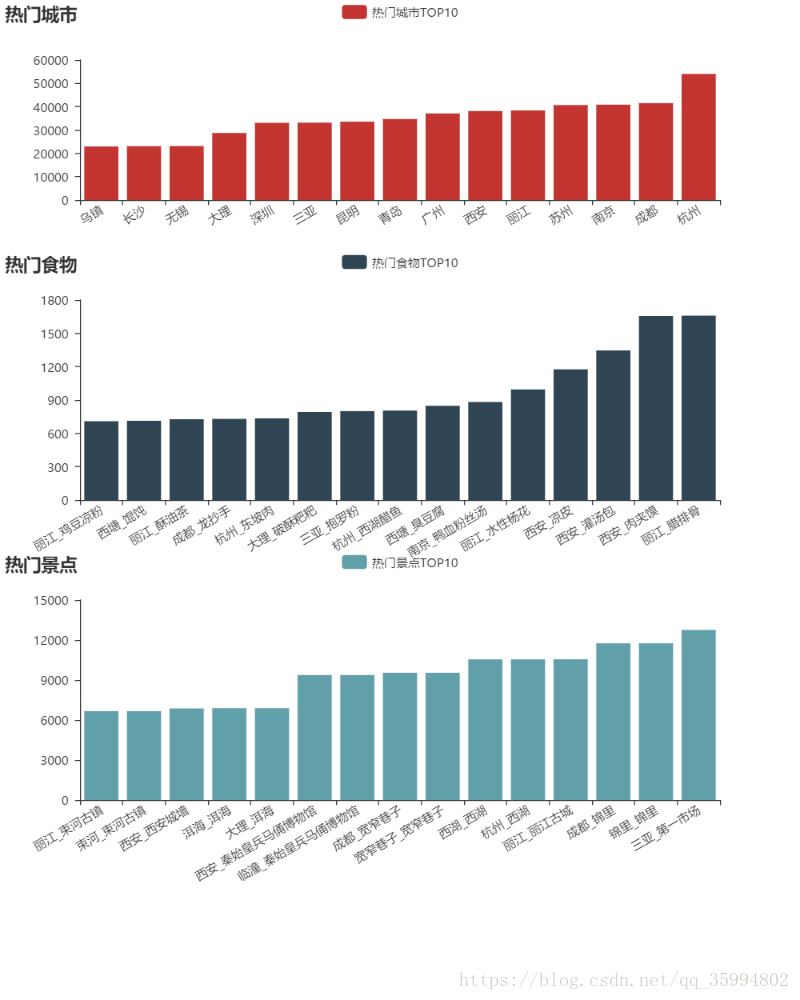
完整代码https://github.com/wkd-lidashuang/py-/tree/master/mafengwo
- 获得热门省编号和直辖市编号
蚂蜂窝中的所有城市、景点以及其他都有一个专属的5位数字编号,我们第一步要做的就是获取城市(直辖市+地级市)的编号,进行后续的进一步分析
先获得热门目的地,提取直辖市和省编码
def find_province_url(url):
html = get_html_text(url)
soup = BeautifulSoup(html, 'lxml')
municipality_directly_info(soup) # 处理直辖市信息
dts = soup.find('div', class_='hot-list clearfix').find_all('dt')
name = []
provice_id = []
urls = []
print('正在处理非直辖市信息')
for dt in dts:
all_a = dt.find_all('a')
for a in all_a:
name.append(a.text)
link = a.attrs['href']
provice_id.append(re.search(r'/(\d.*).html', link).group(1)) # 得到这个省的编码
# 得到这个省的热门城市链接
data_cy_p = link.replace('travel-scenic-spot/mafengwo', 'mdd/citylist')
urls.append(parse.urljoin(url, data_cy_p))
return name, provice_id, urls
由省编号得到热门城市编号,去过人数,
def parse_city_info(response):
text = response.json()['list']
soup = BeautifulSoup(text, 'lxml')
items = soup.find_all('li', class_="item")
info = []
nums = 0
for item in items:
city = {}
city['city_id'] = item.find('a').attrs['data-id']
city['city_name'] = item.find('div', class_='title').text.split()[0]
city['nums'] = int(item.find('b').text)
nums += city['nums']
info.append(city)
return info, nums
def func(page, provice_id):
print(f'解析{page}页信息')
data = {'mddid': provice_id, 'page': page}
response = requests.post('http://www.mafengwo.cn/mdd/base/list/pagedata_citylist', data=data)
info, nums = parse_city_info(response) # 得到每个景点城市的具体名字, 链接, 多人少去过
return (info, nums)
def parse_city_url(html, provice_id):
provice_info = {}
soup = BeautifulSoup(html, 'lxml')
pages = int(soup.find(class_="pg-last _j_pageitem").attrs['data-page']) # 这个省总共有多少页热门城市
city_info = []
sum_nums = 0 # 用来记录这个省的总流量
tpool = ThreadPoolExecutor(20)
obj = []
for page in range(1, pages + 1): # 解析页面发现是个post请求
t = tpool.submit(func, page, provice_id)
obj.append(t)
tpool.shutdown()
for i in obj:
info, nums = i.result()
sum_nums += nums
city_info.extend(info)
provice_info['sum_num'] = sum_nums
provice_info['citys'] = city_info
return provice_info
- 城市编号得到每个获得城市信息(饮食,景点)
def get_city_food(self, id_):
url = 'http://www.mafengwo.cn/cy/' + id_ + '/gonglve.html'
print(f'正在解析{url}')
soup = self.get_html_soup(url)
list_rank = soup.find('ol', class_='list-rank')
food = [k.text for k in list_rank.find_all('h3')]
food_count = [int(k.text) for k in list_rank.find_all('span', class_='trend')]
food_info = []
for i, j in zip(food, food_count):
fd = {}
fd['food_name'] = i
fd['food_count'] = j
food_info.append(fd)
return food_info
def get_city_jd(self, id_):
"""
:param id_:城市编码id
:return: 景点名称和评论数量
"""
url = 'http://www.mafengwo.cn/jd/' + id_ + '/gonglve.html'
print(f'正在解析{url}')
soup = self.get_html_soup(url)
jd_info = []
try:
all_h3 = soup.find('div', class_='row-top5').find_all('h3')
except:
print('没有景点')
jd = {}
jd['jd_name'] = ''
jd['jd_count'] = 0
jd_info.append(jd)
return jd_info
for h3 in all_h3:
jd = {}
jd['jd_name'] = h3.find('a')['title']
try:
jd['jd_count'] = int(h3.find('em').text)
except:
print('没有评论')
jd['jd_count'] = 0
jd_info.append(jd)
return jd_info
- 数据分析