2012年Imagenet比赛冠军的model——Alexnet (以第一作者alex命名)
模型结构见下图,别看只有寥寥八层(不算input层),但是它有60M以上的参数总量,事实上在参数量上比后面的网络都大。
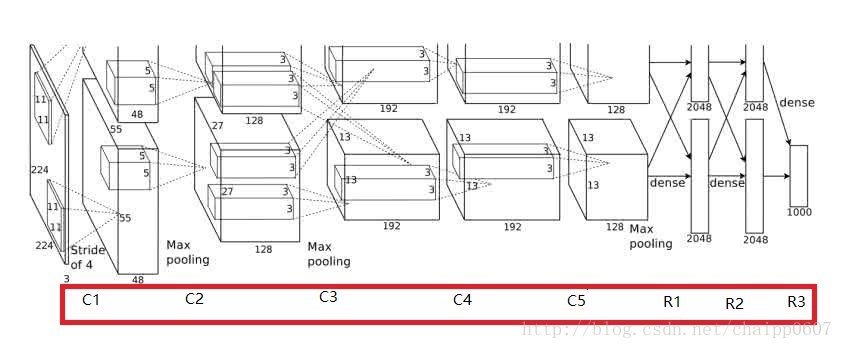
由于当时的显卡容量问题,AlexNet 的60M个参数无法全部放在一张显卡上操作,所以采用了两张显卡分开操作的形式,其中在C3,R1,R2,R3层上出现交互,所谓的交互就是通道的合并,是一种串接操作。
这个图有点点特殊的地方是卷积部分都是画成上下两块,意思是说吧这一层计算出来的feature map分开,但是当前层用到的数据要看连接的虚线,如图中input层之后的第一层第二层之间的虚线是分开的,是说第二层上面的128map是由第一层上面的48map计算的,下面同理;而第三层前面的虚线是完全交叉的,就是说每一个192map都是由前面的128+128=256map同时计算得到的。
我们来计算下这些参数都是怎么来的:
C1:96×11×11×3(卷积核个数/宽/高/卷积核的通道数) 34848个
C2:256×5×5×48(卷积核个数/宽/高/卷积核的通道数) 307200个
C3:384×3×3×25(卷积核个数/宽/高/卷积核的通道数) 884736个
C4:384×3×3×192(卷积核个数/宽/高/卷积核的通道数) 663552个
C5:256×3×3×192(卷积核个数/宽/高/卷积核的通道数) 442368个
R1:4096×6×6×256(卷积核个数/宽/高/卷积核的通道数) 37748736个
R2:4096×4096 16777216个
R3:4096×1000 4096000个
具体打开Alexnet的每一阶段:
(1)con - relu - pooling - LRN
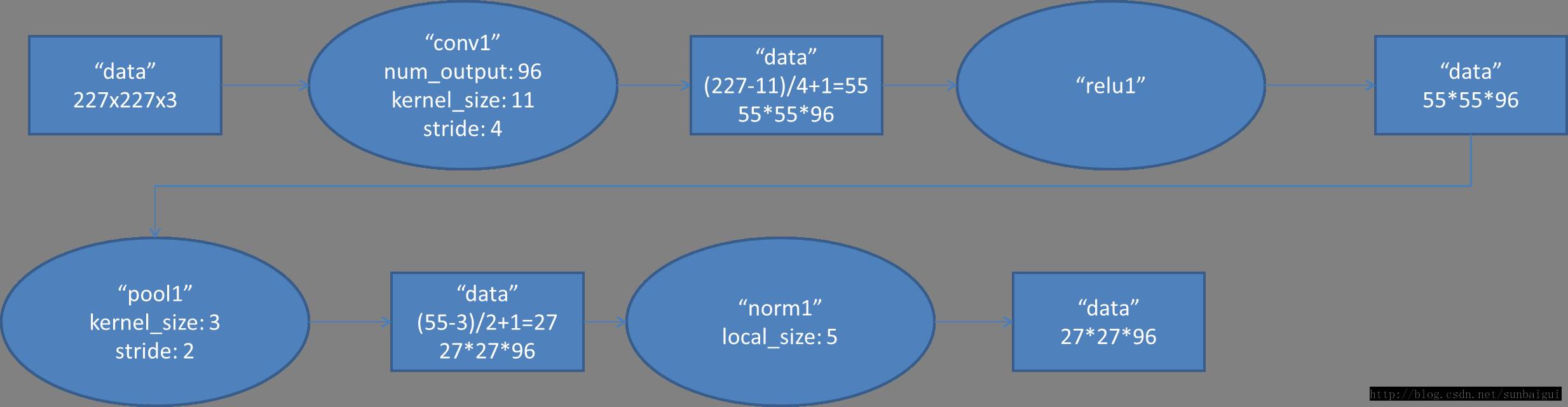
具体计算都在图里面写了,要注意的是input层是227*227,而不是paper里面的224*224,这里可以算一下,主要是227可以整除后面的conv1计算,224不整除。如果一定要用224可以通过自动补边实现,不过在input就补边感觉没有意义,补的也是0。
(2)conv - relu - pool - LRN

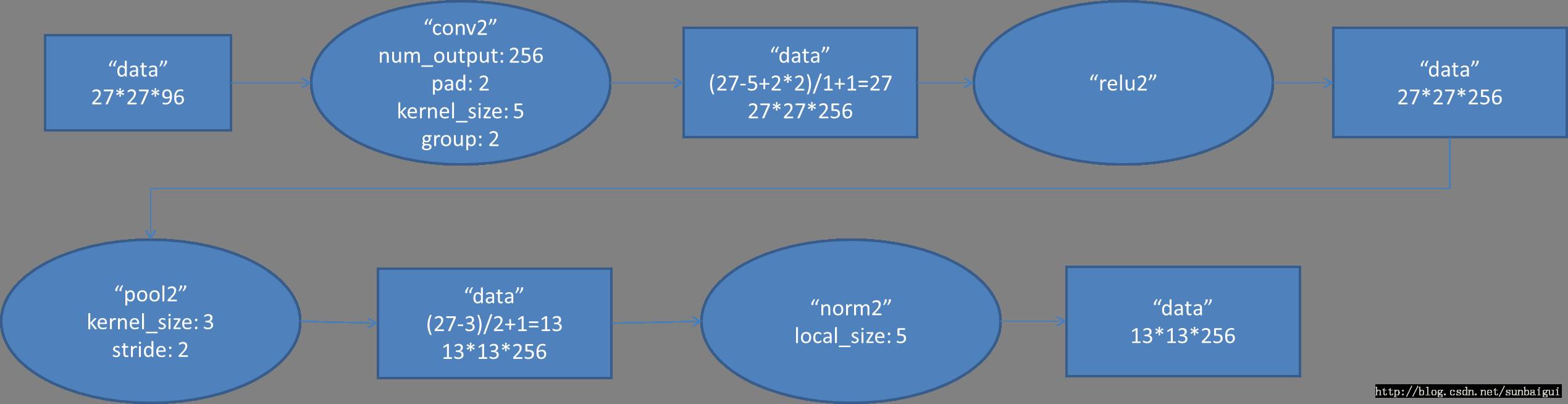
和上面基本一样,唯独需要注意的是group=2,这个属性强行把前面结果的feature map分开,卷积部分分成两部分做。
(3)conv - relu

(4)conv-relu
(5)conv - relu - pool

(6)fc - relu - dropout
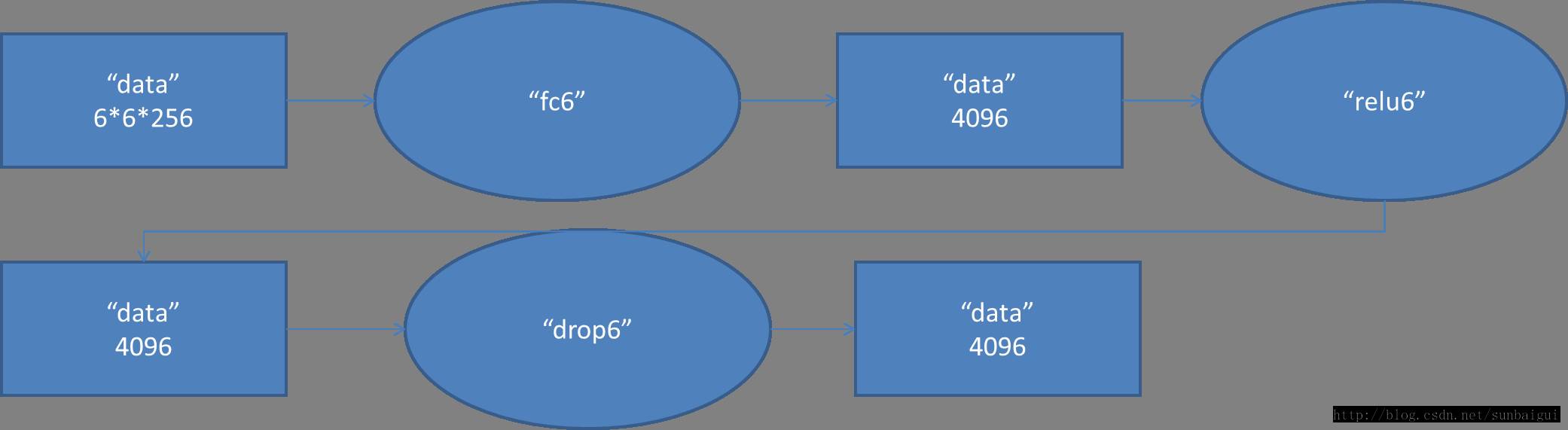
这里有一层特殊的dropout层,在alexnet中是说在训练的以1/2概率使得隐藏层的某些neuron的输出为0,这样就丢到了一半节点的输出,BP的时候也不更新这些节点。
(7) fc - relu - dropout
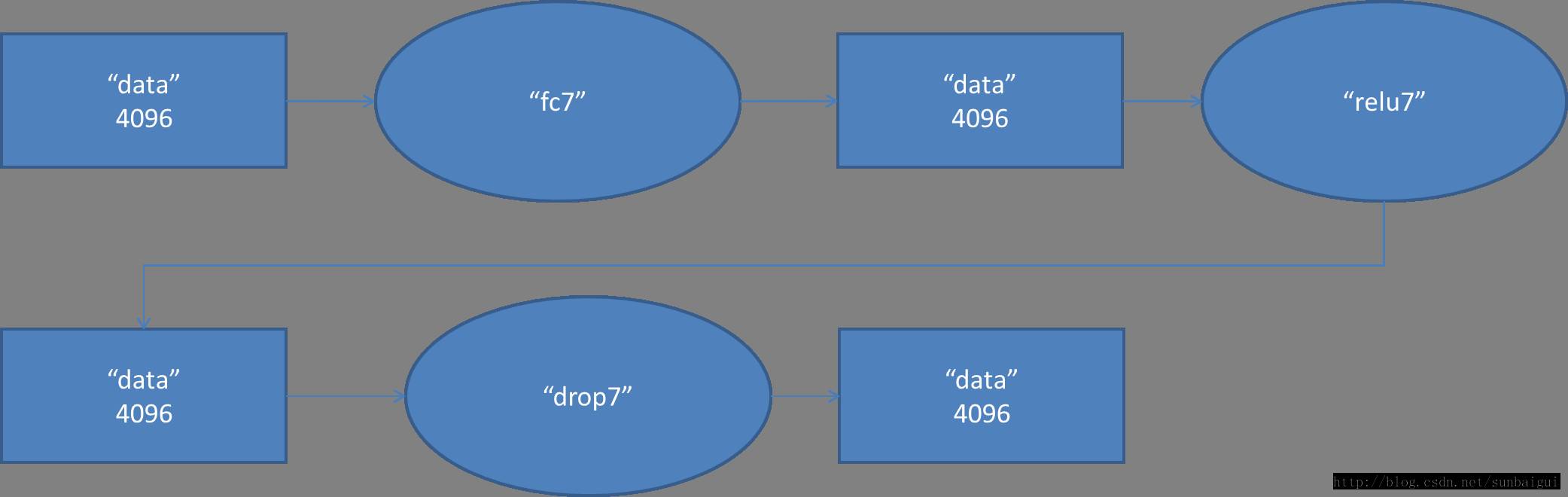
(8)fc - softmax

from torch import nn
class AlexNet(nn.Module):
def __init__(self,num_class=2):
nn.Module.__init__(self)
self.features = nn.Sequential(
#conv1
nn.Conv2d(3,96,kernel_size=11,stride=4),
nn.ReLU(inplace=True),#对原变量进行覆盖
nn.MaxPool2d(kernel_size=3,stride=2),
nn.ReLU(inplace=True),
#conv2
nn.Conv2d(96,256,kernel_size=5,padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3,stride=2),
nn.ReLU(inplace=True),
#conv3
nn.Conv2d(256,384,kernel_size=3,padding=1),
nn.ReLU(inplace=True),
#conv4
nn.Conv2d(384,384,kernel_size=3,padding=1),
nn.ReLU(inplace=True),
#conv5
nn.Conv2d(384,256,kernel_size=3,padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3,stride=2)
)
self.classifier = nn.Sequential(
#fc6
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
#fc7
nn.Linear(4096,4096),
nn.ReLU(inplace=True),
nn.Dropout(),
#fc8
nn.Linear(4096,num_class)
)
def forward(self,x):
x = self.features(x)
x = x.view(x.size(0),256 * 6 * 6)
x = self.classifier(x)
return x