【Tensorflow】经典卷积网络(LeNet,AlexNet,VGGNet,InceptionNet,ResNet)
1.LeNet

Lenet 是一系列网络的合称,包括 Lenet1 - Lenet5,由 Yann LeCun 等人在 1990 年《Handwritten Digit Recognition with a Back-Propagation Network》中提出,是卷积神经网络的 HelloWorld。
如果将池化看作卷积的附属结构,那么Lenet共有五层结构,分别是两层卷积和三层全连接。LeNet时代还没有批标准化操作,主流激活函数还是sigmoid,也没有Dropout层。

过程如下:

代码如下:
class LeNet5(Model):
def __init__(self):
super(LeNet5, self).__init__() # 继承父类
self.c1 = Conv2D(filters=6, kernel_size=(5, 5),
activation='sigmoid') # 第一层卷积,6个卷积核,卷积核尺寸为5x5,激活函数使用sigmoid,滑动步长默认为1
self.p1 = MaxPool2D(pool_size=(2, 2), strides=2)
# 池化层,选择最大池化,池化核尺寸为2x2,步长为2
self.c2 = Conv2D(filters=16, kernel_size=(5, 5),
activation='sigmoid') # 第二层卷积,16个卷积核,卷积核尺寸为5x5,激活函数使用sigmoid,滑动步长默认为1
self.p2 = MaxPool2D(pool_size=(2, 2), strides=2)
# 池化层,选择最大池化,池化核尺寸为2x2,步长为2
self.flatten = Flatten() # 拉直后输入全连接层
self.f1 = Dense(120, activation='sigmoid') # 第一层全连接有120个神经元,使用sigmoid函数作为激活函数
self.f2 = Dense(84, activation='sigmoid') # 第二层全连接有84个神经元,使用sigmoid函数作为激活函数
self.f3 = Dense(10, activation='softmax') # 第三层全连接有10个神经元,使用softmax函数作为激活函数,使输出符合概率分布
def call(self, x):
x = self.c1(x)
x = self.p1(x)
x = self.c2(x)
x = self.p2(x)
x = self.flatten(x)
x = self.f1(x)
x = self.f2(x)
y = self.f3(x)
return y
model = LeNet5() # 调用类
2.AlexNet

AlexNet网络诞生于2012年,是当您ImageNet竞赛的冠军,Top5错误率为16.4%。AlexNet共有8层,经过五层卷积和池化,再过三个全连接层。使用ReLU函数提高了训练速度,使用Dropout,缓解了过拟合。在标准化处使用的是LRN (Local Response Normalization) 标准化,由于LRN和BN十分相似,所以可以用BN进行替换。
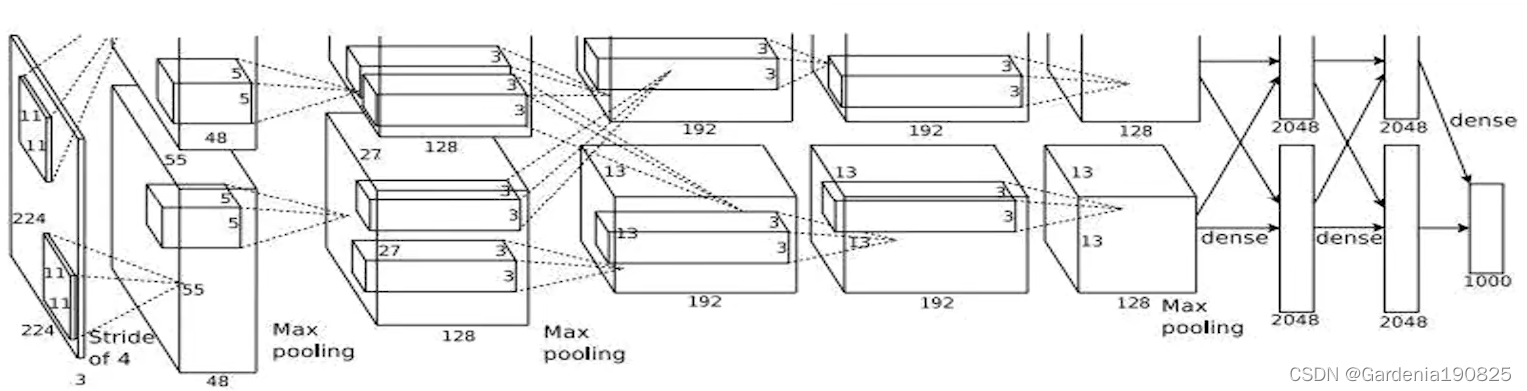
过程如下:

代码如下:
class AlexNet8(Model):
def __init__(self):
super(AlexNet8, self).__init__()
self.c1 = Conv2D(filters=96, kernel_size=(3, 3))
self.b1 = BatchNormalization()
self.a1 = Activation('relu')
self.p1 = MaxPool2D(pool_size=(3, 3), strides=2)
# 第一层,使用96个卷积核进行卷积,使用批标准化,使用relu激活函数,使用3x3的池化核进行池化,不使用dropout
self.c2 = Conv2D(filters=256, kernel_size=(3, 3))
self.b2 = BatchNormalization()
self.a2 = Activation('relu')
self.p2 = MaxPool2D(pool_size=(3, 3), strides=2)
# 第二层,使用256个卷积核进行卷积,使用批标准化,使用relu激活函数,使用3x3的池化核进行池化,不使用dropout
self.c3 = Conv2D(filters=384, kernel_size=(3, 3), padding='same',
activation='relu')
# 第三层,使用384个卷积核进行卷积,使用全零填充,使用relu激活函数
self.c4 = Conv2D(filters=384, kernel_size=(3, 3), padding='same',
activation='relu')
# 第四层,使用384个卷积核进行卷积,使用全零填充,使用relu激活函数
self.c5 = Conv2D(filters=256, kernel_size=(3, 3), padding='same',
activation='relu')
self.p3 = MaxPool2D(pool_size=(3, 3), strides=2)
# 第五层,使用256个卷积核进行卷积,使用全零填充,使用relu激活函数,使用最大池化
self.flatten = Flatten() # 拉直后输入全连接层
self.f1 = Dense(2048, activation='relu') # 第六层,使用2048个神经元,使用relu激活函数,搭建全连接网络
self.d1 = Dropout(0.5) # 以50%的概率随机舍弃神经元
self.f2 = Dense(2048, activation='relu') # 第七层,使用2048个神经元,使用relu激活函数,搭建全连接网络
self.d2 = Dropout(0.5) # 以50%的概率随机舍弃神经元
self.f3 = Dense(10, activation='softmax') # 第八层,使用10个神经元,使用softmax激活函数,使输出符合概率分布
def call(self, x):
x = self.c1(x)
x = self.b1(x)
x = self.a1(x)
x = self.p1(x)
x = self.c2(x)
x = self.b2(x)
x = self.a2(x)
x = self.p2(x)
x = self.c3(x)
x = self.c4(x)
x = self.c5(x)
x = self.p3(x)
x = self.flatten(x)
x = self.f1(x)
x = self.d1(x)
x = self.f2(x)
x = self.d2(x)
y = self.f3(x)
return y
model = AlexNet8()
3.VGGNet

VGGNet诞生于2014年,是当年ImageNet竞赛的亚军,Top5错误率减小到7.3%。VGGNet使用小尺寸卷积核,在减少参数的同时,提高了识别准确率,网络结构规整,适合硬件加速。以16层网络为例,代码如下:
class VGG16(Model):
def __init__(self):
super(VGG16, self).__init__()
self.c1 = Conv2D(filters=64, kernel_size=(3, 3), padding='same') # 卷积层1
self.b1 = BatchNormalization() # BN层1
self.a1 = Activation('relu') # 激活层1
# 第一层CBA
self.c2 = Conv2D(filters=64, kernel_size=(3, 3), padding='same', )
self.b2 = BatchNormalization() # BN层1
self.a2 = Activation('relu') # 激活层1
self.p1 = MaxPool2D(pool_size=(2, 2), strides=2, padding='same')
self.d1 = Dropout(0.2) # dropout层
# 第二层CBAPD
self.c3 = Conv2D(filters=128, kernel_size=(3, 3), padding='same')
self.b3 = BatchNormalization() # BN层1
self.a3 = Activation('relu') # 激活层1
# 第三层CBA
self.c4 = Conv2D(filters=128, kernel_size=(3, 3), padding='same')
self.b4 = BatchNormalization() # BN层1
self.a4 = Activation('relu') # 激活层1
self.p2 = MaxPool2D(pool_size=(2, 2), strides=2, padding='same')
self.d2 = Dropout(0.2) # dropout层
# 第四层CBAPD
self.c5 = Conv2D(filters=256, kernel_size=(3, 3), padding='same')
self.b5 = BatchNormalization() # BN层1
self.a5 = Activation('relu') # 激活层1
# 第五层CBA
self.c6 = Conv2D(filters=256, kernel_size=(3, 3), padding='same')
self.b6 = BatchNormalization() # BN层1
self.a6 = Activation('relu') # 激活层1
# 第六层CBA
self.c7 = Conv2D(filters=256, kernel_size=(3, 3), padding='same')
self.b7 = BatchNormalization()
self.a7 = Activation('relu')
self.p3 = MaxPool2D(pool_size=(2, 2), strides=2, padding='same')
self.d3 = Dropout(0.2)
# 第七层CBAPD
self.c8 = Conv2D(filters=512, kernel_size=(3, 3), padding='same')
self.b8 = BatchNormalization() # BN层1
self.a8 = Activation('relu') # 激活层1
# 第八层CBA
self.c9 = Conv2D(filters=512, kernel_size=(3, 3), padding='same')
self.b9 = BatchNormalization() # BN层1
self.a9 = Activation('relu') # 激活层1
# 第九层CBA
self.c10 = Conv2D(filters=512, kernel_size=(3, 3), padding='same')
self.b10 = BatchNormalization()
self.a10 = Activation('relu')
self.p4 = MaxPool2D(pool_size=(2, 2), strides=2, padding='same')
self.d4 = Dropout(0.2)
# 第十层CBAPD
self.c11 = Conv2D(filters=512, kernel_size=(3, 3), padding='same')
self.b11 = BatchNormalization() # BN层1
self.a11 = Activation('relu') # 激活层1
# 第十一层CBA
self.c12 = Conv2D(filters=512, kernel_size=(3, 3), padding='same')
self.b12 = BatchNormalization() # BN层1
self.a12 = Activation('relu') # 激活层1
# 第十二层CBA
self.c13 = Conv2D(filters=512, kernel_size=(3, 3), padding='same')
self.b13 = BatchNormalization()
self.a13 = Activation('relu')
self.p5 = MaxPool2D(pool_size=(2, 2), strides=2, padding='same')
self.d5 = Dropout(0.2)
# 第十三层CBAPD
self.flatten = Flatten() # 拉直后输入全连接网络
self.f1 = Dense(512, activation='relu') # 第十四层全连接,512个神经元,relu激活函数
self.d6 = Dropout(0.2) # 20%的概率舍弃
self.f2 = Dense(512, activation='relu') # 第十五层全连接,512个神经元,relu激活函数
self.d7 = Dropout(0.2) # 20%的概率舍弃
self.f3 = Dense(10, activation='softmax') # 第十六层全连接,10个神经元,softmax激活函数,使输出符合概率分布
def call(self, x):
x = self.c1(x)
x = self.b1(x)
x = self.a1(x)
x = self.c2(x)
x = self.b2(x)
x = self.a2(x)
x = self.p1(x)
x = self.d1(x)
x = self.c3(x)
x = self.b3(x)
x = self.a3(x)
x = self.c4(x)
x = self.b4(x)
x = self.a4(x)
x = self.p2(x)
x = self.d2(x)
x = self.c5(x)
x = self.b5(x)
x = self.a5(x)
x = self.c6(x)
x = self.b6(x)
x = self.a6(x)
x = self.c7(x)
x = self.b7(x)
x = self.a7(x)
x = self.p3(x)
x = self.d3(x)
x = self.c8(x)
x = self.b8(x)
x = self.a8(x)
x = self.c9(x)
x = self.b9(x)
x = self.a9(x)
x = self.c10(x)
x = self.b10(x)
x = self.a10(x)
x = self.p4(x)
x = self.d4(x)
x = self.c11(x)
x = self.b11(x)
x = self.a11(x)
x = self.c12(x)
x = self.b12(x)
x = self.a12(x)
x = self.c13(x)
x = self.b13(x)
x = self.a13(x)
x = self.p5(x)
x = self.d5(x)
x = self.flatten(x)
x = self.f1(x)
x = self.d6(x)
x = self.f2(x)
x = self.d7(x)
y = self.f3(x)
return y
model = VGG16()