这是帮忙工商学院研究生院旅游管理专业的舒老师弄的一个爬虫项目,简单的说算是三个网站一起的爬虫,分别爬取携程网、大众点评和马蜂窝马蜂窝的差评信息,仅限于差评,用于论文研究;上次曾有幸受他邀请,教研究生学长学姐们怎么用python做爬虫,但是爬虫的很多反爬和信息处理能力不是一两天的时间就可以让小白入门的。比如fa这三个网站,都有一些反爬虫,特别是大众点评,字体反爬,爬虫软件几乎拿它没辙,最多拿到缺失的内容。为了开发速度,我也没有去研究携程网和马蜂窝的ajax加载,直接选择了最为粗暴的selenium自动化。其中在点击网页节点上也是费了一些功夫,虽然不就前也弄过它们,但是很多反爬的措施也更新的很快,只能重新开发了。经过这个时间的学习,虽然进步了很多,在爬虫上,更加相信一定要学好js了。中国加油,武汉加油 ,我也加油~ ~ ~
目标文件和运行结果下载: https://www.lanzous.com/i9f3xwh
- 目标文件如图:
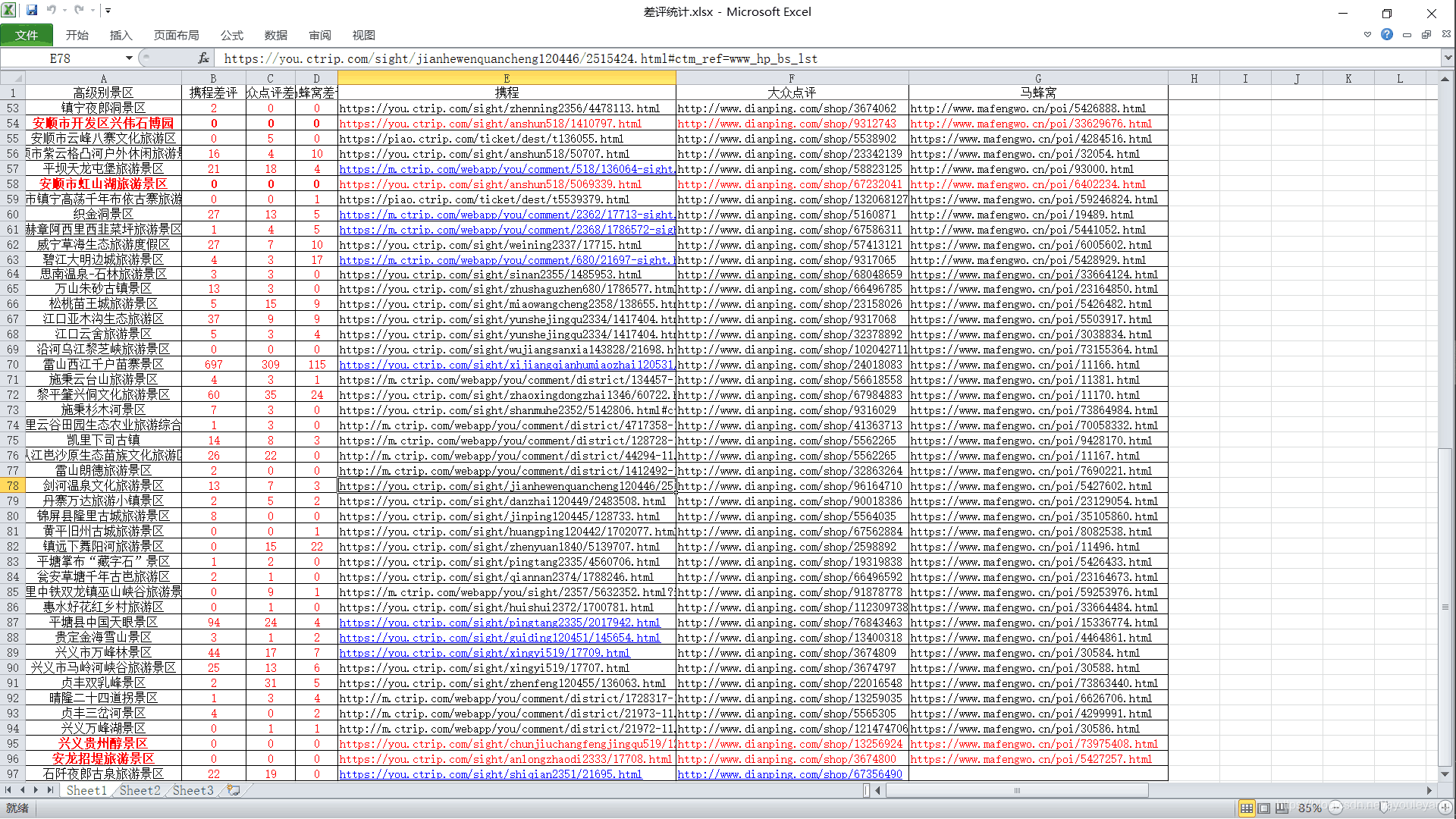
任务: 需要爬取表格中对应的链接,并把爬取的内容存在和景点对应的txt文件中,如果评论数为0,则不需要爬取。
1、携程网
1.1、PC端差评代码
import requests,json,time,random
from fake_useragent import UserAgent
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.chrome.options import Options
from lxml import etree
from lxml import html
import pandas as pd
startTime = time.time() #记录起始时间
driver = webdriver.Chrome()
driver.implicitly_wait(5)
chrome_option = webdriver.ChromeOptions()
chrome_option.add_argument('--proxy--server=112.84.55.122:9999')#使用代理IP
def you_ctrip(file_name, xc_url):
driver.get(xc_url)
driver.implicitly_wait(10)
driver.execute_script("window.scrollBy(0,1600)")
driver.implicitly_wait(5)
# 点击差评
button = driver.find_element_by_xpath('//*[@id="weiboCom1"]/div[2]/ul/li[5]/a')
driver.execute_script("$(arguments[0]).click()",button)
driver.implicitly_wait(5)
driver.execute_script("window.scrollBy(0,1000)")
try:
PageNunber = driver.find_element_by_xpath('//div[@class="pager_v1"]/span/b').text
except:
PageNunber = False
source = driver.page_source
you_ctrip_spider(source, file_name)
if PageNunber:
print ("PageNunber = ", PageNunber)
for i in range(2, int(PageNunber)+1):
time.sleep(2)
print ("@"*50)
search = driver.find_element_by_id('gopagetext') #定位搜索框节点
search.send_keys(i)#输入搜素词
search.send_keys(Keys.ENTER)#点击回车
driver.execute_script("window.scrollBy(0,10000)")
time.sleep(1)
source = driver.page_source
you_ctrip_spider(source, file_name)
button = driver.find_element_by_xpath('//*[@id="weiboCom1"]/div[2]/ul/li[6]/a')
driver.execute_script("$(arguments[0]).click()",button)
driver.implicitly_wait(5)
try:
PageNunber = driver.find_element_by_xpath('//div[@class="pager_v1"]/span/b').text
except:
PageNunber = False
# 获取源码并解析
source = driver.page_source
you_ctrip_spider(source, file_name)
if PageNunber:
print ("PageNunber = ", PageNunber)
for i in range(2, int(PageNunber)+1):
time.sleep(2)
print ("@"*50)
search = driver.find_element_by_id('gopagetext') #定位搜索框节点
search.send_keys(i)#输入搜素词
search.send_keys(Keys.ENTER)#点击回车
driver.execute_script("window.scrollBy(0,10000)")
time.sleep(1)
# 获取源码并解析
source = driver.page_source
you_ctrip_spider(source, file_name)
def you_ctrip_spider(source, file_name):
xc_html = html.fromstring(source)
# 提取全部评论
xc_user_comments = xc_html.xpath('//li[@class="main_con"]/span/text()')
xc_user_comment = "".join(xc_user_comments)
print ("xc_user_comment = ", xc_user_comment)
with open(file_name, "a", encoding="utf-8") as f:
f.write(xc_user_comment+"\n")
f.close()
def main():
file_name = './景点差评测试.txt'
max_comment = 41
if int(max_comment) != 0:
maxSlide = int(max_comment / 10)
xc_url = "https://you.ctrip.com/sight/guiding120451/145654.html"
if "sight" in xc_url:
you_ctrip(file_name, xc_url)
if __name__ == '__main__':
main()
1.2、移动端差评代码
import requests,json,time,random
from fake_useragent import UserAgent
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from lxml import etree
from lxml import html
import pandas as pd
# 读取表格
data = pd.read_excel('./差评统计.xlsx')
startTime = time.time() #记录起始时间
driver = webdriver.Chrome()
driver.implicitly_wait(5)
chrome_option = webdriver.ChromeOptions()
chrome_option.add_argument('--proxy--server=112.84.55.122:9999')#使用代理IP
def spider_xiecheng(maxSlide, file_name, xc_url):
driver.get(xc_url+ '&tag=-12') # &tag=-12是网页上差评的标签
# print ("maxSlide===========================", maxSlide)
# selenium下拉滚动条
if int(maxSlide) > 0:
# print ("$"*50)
for i in range(0, int(maxSlide)):
driver.execute_script("window.scrollTo(0,10000)")
time.sleep(1) #暂停时间:2~3秒
# 获取源码并解析
time.sleep(2)
source = driver.page_source
xc_html = html.fromstring(source)
# 提取全部评论
xc_user_comments = xc_html.xpath('//*[@id="c_gs_comments_commentdetail"]//text()')
xc_user_comment = "".join(xc_user_comments)
# print ("xc_user_comment = ", xc_user_comment)
# 提取全部回复
seller_replys = xc_html.xpath('//div[@class="seller-reply"]//text()')
seller_reply = "".join(seller_replys)
# print ("seller-reply = ", seller_reply)
# 保存数据
with open(file_name, "a", encoding="utf-8") as f:
f.write(xc_user_comment+"\n")
f.write(seller_reply+"\n")
f.close()
def main():
for i in range(0,96):
# print (data['高级别景区'][i], data['携程差评'][i], data['携程'][i])
file_name = './景点差评/'+str(data['高级别景区'][i]) + '.txt'
max_comment = int(data['携程差评'][i])
if int(max_comment) != 0:
maxSlide = int(max_comment / 10)
xc_url = data['携程'][i]
spider_xiecheng(maxSlide, file_name, xc_url)
else:
print ("携程网《%s》没有差评"%(data['高级别景区'][i]))
print ("正在爬取第%s个目标,一共有97个目标"%(i+1))
if __name__ == '__main__':
main()
1.3、PC端和移动端一起运行
注意:表格中携程网的链接不统一,有移动端和PC端,所以要分开进行爬取
import requests,json,time,random
from fake_useragent import UserAgent
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from lxml import etree
from lxml import html
import pandas as pd
data = pd.read_excel('./差评统计.xlsx')
startTime = time.time() #记录起始时间
driver = webdriver.Chrome()
driver.implicitly_wait(5)
chrome_option = webdriver.ChromeOptions()
chrome_option.add_argument('--proxy--server=112.84.55.122:9999')#使用代理IP
def you_ctrip(file_name, xc_url):
driver.get(xc_url)
driver.implicitly_wait(10)
driver.execute_script("window.scrollBy(0,1600)")
driver.implicitly_wait(5)
# 点击差评
button = driver.find_element_by_xpath('//*[@id="weiboCom1"]/div[2]/ul/li[5]/a')
driver.execute_script("$(arguments[0]).click()",button)
driver.implicitly_wait(5)
driver.execute_script("window.scrollBy(0,1000)")
try:
PageNunber = driver.find_element_by_xpath('//div[@class="pager_v1"]/span/b').text
except:
PageNunber = False
source = driver.page_source
you_ctrip_spider(source, file_name)
if PageNunber:
# print ("PageNunber = ", PageNunber)
for i in range(2, int(PageNunber)+1):
time.sleep(2)
# print ("@"*50)
search = driver.find_element_by_id('gopagetext') #定位搜索框节点
search.send_keys(i)#输入搜素词
search.send_keys(Keys.ENTER)#点击回车
driver.execute_script("window.scrollBy(0,10000)")
time.sleep(1)
source = driver.page_source
you_ctrip_spider(source, file_name)
button = driver.find_element_by_xpath('//*[@id="weiboCom1"]/div[2]/ul/li[6]/a')
driver.execute_script("$(arguments[0]).click()",button)
driver.implicitly_wait(5)
try:
PageNunber = driver.find_element_by_xpath('//div[@class="pager_v1"]/span/b').text
except:
PageNunber = False
# 获取源码并解析
source = driver.page_source
you_ctrip_spider(source, file_name)
if PageNunber:
# print ("PageNunber = ", PageNunber)
for i in range(2, int(PageNunber)+1):
time.sleep(2)
# print ("@"*50)
search = driver.find_element_by_id('gopagetext') #定位搜索框节点
search.send_keys(i)#输入搜素词
search.send_keys(Keys.ENTER)#点击回车
driver.execute_script("window.scrollBy(0,10000)")
time.sleep(1)
# 获取源码并解析
source = driver.page_source
you_ctrip_spider(source, file_name)
def you_ctrip_spider(source, file_name):
xc_html = html.fromstring(source)
# 提取全部评论
xc_user_comments = xc_html.xpath('//li[@class="main_con"]/span/text()')
xc_user_comment = "".join(xc_user_comments)
# print ("xc_user_comment = ", xc_user_comment)
with open(file_name, "a", encoding="utf-8") as f:
f.write(xc_user_comment+"\n")
f.close()
def spider_xiecheng(maxSlide, file_name, xc_url):
driver.get(xc_url+ '&tag=-12')
# print ("maxSlide===========================", maxSlide)
# selenium下拉滚动条
if int(maxSlide) > 0:
#下拉网页
for i in range(0, int(maxSlide)):
js = "window.scrollTo(0, document.body.scrollHeight)"
driver.execute_script(js)
time.sleep(1) #暂停时间:2~3秒
# 获取源码并解析
time.sleep(2)
source = driver.page_source
xc_html = html.fromstring(source)
# 提取全部评论
xc_user_comments = xc_html.xpath('//*[@id="c_gs_comments_commentdetail"]//text()')
xc_user_comment = "".join(xc_user_comments)
# print ("xc_user_comment = ", xc_user_comment)
# 提取全部回复
seller_replys = xc_html.xpath('//div[@class="seller-reply"]//text()')
seller_reply = "".join(seller_replys)
# print ("seller-reply = ", seller_reply)
# 保存数据
with open(file_name, "a", encoding="utf-8") as f:
f.write(xc_user_comment+"\n")
f.write(seller_reply+"\n")
f.close()
def main():
for i in range(55, 96):#38,96
# print (data['高级别景区'][i], data['携程差评'][i], data['携程'][i])
file_name = './评论/'+str(data['高级别景区'][i]) + '.txt' # 景点差评/
max_comment = int(data['携程差评'][i])
if int(max_comment) != 0:
maxSlide = int(max_comment / 10)
xc_url = data['携程'][i]
print (data['高级别景区'][i], xc_url)
if "you.ctrip" in xc_url:
you_ctrip(file_name, xc_url)
if "m.ctrip" in xc_url:
spider_xiecheng(maxSlide, file_name, xc_url)
else:
print ("携程网《%s》没有差评"%(data['高级别景区'][i]))
print ("正在爬取第%s个目标,一共有97个目标"%(i+1))
if __name__ == '__main__':
main()
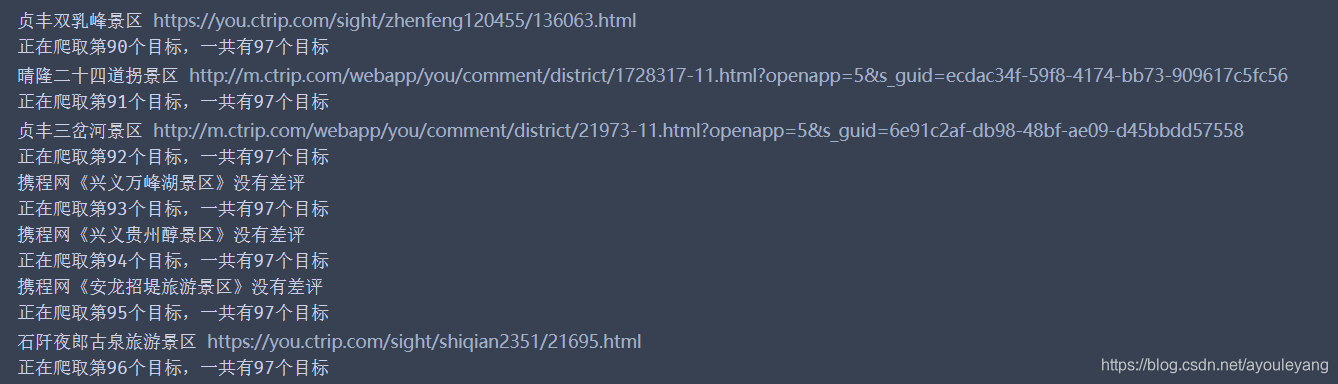
PC和移动一起运行结果截图:
2、大众点评代码
这是在网上找的一个代码,很是倾佩这位大神,感觉写出了史诗级的爬虫,目前有些地方还没有搞懂,下一步就以这个为目标啦!
#!/usr/bin/env python
# coding: utf-8
import datetime
import random
import time
import re
from selenium.webdriver.chrome.options import Options
from selenium import webdriver
import pymongo
from lxml import etree
import requests
from pyquery import PyQuery as pq
client = pymongo.MongoClient('localhost',27017)
shidai = client['gongyuan']
comments = shidai['comments']
path_one = r'./chromedriver.exe'
COOKIES ='_lxsdk_cuid=16a3e5550cac8-0328ac989f3a72-3c644d0e-100200-16a3e5550cbc8; _lxsdk=16a3e5550cac8-0328ac989f3a72-3c644d0e-100200-16a3e5550cbc8; _hc.v=b108378a-8f67-0f82-24be-f6bd59936218.1555823941; s_ViewType=10; ua=zeroing; ctu=66a794ac79d236ecce433a9dd7bbb8bf29eff0bc049590703a72f844379eb7c5; dper=56648ebad0a12bed853d89482e9f3c35c89ef2504f07d5388fd0dfead6018398ae8c14a81efb6f9e42cb7e1f46473489252facff635921c09c106e3b36b311bafcd118a3e618fff67b5758b9bd5afca901c01dc9ec74027240ac50819479e9fc; ll=7fd06e815b796be3df069dec7836c3df; _lx_utm=utm_source%3Dgoogle%26utm_medium%3Dorganic; cy=2; cye=beijing; _lxsdk_s=16b84e44244-3d8-afd-795%7C1393851569%7C2'
f = open('./大众点评之白云图书馆.txt','wb+')
class DianpingComment:
font_size = 14
start_y = 23
def __init__(self, shop_id, cookies, delay=7, handle_ban=True,comments =comments):
self.shop_id = shop_id
self._delay = delay
self.num = 1
self.db =comments
self._cookies = self._format_cookies(cookies)
self._css_headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'
}
self._default_headers = {
'Connection': 'keep-alive',
'Host': 'www.dianping.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36',
'Cookie':'_lxsdk_cuid=17047b1dca7c8-043c82f4977c0c-313f69-144000-17047b1dca8c8; _lxsdk=17047b1dca7c8-043c82f4977c0c-313f69-144000-17047b1dca8c8; _hc.v=8153ac08-3810-a1ae-e4a2-008446a9d6de.1581750804; dplet=0eb3ace34c81cdffbb2f525361af2dfe; dper=25d6344a89e2764310f17c768a342af6e26a0b970e352c4b7e1af7d055dd4f0fe27238f776757d0692e2b2057163d865dbac58eaaa644cd70bc1add585e3887a57646c5450f2ac8de9999ddbbb0b420dac991ff387517e3bab3bea6092fb494b; ua=dpuser_2307823987; ctu=60e486a44aca8c99b326d5acbeed5a4a2c97a82d1f07352d412ad90603dacb2b; cy=258; cye=guiyang; s_ViewType=10; ll=7fd06e815b796be3df069dec7836c3df; _lxsdk_s=1704bedf674-3f2-00a-b95%7C%7C26' }
self._cur_request_url ='http://www.dianping.com/shop/{}/review_all?queryType=reviewGrade&queryVal=bad'.format(self.shop_id)
self.sub_url ='http://www.dianping.com'
def run(self):
self._css_link = self._get_css_link(self._cur_request_url)
self._font_dict = self._get_font_dict(self._css_link)
self._get_conment_page()
def _delay_func(self):
delay_time = random.randint((self._delay - 2) * 10, (self._delay + 2) * 10) * 0.1
time.sleep(delay_time)
def _init_browser(self):
"""
初始化游览器
"""
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
browser = webdriver.Chrome(chrome_options=chrome_options,executable_path=path_one)
browser.get(self._cur_request_url)
for name, value in self._cookies.items():
browser.add_cookie({'name': name, 'value': value})
browser.refresh()
return browser
def _handle_ban(self):
"""
爬取速度过快,出现异常时处理验证
"""
try:
self._browser.refresh()
time.sleep(1)
button = self._browser.find_element_by_id('yodaBox')
move_x_offset = self._browser.find_element_by_id('yodaBoxWrapper').size['width']
webdriver.ActionChains(self._browser).drag_and_drop_by_offset(
button, move_x_offset, 0).perform()
except:
pass
def _format_cookies(self, cookies):
'''
获取cookies;;;
:param cookies:
:return:
'''
cookies = {cookie.split('=')[0]: cookie.split('=')[1]
for cookie in cookies.replace(' ', '').split(';')}
return cookies
def _get_conment_page(self):
"""
请求评论页,并将<span></span>样式替换成文字;
"""
while self._cur_request_url:
self._delay_func()
print('[{now_time}] {msg}'.format(now_time=datetime.datetime.now(), msg=self._cur_request_url))
res = requests.get(self._cur_request_url, headers=self._default_headers, cookies=self._cookies)
while res.status_code !=200:
cookie = random.choice(COOKIES)
cookies = self._format_cookies(cookie)
res = requests.get(self._cur_request_url, headers=self._default_headers, cookies=cookies)
if res.status_code == 200:
break
html = res.text
class_set = []
for span in re.findall(r'<svgmtsi class="([a-zA-Z0-9]{5,6})"></svgmtsi>', html):
class_set.append(span)
for class_name in class_set:
try:
html = re.sub('<svgmtsi class="%s"></svgmtsi>' % class_name, self._font_dict[class_name], html)
print('{}已替换完毕_______________________________'.format(self._font_dict[class_name]))
except:
html = re.sub('<svgmtsi class="%s"></svgmtsi>' % class_name, '', html)
print('替换失败…………………………………………………………………………&&&&&&&&&&&&&&&&&&&&&&&&')
doc = pq(html)
self._parse_comment_page(html)
if doc('.NextPage').attr('href'):
self._default_headers['Referer'] = self._cur_request_url
next_page_url1 = doc('.NextPage').attr('href')
next_page_url =self.sub_url + str(next_page_url1)
print('next_url:{}'.format(next_page_url))
else:
next_page_url = None
print('next_page_url:{}'.format(next_page_url))
self._cur_request_url = next_page_url
def _data_pipeline(self, data):
"""
处理数据
"""
print(data)
def _parse_comment_page(self, html):
"""
解析评论页并提取数据,把数据写入文件中;;
"""
doc =pq(html)
for li in doc('div.review-list-main > div.reviews-wrapper > div.reviews-items > ul > li'):
doc_text =pq(li)
if doc_text('.dper-info .name').text():
name = doc_text('.dper-info .name').text()
else:
name = None
try:
star = doc_text('.review-rank .sml-rank-stars').attr('class')
except IndexError:
star = None
if doc_text('div.misc-info.clearfix > .time').text():
date_time =doc_text('div.misc-info.clearfix > .time').text()
else:
date_time=None
if doc_text('.main-review .review-words').text():
comment =doc_text('.main-review .review-words').text()
else:
comment=None
# data = {
# 'name': name,
# 'date_time':date_time,
# 'star': star,
# 'comment':comment
# }
print(comment)
f.write(str(comment.replace("收起评论","\n")).encode('utf-8'))
print('写入数据完成',comment)
def _get_css_link(self, url):
"""
请求评论首页,获取css样式文件
"""
try:
print(url)
res = requests.get(url, headers=self._default_headers, cookies = self._cookies)
html = res.text
css_link = re.search(r'<link re.*?css.*?href="(.*?svgtextcss.*?)">', html)
print(css_link)
assert css_link
css_link = 'http:' + css_link[1]
return css_link
except:
None
def _get_font_dict(self, url):
"""
获取css样式对应文字的字典
"""
res = requests.get(url, headers=self._css_headers)
html = res.text
background_image_link = re.findall(r'background-image:.*?\((.*?svg)\)', html)
print(background_image_link)
background_image_link_list =[]
for i in background_image_link:
url ='http:'+i
background_image_link_list.append(url)
print(background_image_link_list)
html = re.sub(r'span.*?\}', '', html)
group_offset_list = re.findall(r'\.([a-zA-Z0-9]{5,6}).*?round:(.*?)px (.*?)px;', html)
'''
多个偏移字典,合并在一起;;;
'''
font_dict_by_offset_list ={}
for i in background_image_link_list:
font_dict_by_offset_list.update(self._get_font_dict_by_offset(i))
font_dict_by_offset = font_dict_by_offset_list
print(font_dict_by_offset)
font_dict = {}
for class_name, x_offset, y_offset in group_offset_list:
x_offset = x_offset.replace('.0', '')
y_offset = y_offset.replace('.0', '')
try:
font_dict[class_name] = font_dict_by_offset[int(y_offset)][int(x_offset)]
except:
font_dict[class_name] = ''
return font_dict
def _get_font_dict_by_offset(self, url):
"""
获取坐标偏移的文字字典, 会有最少两种形式的svg文件(目前只遇到两种)
"""
res = requests.get(url, headers=self._css_headers)
html = res.text
font_dict = {}
y_list = re.findall(r'd="M0 (\d+?) ', html)
if y_list:
font_list = re.findall(r'<textPath .*?>(.*?)<', html)
for i, string in enumerate(font_list):
y_offset = self.start_y - int(y_list[i])
sub_font_dict = {}
for j, font in enumerate(string):
x_offset = -j * self.font_size
sub_font_dict[x_offset] = font
font_dict[y_offset] = sub_font_dict
else:
font_list = re.findall(r'<text.*?y="(.*?)">(.*?)<', html)
for y, string in font_list:
y_offset = self.start_y - int(y)
sub_font_dict = {}
for j, font in enumerate(string):
x_offset = -j * self.font_size
sub_font_dict[x_offset] = font
font_dict[y_offset] = sub_font_dict
return font_dict
class Customer(DianpingComment):
def _data_pipeline(self, data):
print(data)
if __name__ == "__main__":
# 链接后面的ID
dianping = Customer('22062688', cookies=COOKIES)
dianping.run()
f.close()
PS: 该代码仅供学习,如果侵犯您的权益,请下方评论删除!
稍改动了一些地方,直接就可以跑表格中的数据了
#!/usr/bin/env python
# coding: utf-8
import datetime
import random
import time
import re
from selenium.webdriver.chrome.options import Options
from selenium import webdriver
import pymongo
from lxml import etree
import requests
from pyquery import PyQuery as pq
startTime = time.time()
client = pymongo.MongoClient('localhost',27017)
shidai = client['gongyuan']
comments = shidai['comments']
path_one = r'./chromedriver.exe'
COOKIES ='_lxsdk_cuid=16a3e5550cac8-0328ac989f3a72-3c644d0e-100200-16a3e5550cbc8; _lxsdk=16a3e5550cac8-0328ac989f3a72-3c644d0e-100200-16a3e5550cbc8; _hc.v=b108378a-8f67-0f82-24be-f6bd59936218.1555823941; s_ViewType=10; ua=zeroing; ctu=66a794ac79d236ecce433a9dd7bbb8bf29eff0bc049590703a72f844379eb7c5; dper=56648ebad0a12bed853d89482e9f3c35c89ef2504f07d5388fd0dfead6018398ae8c14a81efb6f9e42cb7e1f46473489252facff635921c09c106e3b36b311bafcd118a3e618fff67b5758b9bd5afca901c01dc9ec74027240ac50819479e9fc; ll=7fd06e815b796be3df069dec7836c3df; _lx_utm=utm_source%3Dgoogle%26utm_medium%3Dorganic; cy=2; cye=beijing; _lxsdk_s=16b84e44244-3d8-afd-795%7C1393851569%7C2'
class DianpingComment:
font_size = 14
start_y = 23
def __init__(self, shop_id, cookies, delay=7, handle_ban=True,comments =comments):
self.shop_id = shop_id
self._delay = delay
self.num = 1
self.db =comments
self._cookies = self._format_cookies(cookies)
self._css_headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'
}
self._default_headers = {
'Connection': 'keep-alive',
'Host': 'www.dianping.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36',
'Cookie':'_lxsdk_cuid=17047b1dca7c8-043c82f4977c0c-313f69-144000-17047b1dca8c8; _lxsdk=17047b1dca7c8-043c82f4977c0c-313f69-144000-17047b1dca8c8; _hc.v=8153ac08-3810-a1ae-e4a2-008446a9d6de.1581750804; dplet=0eb3ace34c81cdffbb2f525361af2dfe; dper=25d6344a89e2764310f17c768a342af6e26a0b970e352c4b7e1af7d055dd4f0fe27238f776757d0692e2b2057163d865dbac58eaaa644cd70bc1add585e3887a57646c5450f2ac8de9999ddbbb0b420dac991ff387517e3bab3bea6092fb494b; ua=dpuser_2307823987; ctu=60e486a44aca8c99b326d5acbeed5a4a2c97a82d1f07352d412ad90603dacb2b; cy=258; cye=guiyang; s_ViewType=10; ll=7fd06e815b796be3df069dec7836c3df; _lxsdk_s=1704bedf674-3f2-00a-b95%7C%7C26' }
self._cur_request_url ='http://www.dianping.com/shop/{}/review_all?queryType=reviewGrade&queryVal=bad'.format(self.shop_id)
self.sub_url ='http://www.dianping.com'
def run(self):
self._css_link = self._get_css_link(self._cur_request_url)
self._font_dict = self._get_font_dict(self._css_link)
self._get_conment_page()
def _delay_func(self):
delay_time = random.randint((self._delay - 2) * 10, (self._delay + 2) * 10) * 0.1
time.sleep(delay_time)
def _init_browser(self):
"""
初始化游览器
"""
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
browser = webdriver.Chrome(chrome_options=chrome_options,executable_path=path_one)
browser.get(self._cur_request_url)
for name, value in self._cookies.items():
browser.add_cookie({'name': name, 'value': value})
browser.refresh()
return browser
def _handle_ban(self):
"""
爬取速度过快,出现异常时处理验证
"""
try:
self._browser.refresh()
time.sleep(1)
button = self._browser.find_element_by_id('yodaBox')
move_x_offset = self._browser.find_element_by_id('yodaBoxWrapper').size['width']
webdriver.ActionChains(self._browser).drag_and_drop_by_offset(
button, move_x_offset, 0).perform()
except:
pass
def _format_cookies(self, cookies):
'''
获取cookies;;;
:param cookies:
:return:
'''
cookies = {cookie.split('=')[0]: cookie.split('=')[1]
for cookie in cookies.replace(' ', '').split(';')}
return cookies
def _get_conment_page(self):
"""
请求评论页,并将<span></span>样式替换成文字;
"""
while self._cur_request_url:
self._delay_func()
# print('[{now_time}] {msg}'.format(now_time=datetime.datetime.now(), msg=self._cur_request_url))
res = requests.get(self._cur_request_url, headers=self._default_headers, cookies=self._cookies)
while res.status_code !=200:
cookie = random.choice(COOKIES)
cookies = self._format_cookies(cookie)
res = requests.get(self._cur_request_url, headers=self._default_headers, cookies=cookies)
if res.status_code == 200:
break
html = res.text
class_set = []
for span in re.findall(r'<svgmtsi class="([a-zA-Z0-9]{5,6})"></svgmtsi>', html):
class_set.append(span)
for class_name in class_set:
try:
html = re.sub('<svgmtsi class="%s"></svgmtsi>' % class_name, self._font_dict[class_name], html)
# print('{}已替换完毕_______________________________'.format(self._font_dict[class_name]))
except:
html = re.sub('<svgmtsi class="%s"></svgmtsi>' % class_name, '', html)
# print('替换失败…………………………………………………………………………&&&&&&&&&&&&&&&&&&&&&&&&')
doc = pq(html)
self._parse_comment_page(html)
if doc('.NextPage').attr('href'):
self._default_headers['Referer'] = self._cur_request_url
next_page_url1 = doc('.NextPage').attr('href')
next_page_url =self.sub_url + str(next_page_url1)
# print('next_url:{}'.format(next_page_url))
else:
next_page_url = None
# print('next_page_url:{}'.format(next_page_url))
self._cur_request_url = next_page_url
def _data_pipeline(self, data):
"""
处理数据
"""
# print(data)
def _parse_comment_page(self, html):
"""
解析评论页并提取数据,把数据写入文件中;;
"""
doc =pq(html)
for li in doc('div.review-list-main > div.reviews-wrapper > div.reviews-items > ul > li'):
doc_text =pq(li)
if doc_text('.dper-info .name').text():
name = doc_text('.dper-info .name').text()
else:
name = None
try:
star = doc_text('.review-rank .sml-rank-stars').attr('class')
except IndexError:
star = None
if doc_text('div.misc-info.clearfix > .time').text():
date_time =doc_text('div.misc-info.clearfix > .time').text()
else:
date_time=None
if doc_text('.main-review .review-words').text():
comment =doc_text('.main-review .review-words').text()
else:
comment=None
# data = {
# 'name': name,
# 'date_time':date_time,
# 'star': star,
# 'comment':comment
# }
print(comment)
f.write(str(comment.replace("收起评论","\n")).encode('utf-8'))
# print('写入数据完成',comment)
def _get_css_link(self, url):
"""
请求评论首页,获取css样式文件
"""
try:
# print(url)
res = requests.get(url, headers=self._default_headers, cookies = self._cookies)
html = res.text
css_link = re.search(r'<link re.*?css.*?href="(.*?svgtextcss.*?)">', html)
# print(css_link)
assert css_link
css_link = 'http:' + css_link[1]
return css_link
except:
None
def _get_font_dict(self, url):
"""
获取css样式对应文字的字典
"""
res = requests.get(url, headers=self._css_headers)
html = res.text
background_image_link = re.findall(r'background-image:.*?\((.*?svg)\)', html)
# print(background_image_link)
background_image_link_list =[]
for i in background_image_link:
url ='http:'+i
background_image_link_list.append(url)
# print(background_image_link_list)
html = re.sub(r'span.*?\}', '', html)
group_offset_list = re.findall(r'\.([a-zA-Z0-9]{5,6}).*?round:(.*?)px (.*?)px;', html)
'''
多个偏移字典,合并在一起;;;
'''
font_dict_by_offset_list ={}
for i in background_image_link_list:
font_dict_by_offset_list.update(self._get_font_dict_by_offset(i))
font_dict_by_offset = font_dict_by_offset_list
# print(font_dict_by_offset)
font_dict = {}
for class_name, x_offset, y_offset in group_offset_list:
x_offset = x_offset.replace('.0', '')
y_offset = y_offset.replace('.0', '')
try:
font_dict[class_name] = font_dict_by_offset[int(y_offset)][int(x_offset)]
except:
font_dict[class_name] = ''
return font_dict
def _get_font_dict_by_offset(self, url):
"""
获取坐标偏移的文字字典, 会有最少两种形式的svg文件(目前只遇到两种)
"""
res = requests.get(url, headers=self._css_headers)
html = res.text
font_dict = {}
y_list = re.findall(r'd="M0 (\d+?) ', html)
if y_list:
font_list = re.findall(r'<textPath .*?>(.*?)<', html)
for i, string in enumerate(font_list):
y_offset = self.start_y - int(y_list[i])
sub_font_dict = {}
for j, font in enumerate(string):
x_offset = -j * self.font_size
sub_font_dict[x_offset] = font
font_dict[y_offset] = sub_font_dict
else:
font_list = re.findall(r'<text.*?y="(.*?)">(.*?)<', html)
for y, string in font_list:
y_offset = self.start_y - int(y)
sub_font_dict = {}
for j, font in enumerate(string):
x_offset = -j * self.font_size
sub_font_dict[x_offset] = font
font_dict[y_offset] = sub_font_dict
return font_dict
class Customer(DianpingComment):
def _data_pipeline(self, data):
print(data)
if __name__ == "__main__":
data = pd.read_excel('./差评统计.xlsx')
for i in range(40, 96):#0,96
file_name = './景点差评/'+str(data['高级别景区'][i]) + '.txt' # 景点差评/
max_comment = int(data['大众点评差评'][i])
if int(max_comment) != 0:
print (i, data['高级别景区'][i], data['大众点评'][i])
dzdp_id = str(data['大众点评'][i]).split("/shop/")[1]
f = open(file_name, 'wb+')
dianping = Customer(dzdp_id, cookies=COOKIES)
dianping.run()
f.close()
endTime = time.time()
sum_time = (endTime-startTime) / 60
print ("获取该信息一共用了%s分钟"%sum_time)
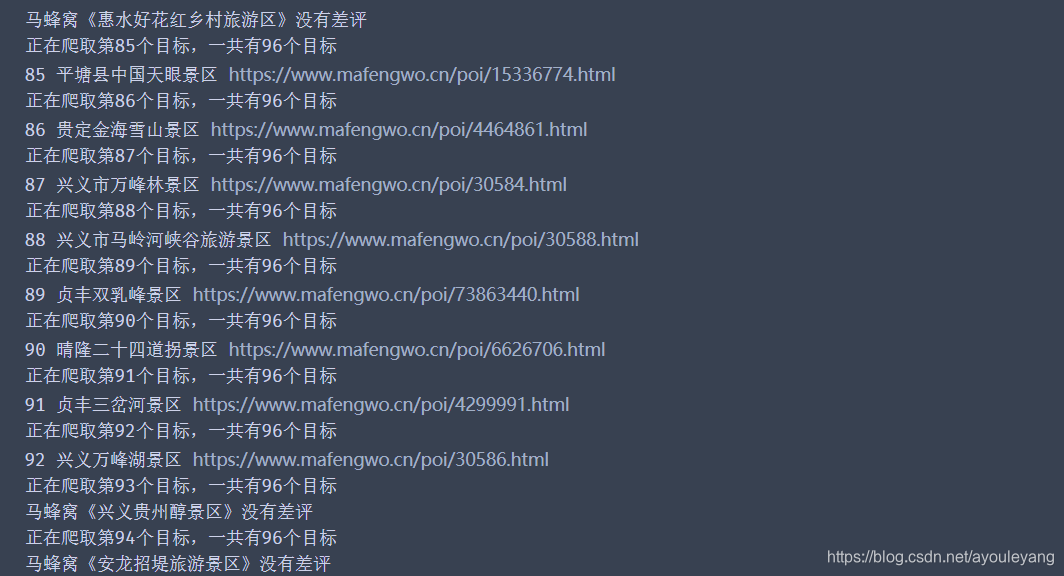
大众点评截图:

3、马蜂窝差评代码
from selenium import webdriver
import time
import requests
from lxml import etree
from lxml import html
import pandas as pd
startTime = time.time() #记录起始时间
driver = webdriver.Chrome()
driver.implicitly_wait(5)
chrome_option = webdriver.ChromeOptions()
chrome_option.add_argument('--proxy--server=112.84.55.122:9999')#使用代理IP
def spider_mafengwo(file_name, mfw_url):
driver.get(mfw_url)#打开马蜂窝
driver.implicitly_wait(6)#等待加载六秒
driver.find_element_by_xpath('//*[@id="poi-navbar"]/ul/li[3]/a').click() #点击蜂蜂评论
time.sleep(3)
driver.find_element_by_xpath('//div[@class="review-nav"]/ul/li[5]/a/span[1]').click() #点击差评
time.sleep(0.5)
# 获取源码并解析
driver.execute_script("window.scrollBy(0,3000)")
try:
maxPage = driver.find_element_by_xpath('//span[@class="count"]/span').text #获取最大页
except:
maxPage = False
if maxPage:
# print ("maxPage = ", maxPage)
for i in range(1, int(maxPage)):
time.sleep(1.5)
driver.find_element_by_link_text("后一页").click()
time.sleep(1)
get_mafengwo_txt(file_name)
else:
get_mafengwo_txt(file_name)
def get_mafengwo_txt(file_name):
time.sleep(1)
mfw_source = driver.page_source
mfw_html = html.fromstring(mfw_source)
# 爬取文本描述
# describes = mfw_html.xpath('//div[@class="summary"]//text()')
# describe = "".join(describes).replace(" ","").replace("\n","")
# print ("describe = ", describe)
# 提取全部评论
mfw_user_comments = mfw_html.xpath('//*[@id="c_gs_comments_commentdetail"]//text()')
mfw_user_comment = "".join(mfw_user_comments)
# print ("mfw_user_comment = ", mfw_user_comment)
# 爬取回复
rev_txts = mfw_html.xpath('//li[@class="rev-item comment-item clearfix"]//p//text()')
rev_txt = "".join(rev_txts)
# print ("rev_txt = ", rev_txt)
# 爬取回复的评论
comment_lists = mfw_html.xpath('//ul[@class="more_reply_box comment_list"]/li/text()')
comment_list = "".join(comment_lists).replace(" ","").replace("\n","")
# print ("comment_list = ", comment_list)
with open(file_name, 'a', encoding='utf-8') as f:
# f.write(describe+"\n")
f.write(mfw_user_comment+"\n")
f.write(rev_txt+"\n")
f.write(comment_list+"\n")
f.close()
def main():
data = pd.read_excel('./差评统计.xlsx')
for i in range(0, 96):#0,96
file_name = './景点差评/'+str(data['高级别景区'][i]) + '.txt' # 景点差评
max_comment = int(data['马蜂窝差评'][i])
if int(max_comment) != 0:
mfw_url = data['马蜂窝'][i]
print (i, data['高级别景区'][i], mfw_url)
spider_mafengwo(file_name, mfw_url)
else:
print ("马蜂窝《%s》没有差评"%(data['高级别景区'][i]))
print ("正在爬取第%s个目标,一共有96个目标"%(i+1))
if __name__ == '__main__':
main()
endTime = time.time()
sum_time = (endTime-startTime) / 60
print ("获取该信息一共用了%s分钟"%sum_time)
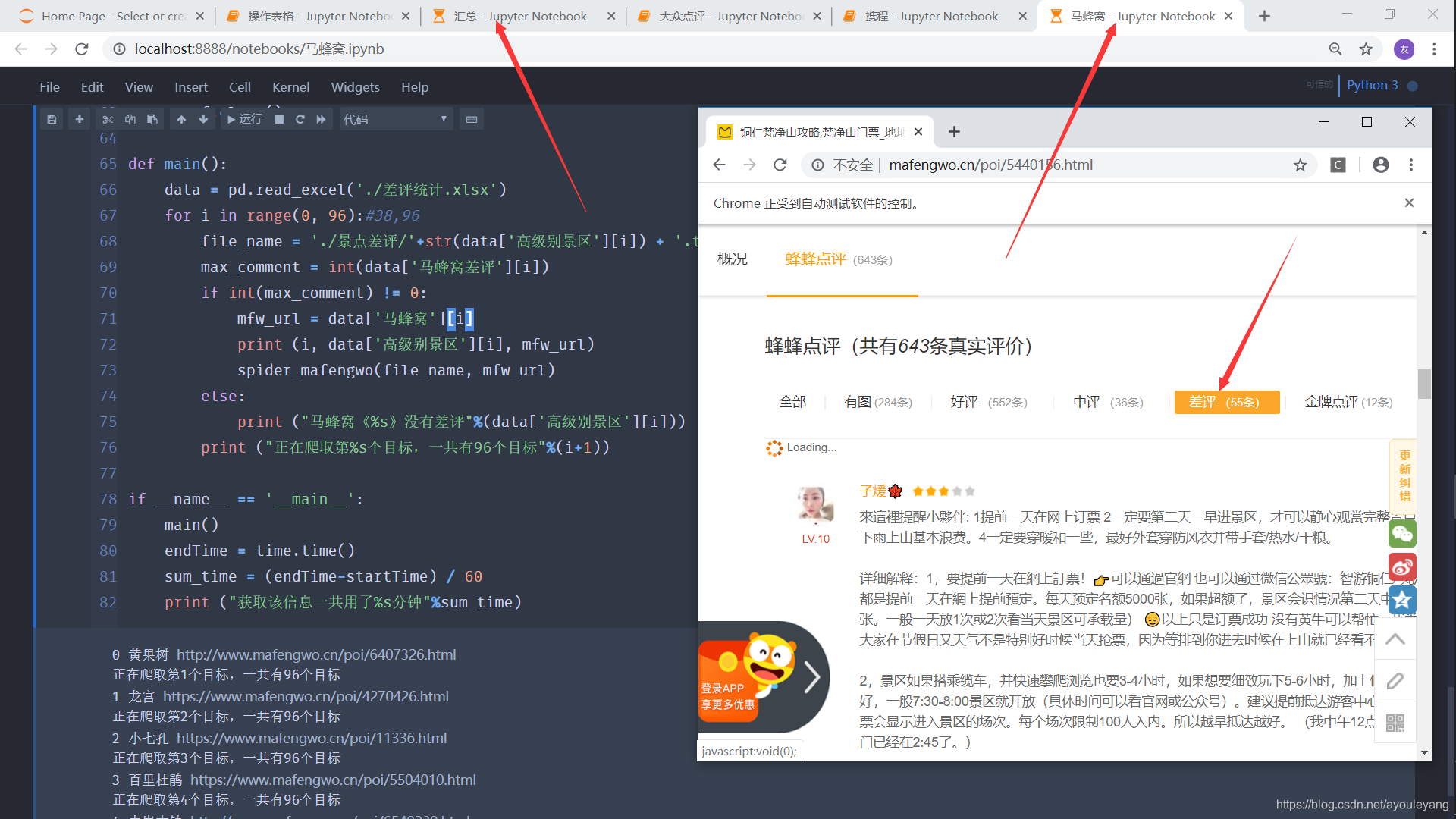
马蜂窝运行截图:
扫描二维码关注公众号,回复:
9635357 查看本文章

4、结果
正在爬取差评:
结果汇总截图:

(1)结果汇总到一个txt文件:
import os
path = './景点差评/'
f = open('./贵州景点差评汇总.txt', 'a', encoding='utf-8')#创建文件,a表示添加
for fileName in os.listdir(path):
openFile = open(path+fileName,'r', encoding='utf-8')#打开文件,r表示读取
print (fileName)
txt = openFile.read()#全部读取
f.write(txt)#写入文件
openFile.close()
f.close()
(2)分类汇总写入txt

import os
path = './景点差评/'
file_5A = open('./贵州景点差评汇总_5A.txt', 'a', encoding='utf-8')
file_4A = open('./贵州景点差评汇总_4A.txt', 'a', encoding='utf-8')
for fileName in os.listdir(path):
openFile = open(path+fileName,'r', encoding='utf-8')
txt = openFile.read()
print (fileName)
if "黄果树" in fileName:
file_5A.write(txt)
elif "青岩古镇" in fileName:
file_5A.write(txt)
elif "龙宫" in fileName:
file_5A.write(txt)
elif "梵净山" in fileName:
file_5A.write(txt)
elif "百里杜鹃" in fileName:
file_5A.write(txt)
elif "荔波漳江" in fileName:
file_5A.write(txt)
elif "镇远古镇" in fileName:
file_5A.write(txt)
else:
file_4A.write(txt)
openFile.close()
file_5A.close()
file_4A.close()
