对于知识图谱的关注可以分为两个方面:知识图谱的构建和基于知识图谱数据结构的应用。知识图谱的构建主要关注如何整合结构化、非结构化的数据,实现用统一的语义数据结构如三元组RDF形式的数据存储。基于知识图谱的应用主要关注如何从这种语义数据结构中挖掘、发现、推演出相关的隐藏知识或新知识或者实现更上层的应用如搜索、问答、决策、推荐等,具体可以参考《三个角度理解知识图谱》。本文主要讲一下基于知识图谱推理的关系推演(或者叫做关系预测),主要包括如下几个方面:
1、知识图谱推理的主要作用;
2、知识图谱推理的基本原理;
3、知识图谱推理的主要方法;
4、TransE算法理解
1、知识图谱推理的主要作用
针对知识图谱分析系统,需要考虑哪些具体场景能用到推理算法,根据目前了解,大致可以分为如下的几种情况:
- 大量数据表到知识图谱转化的时候,有部分数据是没有直接关联的,需要通过推理算法来进行类别标注/关系连接补全;
- 加载业务模型时,可以使用一些业务规则(或逻辑规则)进行推理,这些业务规则可以是常用人机交互流程的固化 ,也可以是用户编辑的业务规则;
- 使用分布式表示学习方法时,可以利用表示学习后向量做一些更高层次的应用,比如计算相似度来做搜索、推荐或输入其它机器学习算法中去,完成相关的分类、聚类、推荐等;
2、知识图谱推理的基本原理
知识图谱推理根据是否与业务相关,主要可以分为基于规则的推理和基于算法的推理。
(1)基于规则的推理
主要是通过业务本体框架中的相关约束来做相关的推理,比如类别推理、属性推理等。
- 想知道实体类别,而没有直接给出-----类别推理;
由底层类向高层类的推理(是底层类,则必是高层类)

- 通过关系的定义域和值域来推理(关系的定义域和值域是固定的,实例具有这种关系,则实例就是定义域或值域规定的类别)

(2)基于算法的推理
基于算法的推理可以分为很多种,基于路径的建模、分布式表示学习、基于神经网络、混合推理等,但推理算法获得的结果具有不确定性,不一定等获得完全正确的关系,只是一种预测可能性。比如:通过观察到知识图谱中包含这样的一条路径“梅琳达·盖茨 - 配偶 - 比尔·盖茨 -主席 - 微软 - 总部 - 西雅图”,推测出梅林达可能居住在西雅图。
基于算法推理的基本原理一般情况下都是这样:
存在一定数量的三元组关系数据作为训练集和测试集,训练集和测试集的头/尾实体、关系都来自于固定的实体集合和关系集合(也有基于开放域的),通过训练集训练一个评分函数的参数,再通过该函数给测试三元组关系做一个评估打分,然后获得一个评分排名。
这里面一般涉及到如下几个方面:
- 一个评分函数:
构造一个评分函数来对三元组成立的可能性进行打分:这个打分函数是通过一定的计算操作来获得实体或关系之间的关联度。
评分函数一般是计算:
实体e1 与 (关系r o 实体 e2 )的相似度
(实体e1 o 关系r) 与 实体 e2的相似度
关系r 与 (实体e1 o 实体 e2 )的相似度
其中o是一种计算操作:比如加法/乘法/非线性法等
- 三种操作:
线性:加法、乘法
非线性:神经网络(自定义的类神经网络)
- 双层组合:
第一层建立表示向量的映射(网络--编码);
第二层对表示后的向量进行组合(评分函数--解码);
当然,以上只是我根据大部分算法给出的一个大致的方法趋势,并不是所有的算法都是这样,具体算法需要具体讨论。一般来说,理解了TransE的原理和源码,其它算法的原理及源码就很好理解了。
3、知识图谱推理的主要方法
知识图谱相关的推理算法目前主要分为单步推理(直接关系,没有考虑路径特征)和多步推理(间接关系,考虑路径特征),在单步推理和多步推理中主要包括4个研究方向:基于传统的规则推理、基于分布式表示推理、基于神经网络的推理、基于上述方法的混合推理。在每个研究方向又延伸了很多小的方向和方法,已存在的算法和论文比较多,具体可以参考如下的分类图:
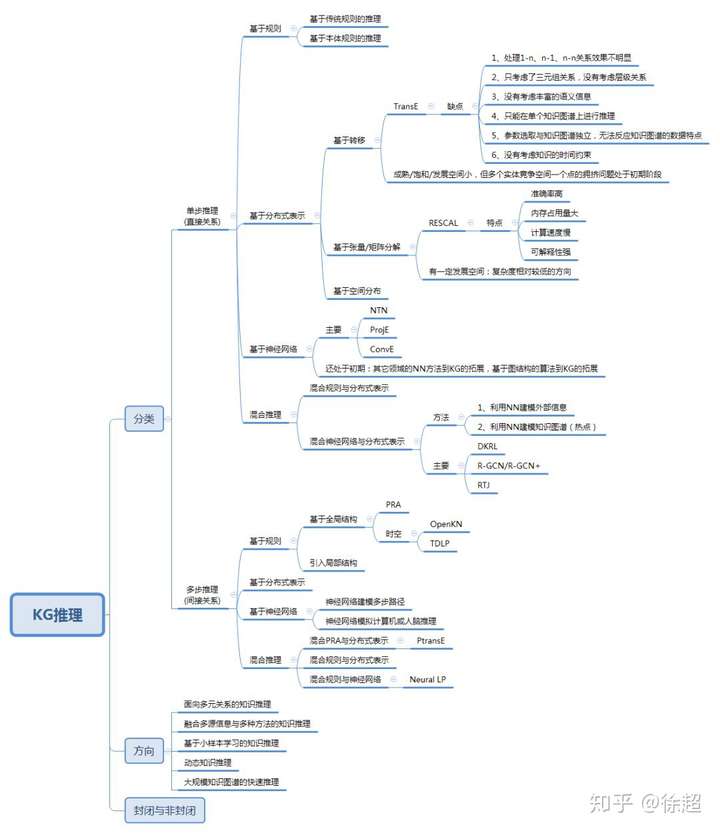
常见的一些算法
距离模型SE
单层神经网络SLM
能量模型SME
双线性模型LMF
张量神经网络NTN/ProjE
矩阵分解模型RESCAL
乘法方法 SimplE、DistMULT(不区分头尾实体)、HOLE(区分头尾实体)、ComplEx(虚实向量)、Analogy(类比推理)
TransE:同一语义空间表示,向量加法
TransH:让一个实体在不同关系下有不同的表示
TransR:认为不同的关系拥有不同的语义空间(实体向关系空间投射)
CTransR:细分关系
TransD:为头尾实体构建不同的投影矩阵(矩阵与实体关系都相关)
TranSparse:为头尾实体构建不同的投影矩阵(不同的矩阵稀疏度)
TransA:损失函数中距离度量改用马氏距离,并为每一维的学习设置不同权重
TransG:用高斯混合模型来描述头尾实体(一种关系,对应多种语义;每种语义用高斯分布表示)
KG2E:头尾实体的向量差用高斯分布表示,关系也用高斯分布表示,评估两个分布之间的相似度
ConvE:图结构的多层卷积网络
SimplE:
(1)每个实体表示成两个向量:头实体向量和尾实体向量(每个向量是独立的)
(2)每个关系表示成两个关系:顺关系和逆关系向量
DKRL:
(1)结构化信息的表示:原有的算法
(2)描述性信息的表示:用CBOW或者深度学习网络对描述信息进行建模
(3)能量函数:Es+Ed(Edd+Esd+Eds)
OpenKGC:
(1)只用文本信息特征来学习实体和关系的表示;
(2)能为没有见过的实体学习表示向量(但该构成该实体的单词必须是固定的)
PTransE:
(1) 可靠性路径的选择;
(2) 路径的表示学习(语义表示-组合表示)
R-GCN/R-GCN+:
(1) GCN提供了一个为图节点表示学习的框架;
(2) R-GCN提供了一个三元组自编码解码的评分方法;
每种类别下的重要算法
张量神经网络:SLM、NTN、ProjE
图卷积网络:R-GCN/R-GCN+、ConvE
分布式+规则的混合:Naual Lp、DKRL、RTJ、ComplexER、ComplexE+NNE
基于路径的建模:PTransE
多源信息融合的建模: DKRL、KGC、NLFeat、TEKE_H、SSP
几个重要趋势
- 融合其它多源信息:
融合三元组实体的描述信息
融合三元组实体的属性信息
融合网络文本信息(把单词作为研究基准/把实体作为研究基准)
融合其它知识库信息
- 加入路径信息
- 加入业务规则信息
- 编码解码的原理、多层卷积模型
- 混合使用
4、TransE算法理解
TransE模型的目标是学习出实体(entity)和关系(relation)的低维向量表示。对于一个三元组 (h,l,t),其中h和t是实体, h称为头实体,t是尾实体,l是它们的关系(也就是属性),TransE希望它们的嵌入表示 (h,l,t)有如下关系: t≈h+l,也就是说t要和h+l尽可能接近,反之如果这三者不构成三元组,则要尽可能远离。用图直观表示如下:
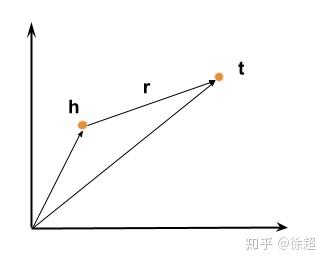
为此,TransE定义了三元组的“能量” e(h,l,t)=d(h+l,t),这里的“能量”(论文中说的the energy of a triplet)可以看作是损失函数,d是一个距离度量方法(dissimilarity measure),在这里就是向量之间的距离,即公式:
d(h+l,t)=∣h+l−t∣L1/L2
公式1中的L1/L2指的是L1或L2距离,或者叫L1或L2范数。那么,只要最小化公式1这个损失函数就行,但为了增强区分度,TransE构造了一些反例三元组,希望反例的距离要尽可能的大,这样最终的优化目标(损失函数)就是公式:
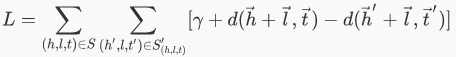
公式2中的 (h′,l,t′)是构造的反例三元组,构造方法是将正例三元组的头实体或尾实体替换成一个随机的实体,且二者不能同时被替换,即公式:
S(h,l,t)′={(h′,l,t)∣h′∈E}∪{(h,l,t′)∣t′∈E}
为了防止过拟合,需要加入正则项,然后用随机梯度下降算法(stochastic gradient descent)来最小化损失函数。
帮助理解:
(1)需要找到一个向量来表示对应的实体、关系;
(2)找到一个什么样的向量?
——当表示后的向量能构成t≈h+l这样一个等式关系,就说明这三个向量可以表示对应的对象。
(3) 如何找到这样一个向量?
——在向量维度确定的情况下,通过构造一个损失函数,来训练生成的向量满足t≈h+l关系,使损失函数值最小,否则调整向量。
(4)具体如何调整向量?
——SGD:获得第i个维度上的t-h-r,理论上应该接近于零,如果不等于零,则通过学习率来修改t/h/r在该维度上的值,等整个维度都学习一遍,则t/h/r分别对应的向量完成了一次整体的学习。
(5)如何用来预测链接?
——预测:固定头/尾实体和关系,对计算的尾/头实体与真实的尾/头实体进行比较(遍历所有的实体,代入距离评分函数)
——利用top-k准则:对于给定的k值,预测算法会给出基于每个实体计算某种评分的排序来输出前k个答案
——两种评估的方法:
- Mean Rank: 排名的平均值(越小越好);
- Hit@K: 排名在前K位所占的比例(越大越好);
(6)训练/测试过程
- 训练过程:初始化K维的实体向量和关系向量,对于每一个训练的三元组,从初始化的向量中获得对应的表示向量,通过计算loss函数来不断调整实体向量和关系向量(在每一个维度上根据学习率来修改)
- 测试过程:如果是预测关系,对于输入的每一个测试三元组,用所有的关系向量依次去替代原关系向量,分别计算L1或L2距离作为评估分数,根据分数计算原关系的排名。
(7) 算法能完成的三个任务
- 链接预测:对头/尾实体缺失的三元组,进行实体预测,对于每一个测试的三元组,用KG中的所有实体来代替首/尾实体,并对实体进行降序排序
- 三元组分类:判断一个给定的三元组是否正确,是个二分类问题。设定一个阈值,通过该三元组的分数与阈值进行比较,确定三元组的正负
- 关系抽取:都抽取的三元组进行分类,判断抽取的关系是否正确
欢迎关注微信公号:数联未来(zycnb1)
