本文主要参照博客中内容实现AlexNet网络的构建、测试过程,利用自己的方法制作训练集来进行微调过程。本文主要介绍在TensorFlow框架下AlexNet网络的实现程序。下图是AlexNet网络的网络结构:
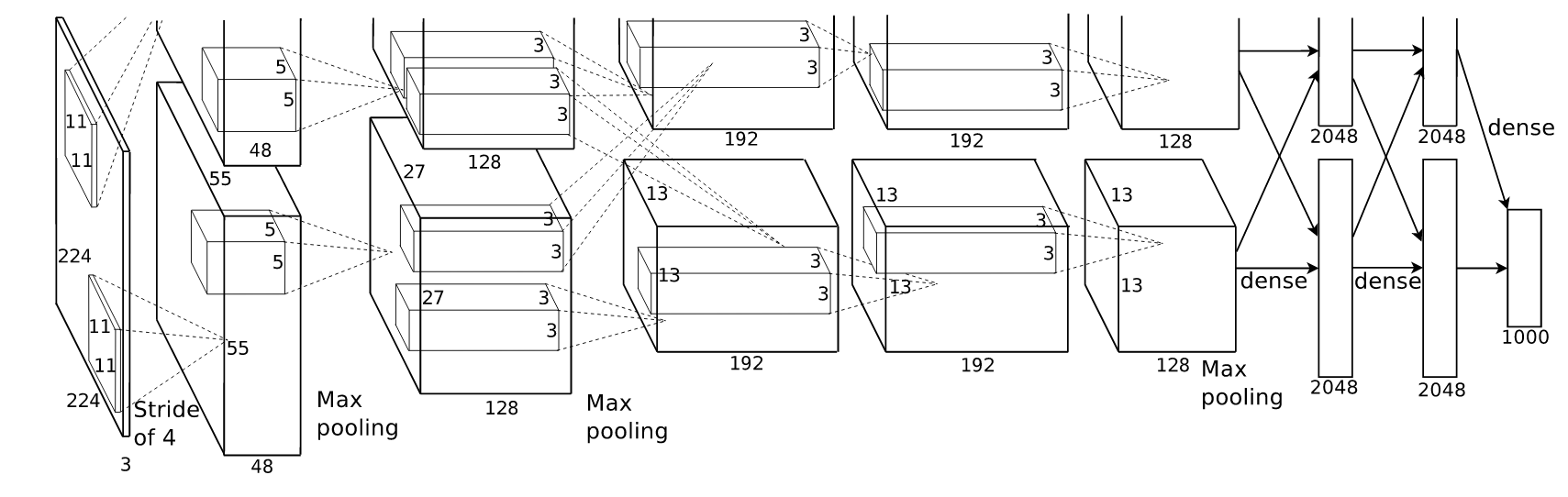
1. AlexNet网络的构建过程:下面程序(注释)创建了一个类来定义AlexNet模型图,并带有加载预训练参数的函数
#定义AlexNet神经网络结构模型
import tensorflow as tf
import numpy as np
#建立模型图
class AlexNet(object):
#keep_prob:dropout概率,num_classes:数据类别数,skip_layer
def __init__(self,x,keep_prob,num_classes,skip_layer,weights_path='DEFAULT'):
self.X=x
self.NUM_CLASSES=num_classes
self.KEEP_PROB=keep_prob
self.SKIP_LAYER=skip_layer
if weights_path=='DEFAULT':
self.WEIGHTS_PATH='f:\\python程序\\AlexNet_Protect\\bvlc_alexnet.npy'
else:
self.WEIGHTS_PATH=weights_path
self.create()
def create(self):
#第一层:卷积层-->最大池化层-->LRN
conv1=conv_layer(self.X,11,11,96,4,4,padding='VALID',name='conv1')
self.conv1=conv1
pool1=max_pool(conv1,3,3,2,2,padding='VALID',name='pool1')
norm1=lrn(pool1,2,2e-05,0.75,name='norml')
#第二层:卷积层-->最大池化层-->LRN
conv2=conv_layer(norm1,5,5,256,1,1,groups=2,name='conv2')
self.conv2=conv2
pool2=max_pool(conv2,3,3,2,2,padding='VALID',name='pool2')
norm2=lrn(pool2,2,2e-05,0.75,name='norm2')
#第三层:卷积层
conv3=conv_layer(norm2,3,3,384,1,1,name='conv3')
self.conv3=conv3
#第四层:卷积层
conv4=conv_layer(conv3,3,3,384,1,1,groups=2,name='conv4')
self.conv4=conv4
#第五层:卷积层-->最大池化层
conv5=conv_layer(conv4,3,3,256,1,1,groups=2,name='conv5')
self.conv5=conv5
pool5=max_pool(conv5,3,3,2,2,padding='VALID',name='pool5')
#第六层:全连接层
flattened=tf.reshape(pool5,[-1,6*6*256])
fc6=fc_layer(flattened,6*6*256,4096,name='fc6')
dropout6=dropout(fc6,self.KEEP_PROB)
#第七层:全连接层
fc7=fc_layer(dropout6,4096,4096,name='fc7')
dropout7=dropout(fc7,self.KEEP_PROB)
#第八层:全连接层,不带激活函数
self.fc8=fc_layer(dropout7,4096,self.NUM_CLASSES,relu=False,name='fc8')
#加载神经网络预训练参数,将存储于self.WEIGHTS_PATH的预训练参数赋值给那些没有在self.SKIP_LAYER中指定的网络层的参数
def load_initial_weights(self,session):
#下载权重文件
weights_dict=np.load(self.WEIGHTS_PATH,encoding='bytes').item()
for op_name in weights_dict:
if op_name not in self.SKIP_LAYER:
with tf.variable_scope(op_name,reuse=True):
for data in weights_dict[op_name]:
#偏置项
if len(data.shape)==1:
var=tf.get_variable('biases',trainable=False)
session.run(var.assign(data))
#权重
else:
var=tf.get_variable('weights',trainable=False)
session.run(var.assign(data))
#定义卷积层,当groups=1时,AlexNet网络不拆分;当groups=2时,AlexNet网络拆分成上下两个部分。
def conv_layer(x,filter_height,filter_width,num_filters,stride_y,stride_x,name,padding='SAME',groups=1):
#获得输入图像的通道数
input_channels=int(x.get_shape()[-1])
#创建lambda表达式
convovle=lambda i,k:tf.nn.conv2d(i,k,strides=[1,stride_y,stride_x,1],padding=padding)
with tf.variable_scope(name) as scope:
#创建卷积层所需的权重参数和偏置项参数
weights=tf.get_variable("weights",shape=[filter_height,filter_width,input_channels/groups,num_filters])
biases=tf.get_variable("biases",shape=[num_filters])
if groups==1:
conv=convovle(x,weights)
#当groups不等于1时,拆分输入和权重
else:
input_groups=tf.split(axis=3,num_or_size_splits=groups,value=x)
weight_groups=tf.split(axis=3,num_or_size_splits=groups,value=weights)
output_groups=[convovle(i,k) for i,k in zip(input_groups,weight_groups)]
#单独计算完后,再次根据深度连接两个网络
conv=tf.concat(axis=3,values=output_groups)
#加上偏置项
bias=tf.reshape(tf.nn.bias_add(conv,biases),conv.get_shape().as_list())
#激活函数
relu=tf.nn.relu(bias,name=scope.name)
return relu
#定义全连接层
def fc_layer(x,num_in,num_out,name,relu=True):
with tf.variable_scope(name) as scope:
#创建权重参数和偏置项
weights=tf.get_variable("weights",shape=[num_in,num_out],trainable=True)
biases=tf.get_variable("biases",[num_out],trainable=True)
#计算
act=tf.nn.xw_plus_b(x,weights,biases,name=scope.name)
if relu==True:
relu=tf.nn.relu(act)
return relu
else:
return act
#定义最大池化层
def max_pool(x,filter_height,filter_width,stride_y,stride_x,name,padding='SAME'):
return tf.nn.max_pool(x,ksize=[1,filter_height,filter_width,1],strides=[1,stride_y,stride_x,1],padding=padding,name=name)
#定义局部响应归一化LPN
def lrn(x,radius,alpha,beta,name,bias=1.0):
return tf.nn.local_response_normalization(x,depth_radius=radius,alpha=alpha,beta=beta,bias=bias,name=name)
#定义dropout
def dropout(x,keep_prob):
return tf.nn.dropout(x,keep_prob)
2. 输入一张图片对AlexNet网络进行测试,可以查看卷积层提取的特征图
import tensorflow as tf
import AlexNet_model
import numpy as np
import cv2
import caffe_classes
import matplotlib.pyplot as plt
keep_prob=0.5
num_classes=1000
skip_layer=[]
#测试图片读取路径
image = cv2.imread("f:\\tmp\\data\\zebra.jpeg")
img_resized = cv2.resize(image, (227, 227))
x=tf.placeholder(tf.float32,[1,227,227,3],name='x-input')
#定义神经网络结构,初始化模型
model=AlexNet_model.AlexNet(x,keep_prob,num_classes,skip_layer)
conv1=model.conv1
conv5=model.conv5
score=model.fc8
#获得神经网络前向传播的softmax层输出
softmax=tf.nn.softmax(score)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
model.load_initial_weights(sess)
test=np.reshape(img_resized,(1,227,227,3))
#sess.run()函数运行张量返回的是就是对应的数组
soft,con1,con5=sess.run([softmax,conv1,conv5],feed_dict={x:test})
#显示第五层卷积层提取的前6个特征图
for i in range(6):
plt.matshow(con5[0,:,:,0],cmap=plt.cm.gray)
plt.show()
#获取其中最大值所在的索引
maxx=np.argmax(soft)
#找到目标所属的类别
ress=caffe_classes.class_names[maxx]
text='Predicted class:'+str(maxx)+'('+ress+')'
#显示测试类别
cv2.putText(image,text, (20,20), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)
#显示属于该类别的概率
cv2.putText(image,'with probability:'+str(soft[0][maxx]), (20,50), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)
cv2.imshow('test_image', image)
#显示10秒
cv2.waitKey(10000)
测试结果如图所示:

3. 直接读取本地图片制作自己的数据集,用的是猫狗大战图片,链接:http://pan.baidu.com/s/1dFd8kmt 密码:psor
import tensorflow as tf
import os
import numpy as np
#生成训练图片的路径
train_dir='f:\\cat_dog_image\\train\\'
#获取图片,存放到对应的列表中,同时贴上标签,存放到label列表中
def get_files(file_dir):
cats =[]
label_cats =[]
dogs =[]
label_dogs =[]
for file in os.listdir(file_dir):
name = file.split(sep='.')
if name[0]=='cat':
cats.append(file_dir + file)
label_cats.append(0)
else:
dogs.append(file_dir + file)
label_dogs.append(1)
#合并数据
image_list = np.hstack((cats, dogs))
label_list = np.hstack((label_cats, label_dogs))
#利用shuffle打乱数据
temp = np.array([image_list, label_list])
temp = temp.transpose() # 转置
np.random.shuffle(temp)
#将所有的image和label转换成list
image_list = list(temp[:, 0])
label_list = list(temp[:, 1])
label_list = [int(i) for i in label_list]
return image_list, label_list
#将上面生成的List传入get_batch() ,转换类型,产生一个输入队列queue,因为img和lab
#是分开的,所以使用tf.train.slice_input_producer(),然后用tf.read_file()从队列中读取图像
def get_batch(image,label,image_W,image_H,batch_size,capacity):
#将python.list类型转换成tf能够识别的格式
image=tf.cast(image,tf.string)
label=tf.cast(label,tf.int32)
#产生一个输入队列queue
input_queue=tf.train.slice_input_producer([image,label])
label=input_queue[1]
image_contents=tf.read_file(input_queue[0])
#将图像解码,不同类型的图像不能混在一起,要么只用jpeg,要么只用png等。
image=tf.image.decode_jpeg(image_contents,channels=3)
#将数据预处理,对图像进行旋转、缩放、裁剪、归一化等操作,让计算出的模型更健壮。
image=tf.image.resize_image_with_crop_or_pad(image,image_W,image_H)
image=tf.image.per_image_standardization(image)
#生成batch
image_batch,label_batch=tf.train.batch([image,label],batch_size=batch_size,num_threads=64,capacity=capacity)
#重新排列标签,行数为[batch_size]
#label_batch=tf.reshape(label_batch,[batch_size])
image_batch=tf.cast(image_batch,tf.float32)
return image_batch,label_batch
4. 利用自己的训练集对AlexNet网络进行微调,这里对AlexNet网络中第六、七、八全连接层进行重新训练
#利用Tensorflow对预训练的AlexNet网络进行微调
import tensorflow as tf
import numpy as np
import os
from AlexNet_model import AlexNet
#from datagenerator import ImageDataGenerator
#from datetime import datetime
#from tensorflow.contrib.data import Iterator
import input_selfdata
#模型保存的路径和文件名。
MODEL_SAVE_PATH="/model/"
MODEL_NAME="alexnet_model.ckpt"
#训练集图片所在路径
train_dir='f:\\cat_dog_image\\train\\'
#训练图片的尺寸
image_size=227
#训练集中图片总数
total_size=250000
#学习率
learning_rate=0.001
#训练完整数据集迭代轮数
num_epochs=10
#数据块大小
batch_size=128
#执行Dropout操作所需的概率值
dropout_rate=0.5
#类别数目
num_classes=2
#需要重新训练的层
train_layers=['fc8','fc7','fc6']
#读取本地图片,制作自己的训练集,返回image_batch,label_batch
train, train_label = input_selfdata.get_files(train_dir)
x,y=input_selfdata.get_batch(train,train_label,image_size,image_size,batch_size,2000)
#用于计算图输入和输出的TF占位符,每次读取一小部分数据作为当前的训练数据来执行反向传播算法
#x =tf.placeholder(tf.float32,[batch_size,227,227,3],name='x-input')
#y =tf.placeholder(tf.float32,[batch_size,num_classes])
keep_prob=tf.placeholder(tf.float32)
#定义神经网络结构,初始化模型
model =AlexNet(x,keep_prob,num_classes,train_layers)
#获得神经网络前向传播的输出
score=model.fc8
#获得想要训练的层的可训练变量列表
var_list = [v for v in tf.trainable_variables() if v.name.split('/')[0] in train_layers]
#定义损失函数,获得loss
with tf.name_scope("cross_ent"):
loss=tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(logits=score,labels=y))
#定义反向传播算法(优化算法)
with tf.name_scope("train"):
# 获得所有可训练变量的梯度
gradients = tf.gradients(loss, var_list)
gradients = list(zip(gradients, var_list))
# 选择优化算法,对可训练变量应用梯度下降算法更新变量
optimizer = tf.train.GradientDescentOptimizer(learning_rate)
train_op = optimizer.apply_gradients(grads_and_vars=gradients)
#使用前向传播的结果计算正确率
with tf.name_scope("accuracy"):
correct_pred=tf.equal(tf.cast(tf.argmax(score,1),tf.int32),y)
accuracy=tf.reduce_mean(tf.cast(correct_pred,tf.float32))
#Initialize an saver for store model checkpoints 加载模型
saver=tf.train.Saver()
# 每个epoch中验证集/测试集需要训练迭代的轮数
train_batches_per_epoch = int(np.floor(total_size/batch_size))
with tf.Session() as sess:
#变量初始化
tf.global_variables_initializer().run()
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(coord=coord)
try:
for epoch in range(num_epochs):
for step in range(train_batches_per_epoch):
#while not coord.should_stop():
if coord.should_stop():
break
_,loss_value,accu=sess.run([train_op,loss,accuracy],feed_dict={keep_prob: 1.})
if step%50==0:
print("Afetr %d training step(s),loss on training batch is %g,accuracy is %g." % (step,loss_value,accu))
saver.save(sess,os.path.join(MODEL_SAVE_PATH,MODEL_NAME))
except tf.errors.OutOfRangeError:
print('done!')
finally:
coord.request_stop()
coord.join(threads)