------------恢复内容开始------------
马蜂窝泉州热门景点的爬取
首先先进入网站http://www.mafengwo.cn/search/q.php?q=%E6%B3%89%E5%B7%9E
打开开发者工具对其html进行分析
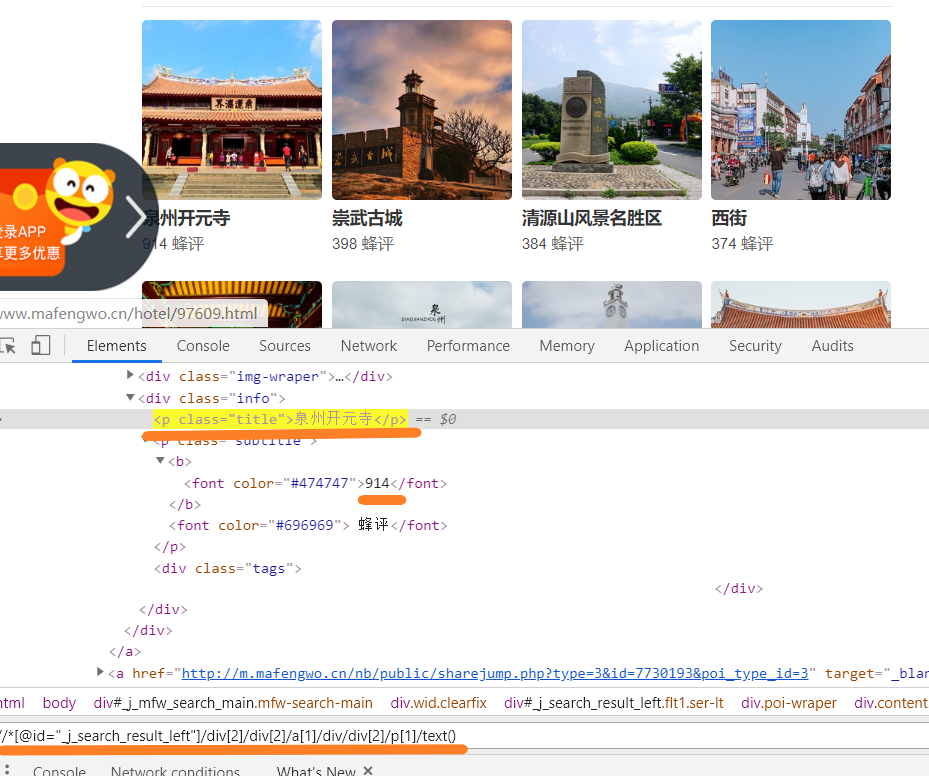
这里我使用的是xpath对其进行分析
我们不难发现马蜂窝泉州热门景点的名称都是在//*[@id="_j_search_result_left"]/div[2]/div[2]/a[?]/div/div[2]/p[1]的位置中,只有[?]的位置有改变
同理,蜂评数也是一样的,在//*[@id="_j_search_result_left"]/div[2]/div[2]/a[?]/div/div[2]/p[2]/b/font的位置中,也是只有[?]有改变
那么我们来对它进行提取并写入文本泉州热门景点排行榜.txt中。结果如图:
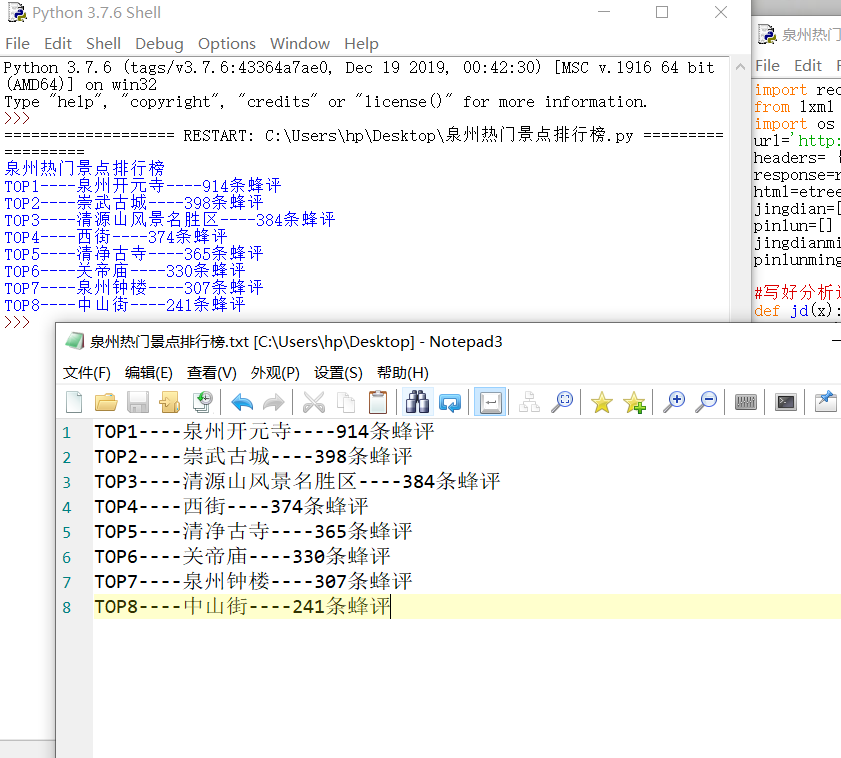
下面附上代码及注译:
扫描二维码关注公众号,回复:
9897640 查看本文章

1 import requests 2 from lxml import etree #我使用的是xpath和requests库爬取和解析网页数据 3 import os 4 url='http://www.mafengwo.cn/search/q.php?q=%E6%B3%89%E5%B7%9E' 5 headers= {'User-Agent':'Mozilla/5.0'}#设置请求头 6 response=requests.get(url=url,headers=headers) 7 html=etree.HTML(response.text)#将网页数据用xpath解析 8 jingdian=[] #准备装入景点的xpath数据 9 pinlun=[] #准备装入点评数的xpath数据 10 jingdianming=[] #准备装入景点名 11 pinlunming=[] #准备装入点评数 12 13 #写好分析返回的xpath数据的除杂函数 14 def jd(x): 15 srcs=html.xpath(x) 16 srcs=str(srcs[0]) 17 a=srcs.replace(' ','').replace("\n",'')#转为字符串类型的文本并除去多余字符 18 return a 19 20 21 for i in range(1,9): 22 jingdian.append('//*[@id="_j_search_result_left"]/div[2]/div[2]/a[{}]/div/div[2]/p[1]/text()'.format(i)) 23 #利用开发者工具发现景点名的规律,并装入jingdian数组中 24 for x in range(8): 25 jingdianming.append(jd(jingdian[x])) 26 #利用刚刚写好的jd函数逐个解析景点名的xpath数据,并将返回值装入jingdianming数组中 27 28 for p in range(1,9): 29 pinlun.append('//*[@id="_j_search_result_left"]/div[2]/div[2]/a[{}]/div/div[2]/p[2]/b/font/text()'.format(p)) 30 #利用开发者工具发现景点名的规律,并装入pinlun数组中 31 for y in range(8): 32 pinlunming.append(jd(pinlun[y])) 33 #利用刚刚写好的jd函数逐个解析评论数评论的xpath数据,并将返回值装入pinlunming数组中 34 35 36 with open("泉州热门景点排行榜.txt","w") as f: 37 for a in range(1,9): 38 f.write('TOP{}----{}----{}条蜂评'.format(a,jingdianming[a-1],pinlunming[a-1])) 39 #将数据写入到泉州热门景点排行榜.txt中 40 print("泉州热门景点排行榜") 41 for a in range(1,9): 42 print('TOP{}----{}----{}条蜂评'.format(a,jingdianming[a-1],pinlunming[a-1])) 43 #输出查看结果 44
------------恢复内容结束------------