1.首先是找到游记地址,找到游记地址就很费劲
在攻略和目的地栏找了,搜了半天西安,才勉强找到地址
在页面最下方
把最热游记改成最新游记,最热只出300页,3000条,

最新就是全部2538页,25373条

2.F12 找到分页地址,指向翻页按钮
例如指向第3页的按钮
<a class="pi" href="1-0-3.html" title="第3页">3</a>在F12的页面中直接点击这个链接
可以直接进入游记页面
终于找到了游记的真实地址
想爬游记要找详情页
最新游记第2页的网址,
http:/.../2-0-2.html第n也就是(2变成1,就是最热游记,只有3000篇)
http:/.../10195/2-0-n.html实际网址规则是等差数列
3.循环爬取详情页网址,可以采用网址探测器,探测一级就够了
探测和采集的网址中会出现不是游记详情页的网址,设置规则,只爬取详情页格式的网址
探测的网址格式如下,以第二页为例,不设置规则,就会连图片都探测出来,193条网址
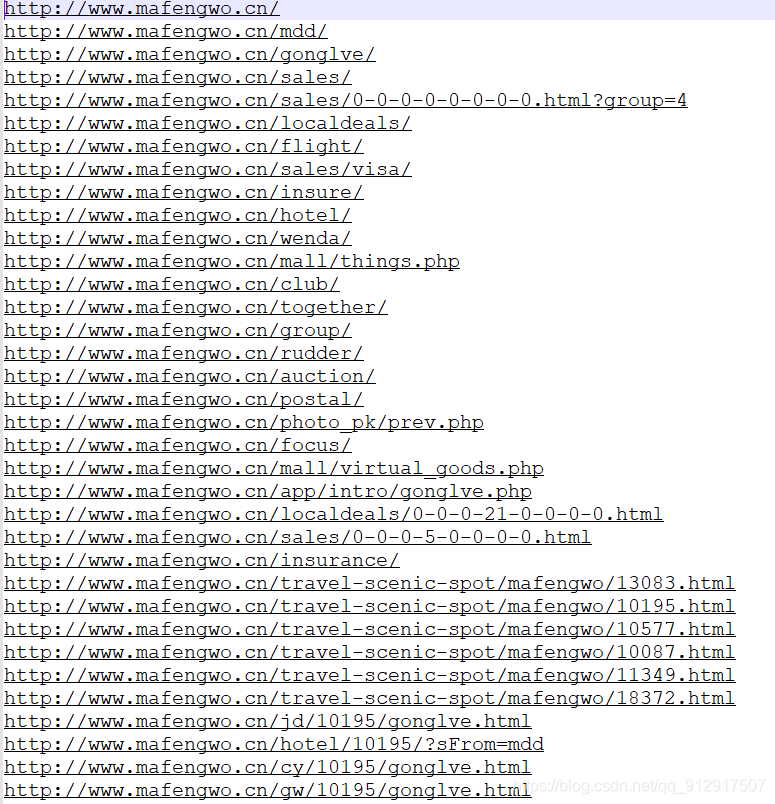
加入规则,需要包含规定字符串的网址
4.爬取详情页内容,设置好规则
使用Xpath方法,找到各详情页网址你想爬的内容
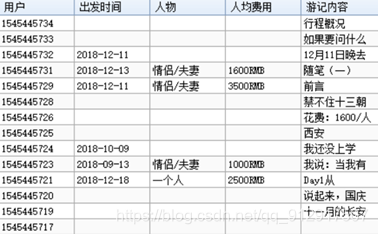
最终效果如图所示