前言:这是我学习Python爬虫以来,第一次使用python进行大规模的进行数据挖掘。邀请我加入她们科研项目的是工商学院的彭老师,做一个关于避暑旅游的课题。当他们需要获取携程旅游笔记时,由于文章的内容太多,思路也没有考虑好,无法使用数据采集器把笔记放入Excel。于是找到了我们信息学院寻求方法帮助,我的辅导员老师就向她推荐了我。终于有机会进行大型的项目实战了,非常幸运能参与这次的项目。但也由于平时比较繁忙,真正开发的时间并不是很多,通常都是课余时间做的。
第一次项目交接
她安排她的学生黄超来与我进行交接,告诉我,他们的需求。以前数据的采集就是他负责的,所以需求还是非常清楚的。他打电话与我沟通,说需要把旅游的笔记放进Excel做数据分析,我不是很理解,对于这些不规则的文本,最好的方式应该是放进txt文本才方便呀,经过一些沟通后,确定第二天见面谈。我需要在周末上双学位的课程,10月13号下午下课后就在我们上课的教室讨论,指出我需要爬取的内容。
当天也相当于交流学习,我从未做过这方面的实战。听他的要求后,最理想的方式是把它文字保存在txt文本,并不是Excel,初步达成共识。
第一次爬取:携程网,游客游记,关键词“避暑旅游”,不限时间,初次搜索出4398条
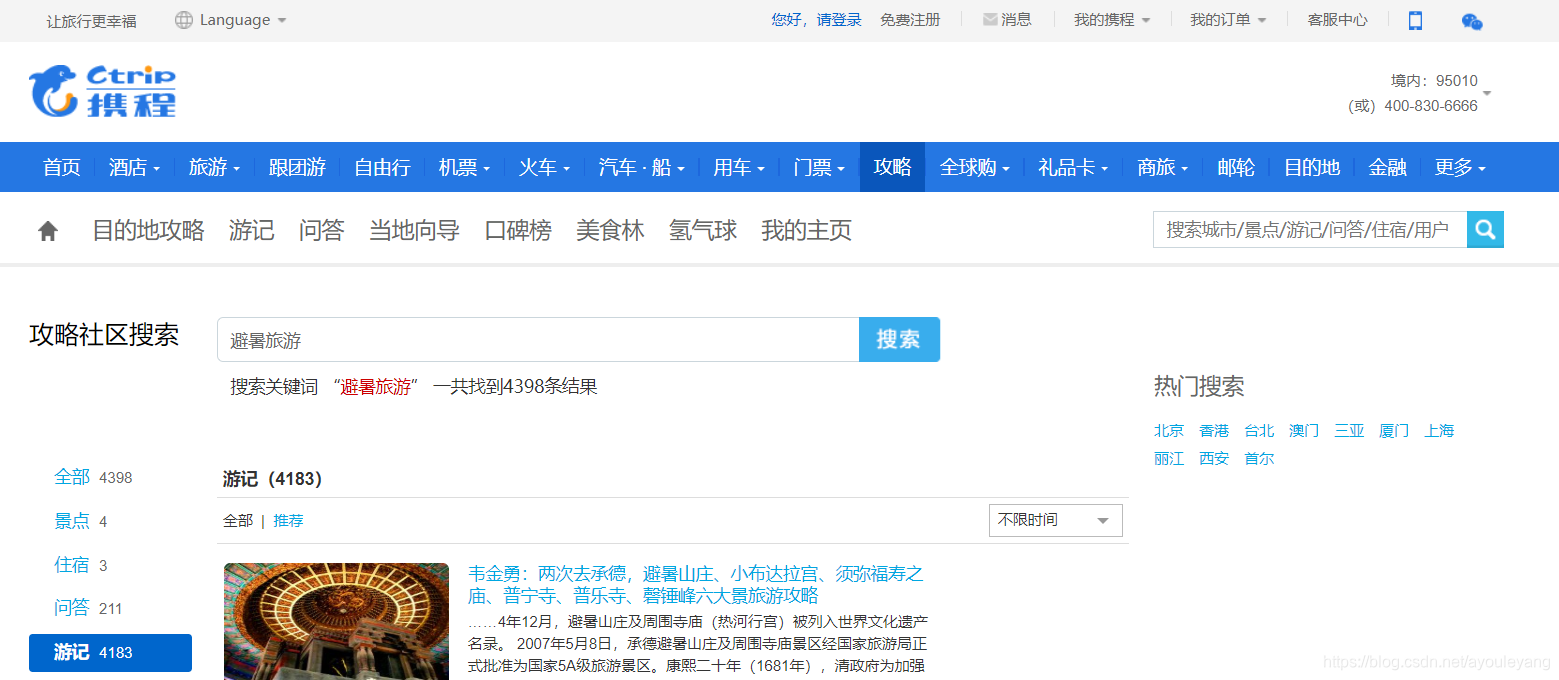
由于数量太大,更改关键词为“避暑”,时间为1年内,游记,共找到800篇,作为这次爬取的目标。由于是初次做这样的工作,变弄便沟通,花了3多小时的时间才完成初步的工作,实现思路如下:
实现思路第一步:爬取一篇文本做测试
1.1.1、获取单篇文章游客笔记文本
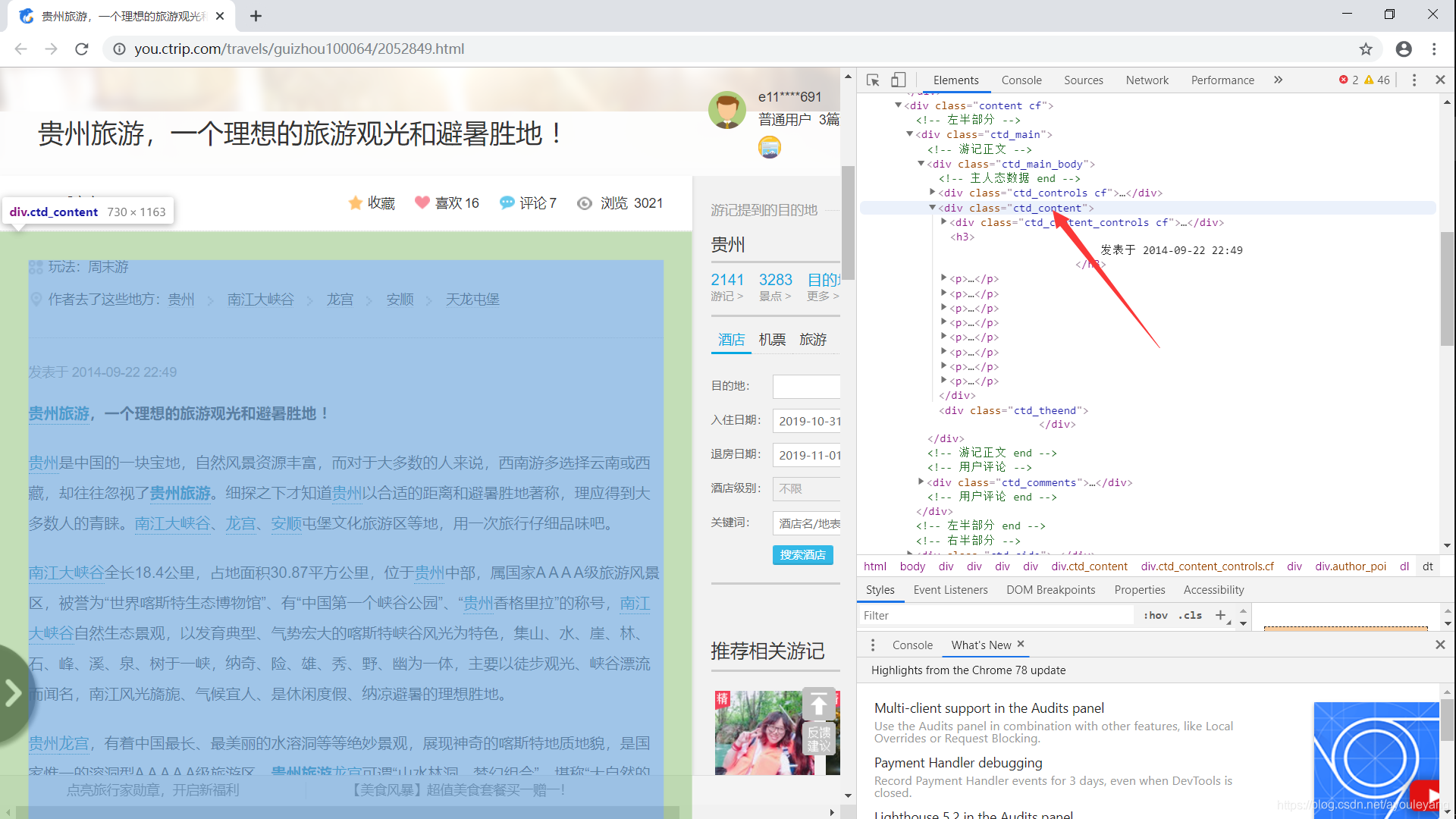
通过分析HTML发现,我所需要获取的文字都在class="ctd_content"这个标签类,直接通过BeautifulSoup的find模块找到所有的文本就可以了;
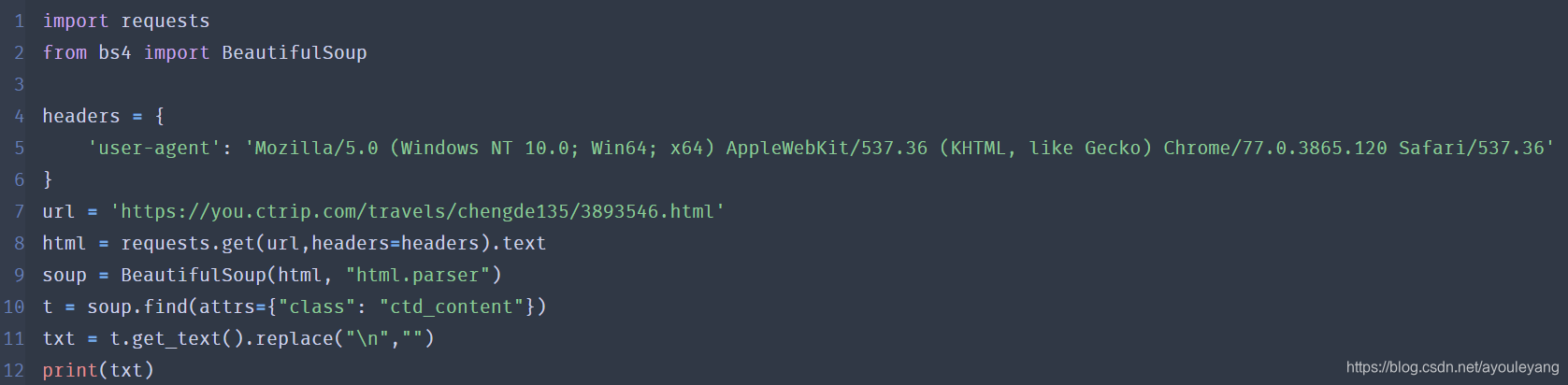
运行结果如下:

1.1.2、保存获取的内容到txt文本
txt = str(txt)#把获取的内容转换为字符,建议使用
filename = 'D:write_data.txt'
with open(filename,'w',encoding='utf-8') as f: # 如果filename不存在会自动创建, 'w'表示写数据,写之前会清空文件中的原有数据!
f.write(txt)
f.close()
txt截屏:

经验:为什么要把获取到的内容转化为字符串?
我在写入txt的过程中,发现很多文本会提示类型有有误,转成字符串后就没有报错了。
现在算是成功最主要的一步了,接下来就是爬取所有的文章了。
实现思路第二步:获取所有文本链接
1.2.1、获取一个主页的所有文章链接
import requests
from lxml import etree
url = 'https://you.ctrip.com/searchsite/travels/?query=避暑&isAnswered=&isRecommended=&publishDate=365&PageNo=1'
html = requests.get(url).text
txt = etree.HTML(html)
file = txt.xpath('/html/body/div[2]/div[2]/div[2]/div/div[1]/ul/li')
for t in file:
href = t.xpath('./dl/dt/a/@href')[0]
hrefUrl = 'https://you.ctrip.com'+href#把链接补充完整
print (hrefUrl)
获取结果:
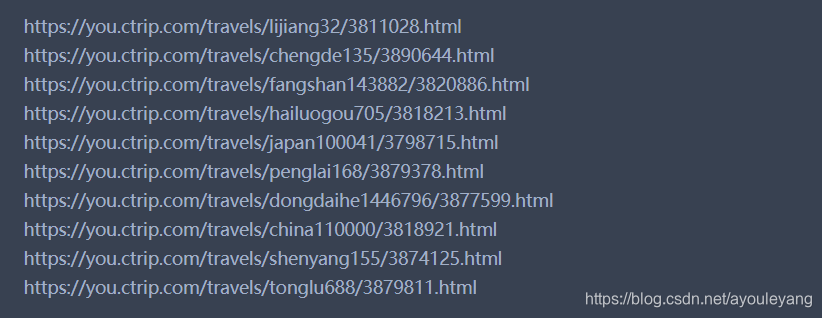
注意: 携程网使用的是相对路径,我们需要把获取的链接补充完整,在前面加上“https://you.ctrip.com”,
1.2.1、获取每个主页的链接
1.2.1、获取每个主页的所有文章链接,并添加到数组
为什么要把获取到的链接存在数组,不是直接进行获取它的内容?
1、从数组内遍历出来速度比单独爬取一个会更快
2、减少被反爬的概率,经常访问更容易被识别出爬虫
3、优化逻辑
import requests
from lxml import etree
from bs4 import BeautifulSoup
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.120 Safari/537.36'
}
allUrl = []
for num in range(1,81,1):
print(num)
url = 'https://you.ctrip.com/searchsite/travels/?query=避暑&isAnswered=&isRecommended=&publishDate=365&PageNo='+str(num)
html = requests.get(url).text
txt = etree.HTML(html)
file = txt.xpath('/html/body/div[2]/div[2]/div[2]/div/div[1]/ul/li')
for t in file:
href = t.xpath('./dl/dt/a/@href')[0]
hrefUrl = 'https://you.ctrip.com'+href
allUrl.append(hrefUrl)
1.2.1、开始获取所有的文章
import requests
from lxml import etree
from bs4 import BeautifulSoup
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.120 Safari/537.36'
}
k = 0
allUrl = []
for num in range(1,81,1):
print(num)
url = 'https://you.ctrip.com/searchsite/travels/?query=避暑&isAnswered=&isRecommended=&publishDate=365&PageNo='+str(num)
html = requests.get(url).text
txt = etree.HTML(html)
file = txt.xpath('/html/body/div[2]/div[2]/div[2]/div/div[1]/ul/li')
for t in file:
href = t.xpath('./dl/dt/a/@href')[0]
hrefUrl = 'https://you.ctrip.com'+href
allUrl.append(hrefUrl)
for useUrl in allUrl:
k = k + 1
print ("正在获取第%s篇"%k)
print (useUrl)
html = requests.get(url = useUrl,headers=headers).text
soup = BeautifulSoup(html, "html.parser")
t = soup.find(attrs={"class": "ctd_content"})
txt = t.get_text().replace("\n","")
txt = str(txt)
filename = 'G:write_data.txt'
with open(filename,'a',encoding='utf-8') as f: # 如果filename不存在会自动创建, 'w'表示写数据,写之前会清空文件中的原有数据!
f.write(txt)
f.close()
print ("获取完毕!")
幸运点:
1、还好这次的运气比较好,没有遇见服务器请求失败的情况,一气呵成
2、网页结构统一,没有出现结构异常而报错
更具他留下来的要求,还需要爬取携程网的问答模块,马蜂窝的三个模块,分别是关键词为“避暑”的游记,攻略和问答。
第二天,我在上课的时间完成了对携程网问答模块的爬取,并把完成的文本发给他先做研究。晚上的时候,他告诉我说,他们老师想见我,和我仔细的交流一下。
第二次项目交接
周二,我白天要上班到16:30,我晚上还要上三节课,通过电话约定16:40去找她,简单的交流一下。这次说是项目交接,还不如说叫做聊天吧,彭老师告诉我她们在做什么项目,并且完成的进度,对技术人员的需求。接下来我就是向她展示了一下我爬取数据的思路,方便她在写文稿的时候有相关的思路,并且简单的确认了一下接下来数据的获取。
在她看来,会一门别人不会的技术,在做学术上是有很大优势的。而我所掌握的网络爬虫就是一门不错的技术,希望我能做好这门技术,给讲了很多考研和做学术的事。多参与这类项目的开发,并发表相关的论文,对我考研是有很大帮助的,但对于考研的事情,我并没有明确自己的目标。
经过交谈,她也想学习Python爬虫,并让我有时间的时候指导一下学习,后来帮她安装好了学习Python的编译,给了一些入门基础教程,让她先了解一下基础,以后再教授爬虫实战和对付反爬等相关工作。
当天晚上,我开始对马蜂窝的数据进行了爬取实战。
最近有人使用数据采集器爬了马蜂窝的1800万数据就刷爆了网络,惊动了互联网界和投资界,背后的数据团队也因此爆红。所以它的数据又重新做好保护措施,我这次爬取它还是花了一些时间来研究它的。请求到它的源码后,发现我需要的数据都没有在其中,这就有点麻烦了,只能使用其他的办法了。经过仔细的查看后,我发现它的数据全部都是动态加载的,你看到哪里,它就加载到哪里,建立这个思维后,我开始使用selenium搞自动化,但是这个的效率就要慢很多了,还好不负努力,终于把它解决了,花了一节课的时间运行代码,爬取了所有的游记,共计46篇,速度已经慢得难受了,还好是上课时间,听了一节课,不影响我时间的使用。
2.1.1、获取主页的所有文章链接,保存到数组
import requests
from lxml import etree
from bs4 import BeautifulSoup
filename = 'G:马蜂窝游记笔记文本.txt'
noteBook = 'G:马蜂窝游记笔记评论.txt'
url = 'http://www.mafengwo.cn/search/q.php?q=%E9%81%BF%E6%9A%91&t=notes&seid=D8276190-E622-4B11-A1B6-DF09CF22DD76&mxid=&mid=&mname=&kt=1'
headers = {
'Referer': 'http://www.mafengwo.cn/search/q.php?q=%E9%81%BF%E6%9A%91&t=notes&seid=D8276190-E622-4B11-A1B6-DF09CF22DD76&mxid=&mid=&mname=&kt=1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.120 Safari/537.36'
}
allUrl = []
htmlUrl = requests.get(url,headers = headers).text
txtUrl = etree.HTML(htmlUrl)
file = txtUrl.xpath('//*[@id="_j_search_result_left"]/div/div/ul/li')
for t in file:
hrefUrl = t.xpath('./div/div[2]/h3/a/@href')[0]
allUrl.append(hrefUrl)
print (hrefUrl)
print(len(allUrl))
部分截屏,一共获取46条链接
2.1.2、打开文章,下拉加载数据
使用selenium对js进行操作
for t in range(1000,310000,1000):#第一次下拉1000像素,第二次要大于1000,相当于从零算起,310000是它的总像素
time.sleep(0.1)#延时,模拟人为加载
js=f"document.documentElement.scrollTop={t}"#下拉加载
driver.execute_script(js)
2.1.3、加载数据完毕,获取HTML,并关闭浏览器
由于页面太多,使用浏览器的页面后要关闭浏览器,减少电脑CPU的消耗,也是桌面整洁
source = driver.page_source#获取源码
driver.close()#关闭浏览器
2.1.4、提取作者笔记和评论
# 提取作者笔记
soup = BeautifulSoup(source, "html.parser")
note = soup.find(attrs={"class": "_j_content_box"}).get_text()
note = note.replace("\n","")
note = str(note)
#提取笔记评论
for usrAnswer in soup.find_all(attrs={"class": "mfw-cmt _j_reply_item"}):
answer = usrAnswer.find(attrs={"class": "_j_reply_content"}).get_text()
answer = str(answer)
2.1.5、分开保存笔记和评论
分开保存的目的主要是为了方便研究,她们并没有提要求,到这样做比较保险。
# 保存作者笔记
with open(filename,'a',encoding='utf-8') as f: # 如果filename不存在会自动创建, 'w'表示写数据,写之前会清空文件中的原有数据!
f.write(note+"\n")
f.close()
#保存笔记评论
with open(noteBook,'a',encoding='utf-8') as g: # 如果filename不存在会自动创建, 'w'表示写数据,写之前会清空文件中的原有数据!
g.write(answer+"\n")
g.close()
2.1.6、大功告成,开始批量爬取
from selenium import webdriver
import time
import requests
from lxml import etree
from bs4 import BeautifulSoup
filename = 'G:马蜂窝游记笔记文本.txt'
noteBook = 'G:马蜂窝游记笔记评论.txt'
url = 'http://www.mafengwo.cn/search/q.php?q=%E9%81%BF%E6%9A%91&t=notes&seid=D8276190-E622-4B11-A1B6-DF09CF22DD76&mxid=&mid=&mname=&kt=1'
headers = {
'Referer': 'http://www.mafengwo.cn/search/q.php?q=%E9%81%BF%E6%9A%91&t=notes&seid=D8276190-E622-4B11-A1B6-DF09CF22DD76&mxid=&mid=&mname=&kt=1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.120 Safari/537.36'
}
allUrl = []
htmlUrl = requests.get(url,headers = headers).text
txtUrl = etree.HTML(htmlUrl)
file = txtUrl.xpath('//*[@id="_j_search_result_left"]/div/div/ul/li')
for t in file:
hrefUrl = t.xpath('./div/div[2]/h3/a/@href')[0]
allUrl.append(hrefUrl)
for urlUser in allUrl:
print("正在爬取:",urlUser)
driver = webdriver.Chrome('D:\\Software\\chromedriver.exe')
driver.get(urlUser)#打开马蜂窝
driver.implicitly_wait(6)#等待加载六秒
time.sleep(6)
for t in range(1000,310000,1000):#第一次下拉1000像素,第二次要大于1000,相当于从零算起,310000是它的总像素
time.sleep(0.1)#延时,模拟人为加载
js=f"document.documentElement.scrollTop={t}"#下拉加载
driver.execute_script(js)
source = driver.page_source#获取源码
driver.close()#关闭浏览器
# 提取作者笔记
soup = BeautifulSoup(source, "html.parser")
note = soup.find(attrs={"class": "_j_content_box"}).get_text()
note = note.replace("\n","")
note = str(note)
# 保存作者笔记
with open(filename,'a',encoding='utf-8') as f: # 如果filename不存在会自动创建, 'w'表示写数据,写之前会清空文件中的原有数据!
f.write(note+"\n")
f.close()
#提取笔记评论
for usrAnswer in soup.find_all(attrs={"class": "mfw-cmt _j_reply_item"}):
answer = usrAnswer.find(attrs={"class": "_j_reply_content"}).get_text()
answer = str(answer)
#保存笔记评论
with open(noteBook,'a',encoding='utf-8') as g: # 如果filename不存在会自动创建, 'w'表示写数据,写之前会清空文件中的原有数据!
g.write(answer+"\n")
g.close()
print ("该页评论已下载完毕!")
终于解决了,看以来还行~
2.1.7、更具这样的思路,完成了马蜂窝攻略和问答的爬取
马蜂窝攻略和问答与游记不同的地方在于,它俩的文章比较多,需要翻页,这样使用一个循环就构造好它的链接了,还是比较容易的,圆满完成任务!

第三次项目交接
这次黄超同学重新更改了他的需求,需要重新爬取携程网游记,从以前的一年之内改为时间不限,从800篇变到了9331篇
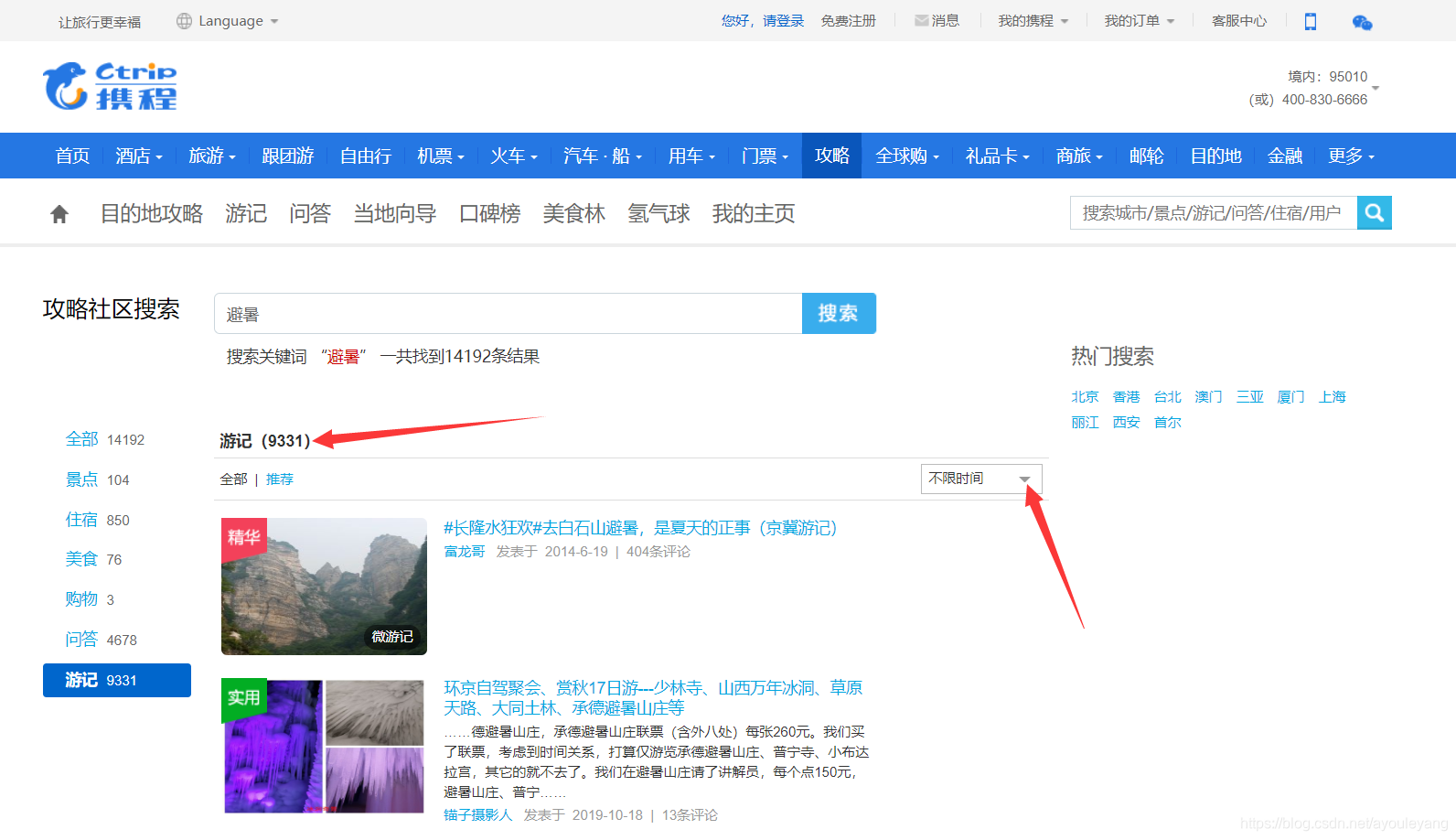
这样的任务量无疑增加得大了,如果是按照先前的方式运行代码一篇一篇的爬取,在运行顺利的情况下,估计也要花两三个小时吧。所以必须解决速度问题… …
方法一——使用多进程:
我先考虑使用多进程了完成这项工作,分别让它往一个文本中写入数据,多开几个进程。考虑到请求数据库失败,代码报错的问题,我选择使用try函数跳过错误的请求失败的文章,执行后我发现被跳过的文章太多,如果要重新爬取这些文章或减少损失,这是一件不容易的事情。
方法二——分为10段,同时开10个程序:
我需要爬取的文章从1~9331,被我分为了10段执行,并分别把文本写入10个txt文件,哪一个错就重新执行哪一个,10个代码同时执行。
第一个程序:第1~101篇,文件夹:filename = 'G:携程游记之避暑01.txt'
第二个程序:第1001~201篇文件夹:filename = 'G:携程游记之避暑02.txt'
第三个程序:第301~401篇文件夹:filename = 'G:携程游记之避暑03.txt'
.........
第三个程序:第901~9332篇文件夹:filename = 'G:携程游记之避暑10.txt'
10个程序分开同时执行:
保存结果:
携程问答爬取:
代码片段其一:
import requests
from bs4 import BeautifulSoup
from lxml import etree
import time
start = time.time()#记录开始时的时间
filename = "G:携程问答之避暑3(1).txt"#保存的文本命名及路径
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.120 Safari/537.36'
}
allUrl = []#保存获取的链接
for page in range(1,26,1):
index = 'https://you.ctrip.com/searchsite/asks/?query=避暑&isAnswered=&isRecommended=&publishDate=&PageNo=%s'%page
print ("正在获取:",index)
indexHtml = requests.get(url=index,headers=headers).text
etreeIndex = etree.HTML(indexHtml)
liUrls = etreeIndex.xpath('/html/body/div[2]/div[2]/div[2]/div/div[1]/ul/li')
for li in liUrls:
href = li.xpath('./dl/dt/a/@href')[0]
hrefUrl = 'https://you.ctrip.com'+href
allUrl.append(hrefUrl)
urlNum = len(allUrl)
print ("一共找到%s篇文章需要爬取"%urlNum)
c = 0
for textUrl in allUrl:
c = c + 1#记录文章篇数
if c in range(0,4676,10):
time.sleep(50)#模拟暂停
print ("正在爬取第%s篇文章,一共有4676篇"%c)
textHtml = requests.get(url = textUrl,headers = headers).text
textsoup = BeautifulSoup(textHtml,"html.parser")
#提取作者笔记标题
textTitle = textsoup.find(attrs={"class":"ask_title"}).get_text()
print (textTitle)
textTitle = str(textTitle)
with open(filename,'a',encoding='utf-8') as f: # 如果filename不存在会自动创建, 'w'表示写数据,写之前会清空文件中的原有数据!
f.write(textTitle)
f.close()
#提取作者笔记
titleQuestion = textsoup.find(attrs={"class":"ask_text"}).get_text()
titleQuestion = str(titleQuestion)
with open(filename,'a',encoding='utf-8') as f: # 如果filename不存在会自动创建, 'w'表示写数据,写之前会清空文件中的原有数据!
f.write(titleQuestion)
f.close()
#提取评论
answerBoxs = textsoup.find_all(attrs={"class":"answer_box cf"})
for userAnswer in answerBoxs:
answer = userAnswer.find(attrs={"class":"answer_text"}).get_text()
answer = str(answer)
with open(filename,'a',encoding='utf-8') as f: # 如果filename不存在会自动创建, 'w'表示写数据,写之前会清空文件中的原有数据!
f.write(answer+"\n")
f.close()
end = time.time()#获取当前时间
useTime = int(end-start)
useTime = useTime/60
print ("本次爬取所有文章一共使用%s分钟"%useTime)
6个程序同时进行:
代码运行结果:
文本保存结果:
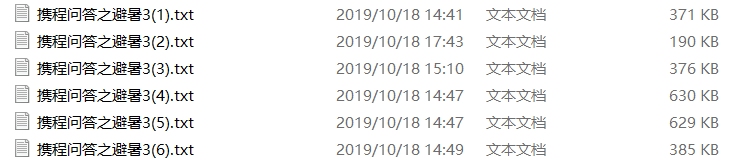
第四次项目交接
我看见彭老师在群里给她的学生说,文本有空格和换行会影响数据分析,此刻她正在一个一个的删除文本空格和换行。为了节约时间,我就告诉她她文本放入word使用替换功能去掉多余的空格和回车。
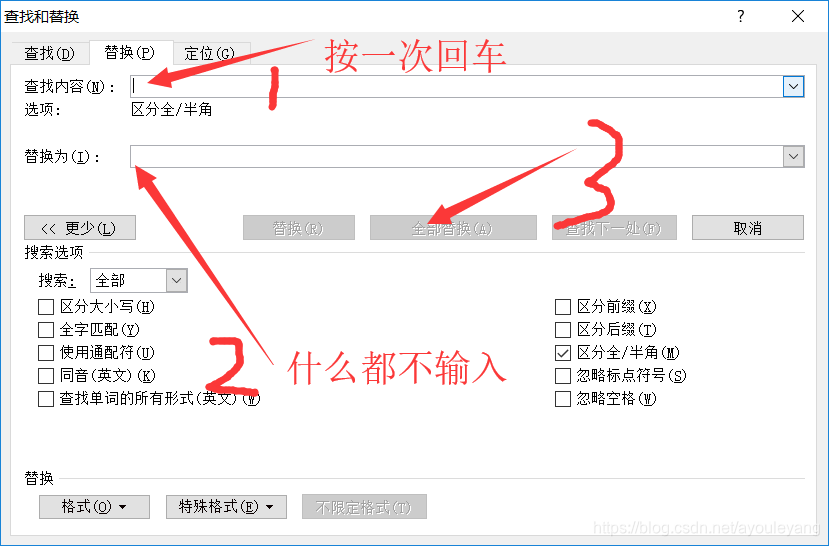
但是9千多篇文章还是太多了,她们的分析工具把电脑弄死机几次后,重新决定只要三年的数据,但是携程网上又没有专门筛选三年数据的地方,担心不能实现。
后来我通过提取每个游客的发表时间来提取文章,如果满足2017,2018,2019年,就把它的链接追加在保存链接的数组中,达筛到的目的。
for ettime in ettimes:
try:
pTime = ettime.xpath('./dl/dd[2]/text()')[1]
pTime = pTime.split("发表于")[1]
pTime = pTime.split("-")[0]
href = ettime.xpath('./dl/dt/a/@href')[0]
hrefUrl = 'https://you.ctrip.com' + href
if int(pTime) in [2017,2018,2019]:
print ("符合条件的时间",pTime)
print (hrefUrl)
allUrl.append(hrefUrl)
except:
pass
第一页,1~101页查找结果:
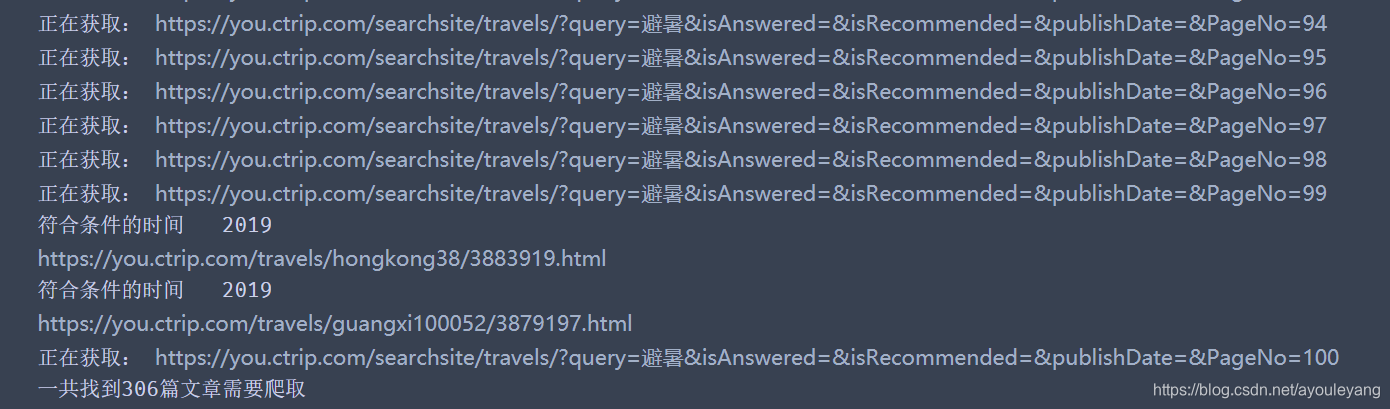
源码如下:
import requests,time
from lxml import etree
from bs4 import BeautifulSoup
start = time.time()
filename = 'G:携程游记之避暑201901.txt'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.120 Safari/537.36'
}
allUrl = []
for page in range(1,101,1):#1,932,1
indexUrl = 'https://you.ctrip.com/searchsite/travels/?query=避暑&isAnswered=&isRecommended=&publishDate=&PageNo=%s'%page
print ("正在获取:",indexUrl)
indexHtml = requests.get(url=indexUrl,headers=headers).text
etreeIndex = etree.HTML(indexHtml)
ettimes = etreeIndex.xpath('/html/body/div[2]/div[2]/div[2]/div/div[1]/ul/li')
for ettime in ettimes:
try:
pTime = ettime.xpath('./dl/dd[2]/text()')[1]
pTime = pTime.split("发表于")[1]
pTime = pTime.split("-")[0]
href = ettime.xpath('./dl/dt/a/@href')[0]
hrefUrl = 'https://you.ctrip.com' + href
if int(pTime) in [2017,2018,2019]:
print ("符合条件的时间",pTime)
print (hrefUrl)
allUrl.append(hrefUrl)
except:
pass
urlNum = len(allUrl)
print ("一共找到%s篇文章需要爬取"%urlNum)
c = 0
for textUrl in allUrl:
c = c + 1
print ("正在爬取第%s篇文章,一共有%s篇"%(c,urlNum))
try:
html = requests.get(url = textUrl,headers=headers).text
soup = BeautifulSoup(html, "html.parser")
try:
title = soup.find(attrs={"class": "title1"}).get_text().replace("\n","").replace(" ","")
except:
title = soup.find(attrs={"class": "ctd_head_left"}).get_text().replace("\n","").replace(" ","")
title = str(title)
print ("正在爬取:",title)
t = soup.find(attrs={"class": "ctd_content"})
txt = t.get_text().replace("\n","").replace(" ","")
txt = str(txt)
with open(filename,'a',encoding='utf-8') as f: # 如果filename不存在会自动创建, 'w'表示写数据,写之前会清空文件中的原有数据!
f.write(title)
f.write(txt)
f.close()
except:
pass
end = time.time()
useTime = int(end-start)
useTime = useTime/60
print ("该次爬取这%s文章共使用%s分钟"%(urlNum,useTime))
第五次项目交接
三年的数据这样存放不好使用分析,文件还是太大了,需要把2017,2018,2019年的数据单独存放,于是又对代码做出了一些更改,完成了最后一次需求!
import requests,time
from lxml import etree
from bs4 import BeautifulSoup
start = time.time()
filename = 'G:携程游记之避暑201910.txt'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.120 Safari/537.36'
}
allUrl = []
c = 0
for page in range(901,932,1):#1,932,1
indexUrl = 'https://you.ctrip.com/searchsite/travels/?query=避暑&isAnswered=&isRecommended=&publishDate=&PageNo=%s'%page
print ("正在获取:",indexUrl)
indexHtml = requests.get(url=indexUrl,headers=headers).text
etreeIndex = etree.HTML(indexHtml)
ettimes = etreeIndex.xpath('/html/body/div[2]/div[2]/div[2]/div/div[1]/ul/li')
for ettime in ettimes:
try:
pTime = ettime.xpath('./dl/dd[2]/text()')[1]
pTime = pTime.split("发表于")[1]
pTime = pTime.split("-")[0]
href = ettime.xpath('./dl/dt/a/@href')[0]
hrefUrl = 'https://you.ctrip.com' + href
if int(pTime) == 2019:
print ("符合条件的时间",pTime)
print (hrefUrl)
allUrl.append(hrefUrl)
except:
pass
urlNum = len(allUrl)
print ("一共找到%s篇文章需要爬取"%urlNum)
for textUrl in allUrl:
c = c + 1
print ("正在爬取第%s篇文章,一共有%s篇"%(c,urlNum))
try:
html = requests.get(url = textUrl,headers=headers).text
soup = BeautifulSoup(html, "html.parser")
try:
title = soup.find(attrs={"class": "title1"}).get_text().replace("\n","").replace(" ","")
except:
title = soup.find(attrs={"class": "ctd_head_left"}).get_text().replace("\n","").replace(" ","")
title = str(title)
print ("正在爬取:",title)
t = soup.find(attrs={"class": "ctd_content"})
txt = t.get_text().replace("\n","").replace(" ","")
txt = str(txt)
with open(filename,'a',encoding='utf-8') as f: # 如果filename不存在会自动创建, 'w'表示写数据,写之前会清空文件中的原有数据!
f.write(title)
f.write(txt)
f.close()
except:
pass
end = time.time()
useTime = int(end-start)
useTime = useTime/60
print ("该次爬取这%s文章共使用%s分钟"%(urlNum,useTime))
运行结果截屏:
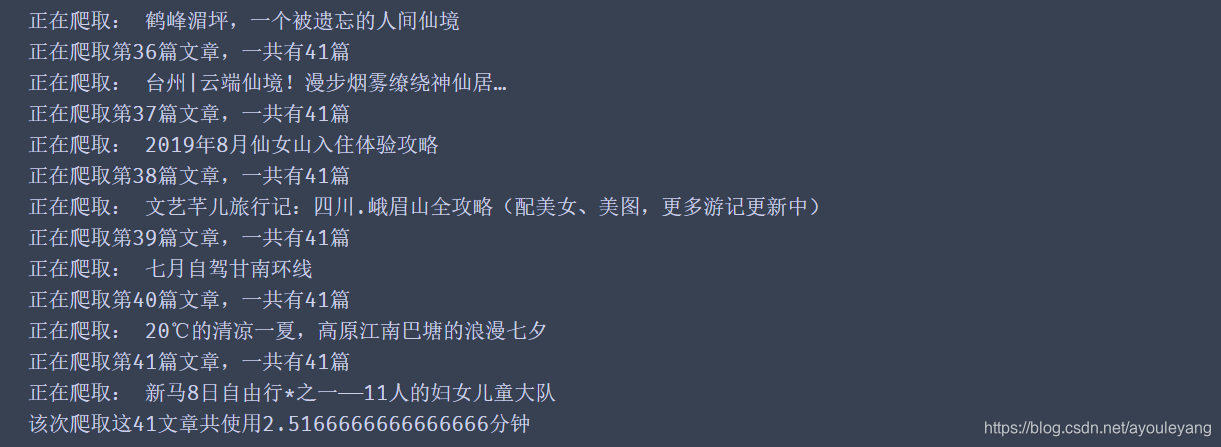
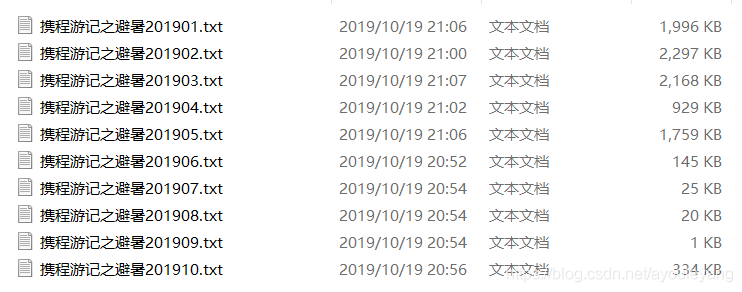
保存文本结果:

很感谢这次的实战机会,通过很多次的需求,让我学会了很多处理数据的方法,提高自己的编程实战能力,帮上一点小忙。
