版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/Hemk340200600/article/details/86498601
1.高斯混合模型(GMM)
极大似然估计是一种应用很广泛的参数估计方法。在已有某个地区身高数据以及知道身高服从高斯分布的情况下,利用极大似然估计的方法可以估计出高斯分布
μ,σ两个参数。
如果是多组数据,多个模型呢?获取现在我们有全国多个省份的身高数据,但并不知道它们具体属于哪个省份,只知道每个省之间服从不同的高斯分布,此时的模型称为高斯混合模型(GMM),其公式为
P(x;θ)=i=1∑kαkϕ(x;θk)..........(1)
此时用极大似然估计的方法并不能很好地求出模型里面的参数,因为模型中存在一个隐变量——样本的label。令其为Z,则可以写出似然函数的形式:
L(θ)=i=1∑mlogp(xi;θ)=i=1∑mlogZ∑p(xi,Z;θ)..........(2)
如果根据极大似然估计的算法对式子(2)进行求导,意味着我们要对
log(x1+x2+...)的形式进行求导,这计算量简直爆炸。
2.Jensen不等式
这里我们需要用到EM算法来进行求解,在介绍EM算法前,我们先来了解一个不等式——Jensen不等式,它的定义如下:
如果X是一个随机变量,f(X)是一个凸函数(二阶导数大或等于0),那么有:
E(f(x))≥f[E(x)]
如果f(X)是凹函数,不等号反向
E(f(x))≤f[E(x)]
当且仅当X是常数的时候等号成立。
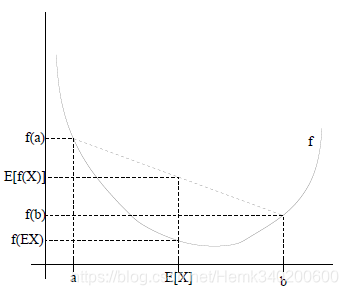
结合图像我们可以对Jensen不等式有一个直观的理解,对于x=a和x=b两个点,E(f(x))可以看成是
21(f(a)+f(b)),f[E(x)]可以看成是
f(21(f(a)+f(b))),即ab中点对应的函数值。由于图像是凹图像,所以不难得出
E(f(x))≥f[E(x)]。
3.EM算法及推导过程
利用Jensen不等式,由于log函数是凹函数,式子(2)可以改写成:
i=1∑mlogZ∑p(xi,Z;θ)=i=1∑mlogzi∑Q(z)Q(z)P(xi,z;θ)≥i=1∑mzi∑Q(z)logQ(z)P(xi,z;θ)..........(3)
由于
Q(z)是概率分布,所以满足
z∑Q(z)=1..........(4)
根据Jenson不等式,等式成立时,有
Q(z)p(xi,z;θ)=C..........(5)
根据4和5,有
zi∑Q(z)=zi∑Cp(xi,z;θ)=1..........(6)Q(z)=Cp(xi,z;θ)=∑zp(xi,z;θ)p(xi,z;θ)=p(xi)p(xi,z;θ)=p(z∣xi;θ)..........(7)
因此,EM算法的流程如下:
- 初始化参数θ
- E-Step:根据
Q(z)=p(z∣xi;θ)计算每个样本属于zi的概率。
- M-Step:根据计算得到的Q,得到含有θ的似然函数
L(θ,θˉ)=i=1∑mz(i)∑Q(z(i))logP(x(i),z(i);θ)的下界并最大化它,得到新的参数θ
- 重复2和3直至收敛
为什么EM算法能保证收敛呢?要证明EM算法收敛,则我们需要证明我们的对数似然函数的值在迭代的过程中一直在增大。假设当前迭代到第i轮,参数为
θi,希望新估计值
θ可以使
L(θ)增大,即
L(θ)>L(θi),则:
L(θ)−L(θi)=log(Z∑p(x∣z,θ)p(z∣θ))−log(p(x∣θi))=logZ∑p(z∣x,θi)p(z∣x,θi)p(x∣z,θ)p(z∣θ)−log(p(x∣θi))≥Z∑p(z∣x,θi)logp(z∣x,θi)p(x∣z,θ)p(z∣θ)−log(p(x∣θi))=Z∑p(z∣x,θi)logp(z∣x,θi)(p(x∣θi)p(x∣z,θ)p(z∣θ)
令
H(θ,θi)=L(θi)+Z∑p(z∣x,θi)logp(z∣x,θi)(p(x∣θi)p(x∣z,θ)p(z∣θ)
则有
L(θ)≥H(θ,θi),因此可以认为
H(θ,θi)为
L(θ)的一个下界,且有
L(θi)=H(θi,θi),为了使
L(θ)尽可能地变大,我们解以下式子:
argθmaxH(θ,θi)=argθmaxL(θi)+Z∑p(z∣x,θi)logp(z∣x,θi)(p(x∣θi)p(x∣z,θ)p(z∣θ)=argθmaxZ∑p(z∣x,θi)log(p(x∣z,θ)p(z∣θ))=argθmaxZ∑p(z∣x,θi)p(x∣z,θ)p(z∣θ)=argθmaxZ∑p(z∣x,θi)p(x,z∣θ)
而这正是E-step中我们所做的工作,由此可证EM算法确实是可以收敛的。由于采用迭代的方式进行求解,EM算法可以保证收敛到一个稳定点,但是却不能保证收敛到全局的极大值点,因此它是局部最优的算法,当然,如果我们的优化目标
H(θ,θi)是凸的,则EM算法可以保证收敛到全局最大值,这点和梯度下降法这样的迭代算法相同。