前言:
{
最近想了解以下目前比较先进的目标检测(object detection)模型和方法,所以就在github上搜到了https://github.com/amusi/awesome-object-detection,这里面介绍了不少目标检测的文章。
YOLO(You Only Look Once)我之前见过,可只是知道它是目标识别的方法,并且效果不错,但没有了解其具体过程。这次就来分析一下。
论文地址:https://arxiv.org/pdf/1506.02640.pdf
}
正文:
{
在一开始的第一节,论文描述了之前方法的缺点:至少被分为两个部分——框的生成和分类,并且需要分别的训练。YOLO却只通过一个网络生成框和类别,而且没有复杂的数学原理,使用的是神经网络的回归过程。
第二节介绍了其结构和原理。
首先,输入图像被划分为S*S块网格,对每块网格都会生成B个框的预测和C个类的预测,每个框的预测包含x坐标,y坐标,宽度,高度h和置信度,网络的输出为S x S x (B*5 + C)的张量。具体结构可如图3:
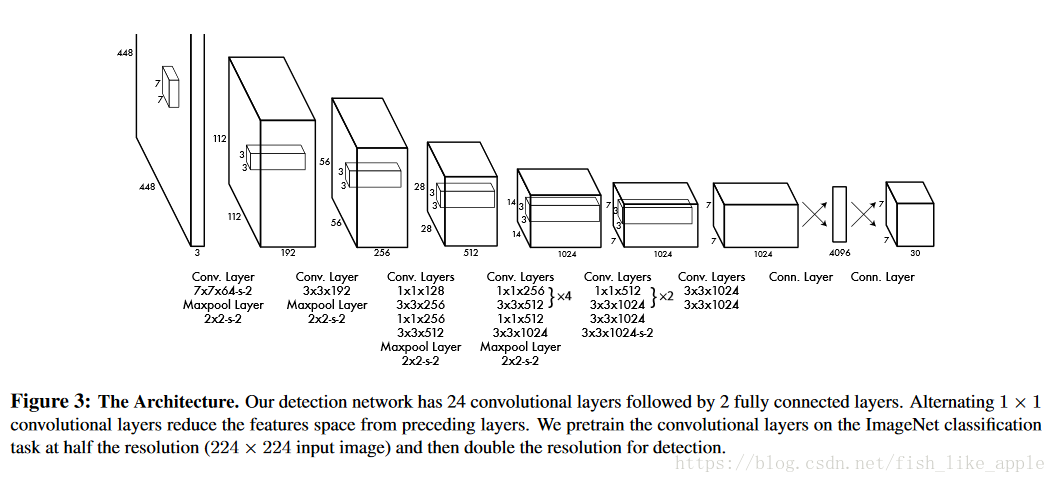
这种情况下,B=2,C=20,S=7,所以输出维度为7 x 7 x 30。
我认为,从网络的输入层到第一个全连接层(4096维特征向量之前)是一般的特征提取层,和inception_V3/V4等模型的瓶颈层之前的层类似,或者说在不考虑速度的情况下可以被这些模型的部分替代。
激活函数有两种:一种是线性函数,用在最后一层;另一种函数如式(2):
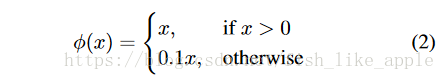
损失函数由式(3)的几个部分组成:
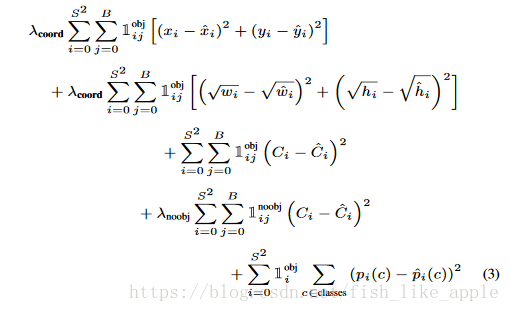
其中,x和y为框的x和y坐标,w为框宽,h为框高,C为框的置信度,pi(c)为类c的概率,并且
文中提到了一个问题:在一般情况下,很多网格都是没有对应的框(即对应的置信度应该都为0),但是每个网格都会有5个对应的不为0的预测置信度,这会导致训练(梯度)被集中在置信度相关的部分。所以设置

对w和h取平方根是考虑到了小的框对小的偏移比大的框对小的偏移更敏感。
作者在来自PASCALVOC 2007 和 2012的数据集上进行了大约135个epochs的训练;batch大小为64;momentum为0.9;decay为0.0005;learning rate在刚开始的epochs(没计入135个epochs)中从0.0001持续上升到0.001,在后面的75个epochs中保持0.001,在之后30个epochs中为0.0001,并且在最后30个epochs中为0.00001,在第一个全连接层后面加了比率为0.5的dropout层;并且进行了相关数据增强。
第二节的最后,作者介绍了YOLO的局限性:
1,由于网格所能检测的目标数量是固定的(每快网格只能检测一个类),所以当检测重复小目标时效果不是很好。
2,最后的全连接层的输入是一维的特征向量(论文中说relatively coarse),泛化能力不强。
和3,就像上面所说,小的框对小的误差比大的框对小的误差更敏感。论文中只对宽度和高度做了有关处理,所以还是会因此出现定位不准确的问题。
第三节和第四节主要是与其他方法的对比和实验。这里就直接上实验结果,表1和图4:
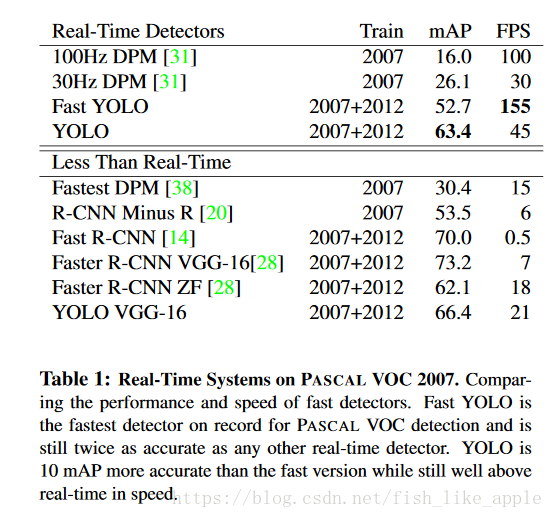

图4表明,虽然Fast R-CNN正确率更高,但是错的也更离谱。
后面还有一个排行榜,表3:

}
可以看到,在标准实时性的同时,YOLO也达到了还可以的效果。值得注意的是,Fast R-CNN + YOLO实现了比单独Fast R-CNN还要好的结果。
结语:
{
其实YOLO的网络结构还是很容易理解的,我认为核心特点是最后的输出张量。另外,从实验结果可以看出,目标检测还是有很大研究空间。
}