。
式
注意,
EM算法
现在的问题是,我们抽取到一堆叶子的数据,但是不知道这些抽取到的叶子分别属于哪种树木,同时也不知道各个树木树叶的面积与最大宽度的统计规律(只知道服从什么分布,如高斯分布,但不知道该分布的具体参数)。那么可以将每个叶子自动分类,并对各种树木的叶子的分布参数作出估计吗?
乍一听是很难完成的任务,如此多的未知量,如何进行估计?EM算法便是解决这样的问题。首先,假定数据各个类别的参数都已经知道,记为
要分析这个概率的最大值,需要进行求导操作,而多个变量连乘的导数特别复杂,因此对这个连乘进行取对数运算,将乘法变换为加法,基于这种思路定义了Likelihood函数:
具体求
此时,对数函数内求和又使得问题变得非常复杂,因此,利用上文提到的Jensen不等式,注意这里是凹函数,不等号方向要改变。但是还不能直接使用,需要再做如下变形:
可以将
在上面的变换中,有一个不好理解的地方。我们将
注意,现在的假设是
又因为
即,第
在确定了
EM算法描述如下:
重复直到收敛 {
(E-Step) 对于每个观测值
xi ,令
p(z(i)=j):=p(z(i)=j|xi;θ),j=1,…,k (M-Step) 令
θ:=argmaxθ∑i=1m∑j=1kp(z(i)=j)lnp(xi,z(i)=j;θ)p(z(i)=j) }
注意在重复开始前需要给
EM算法能够保证收敛吗?假设
且有:
上式中的第一个不等式是因为E-Step对于
混合高斯模型的EM算法
代入混合高斯模型后,EM算法中的计算公式都可以具体化。
E-Step是比较容易的,直接可以计算得到:
在M-Step中,将
对
又疏于
同理,对于
实现
初始值设置为:
Mathematica代码实现如下 :

源代码为:
Clear["`*"];
m = 1000;
\[Mu] = {{1.5, 1.5}, {3.5, 2.5}, {5.5, 1.5}};
\[Sigma] = {({
{0.2, 0},
{0, 0.2}
}), ({
{0.1, 0.05},
{0.05, 0.1}
}), ({
{0.1, 0.08},
{0.08, 0.2}
})};
z = Table[t = RandomReal[]; Which[t < 0.2, 1, t < 0.5, 2, True, 3], m];
x = Table[
RandomVariate[
MultinormalDistribution[\[Mu][[z[[i]]]], \[Sigma][[z[[i]]]]]], {i,
m}];
ListPlot[{Pick[x, z, 1], Pick[x, z, 2], Pick[x, z, 3]},
PlotLegends -> Placed[{"A", "B", "C"}, {Right, Top}],
PlotMarkers -> Automatic]
guessPhi = {0.3, 0.3, 0.4};
guessMu = {{0, 0}, {1, 0}, {0, 1}};
guessSigma = {({
{1, 0},
{0, 1}
}), ({
{1, 0},
{0, 1}
}), ({
{1, 0},
{0, 1}
})};
t = 1;
While[True,
w = Table[Table[N@
guessPhi[[j]] PDF[
MultinormalDistribution[guessMu[[j]], guessSigma[[j]]],
x[[i]]]/Sum[
guessPhi[[j]] PDF[
MultinormalDistribution[guessMu[[j]], guessSigma[[j]]],
x[[i]]], {j, 1, 3}], {j, 1, 3}], {i, 1, m}];
updateGuessMu =
Table[Sum[w[[i, j]] x[[i]], {i, 1, m}], {j, 1, 3}]/Total[w];
updateGuessPhi = Total[w]/m;
updateGuessSigma =
Table[Sum[
w[[i, j]] Outer[Times, x[[i]] - updateGuessMu[[j]],
x[[i]] - updateGuessMu[[j]]]/Total[w[[All, j]]], {i, 1,
m}], {j, 1, 3}];
(*Print[t,updateGuessMu,updateGuessPhi,updateGuessSigma];*)
If[Fold[And, Thread[Flatten[updateGuessMu - guessMu] < 0.001]] &&
Fold[And, Thread[Flatten[updateGuessPhi - guessPhi] < 0.001]] &&
Fold[And,
Thread[Flatten[updateGuessSigma - guessSigma] < 0.001]], Break[]];
guessMu = updateGuessMu;
guessPhi = updateGuessPhi;
guessSigma = updateGuessSigma;
t = t + 1;
];
guessZ = Flatten@Table[Position[w[[i]], Max[w[[i]]]], {i, m}];
ListPlot[{Pick[x, guessZ, 1], Pick[x, guessZ, 2], Pick[x, guessZ, 3]},
PlotLegends ->
Placed[{"Auto Class A", "Auto Class B", "Auto Class C"}, {Right,
Top}], PlotMarkers -> Automatic]
updateGuessMu
updateGuessPhi
Map[MatrixForm, updateGuessSigma, 1]原始数据图像:
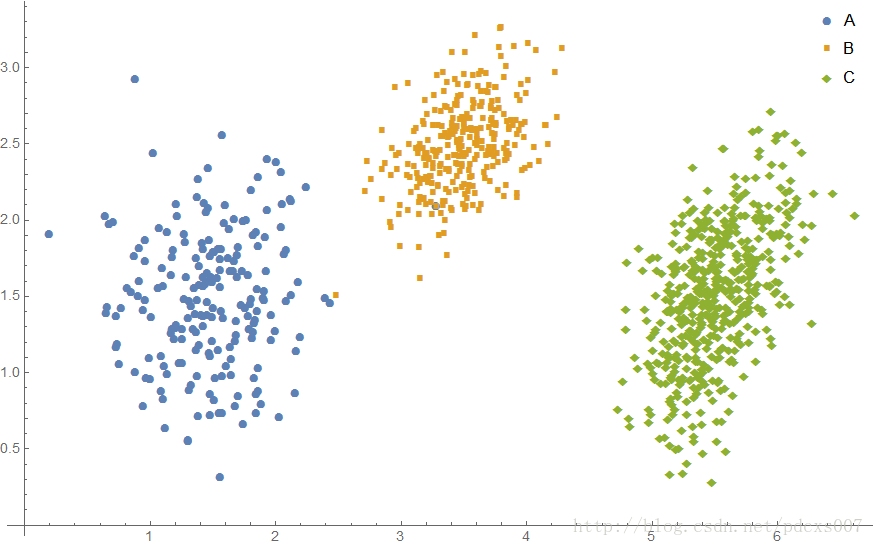
学习到的分类图像:
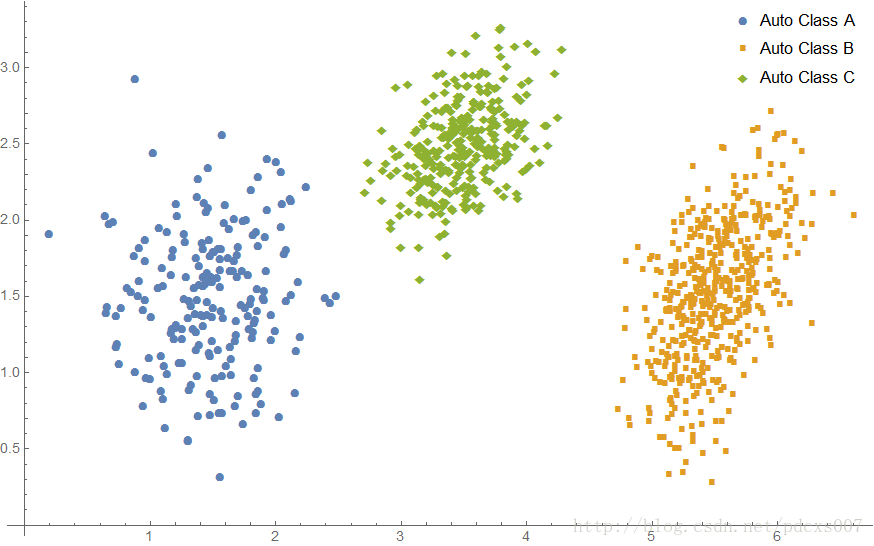
学习到的参数及原参数的对比:

注意,由于算法自动分类,类型B和类型C是反着的,不过不影响算法的使用。
以上就是EM算法与高斯混合模型的笔记啦。