曾经想过计算机如何分析图像,识别并定位其中的物体吗?这正是计算机视觉领域的目标检测所完成的任务。DEtection TRansformer(DETR)和You Only Look Once(YOLO)是目标检测的两种重要方法。YOLO已经赢得了作为实时目标检测和跟踪问题的首选模型的声誉。与此同时,DETR是一种由变换器技术驱动的崭露头角的竞争者,有潜力在计算机视觉领域引发革命,类似于它对自然语言处理的影响。在本博客文章中,我将探讨这两种方法,以了解它们的工作原理!
自2012年以来,计算机视觉经历了一次革命性的转变,这是由卷积神经网络(CNN)和深度学习架构的出现推动的。这些架构中值得注意的有AlexNet(2012年),GoogleNet(2014年),VGGNet(2014年)和ResNet(2015年),它们包含了大量的卷积层,以提高图像分类的准确性。而图像分类任务涉及将标签分配给整个图像,例如将一张图片分类为狗或汽车,而目标检测不仅要识别图像中的内容,还要确定每个物体在图像中的位置。

图像上的目标检测和分类示例
YOLO的原始版本(2015年)是实时目标检测的一项突破性工作,当它发布时,它仍然是实际视觉应用中最常用的模型之一。它将检测过程从两到三个阶段(即R-CNN,Fast R-CNN)转变为单阶段的卷积阶段,并在准确性和速度方面超越了所有最先进的目标检测方法。原始论文中的模型架构随着时间的推移发生了变化,添加了不同的手工设计特性以提高模型的准确性。以下是YOLO的前三个版本及其区别的概述。
YOLO v1(2015年)是原始版本,为后续版本奠定了基础。它使用单一的深度卷积神经网络(CNN)来预测边界框和类别概率。YOLO v1将输入图像分成一个网格,并在网格的每个单元格中进行预测。每个单元格负责预测一定数量的边界框及其对应的类别概率。这个版本以令人印象深刻的速度实现了实时目标检测,但在检测小物体和准确定位重叠物体方面存在一些限制。
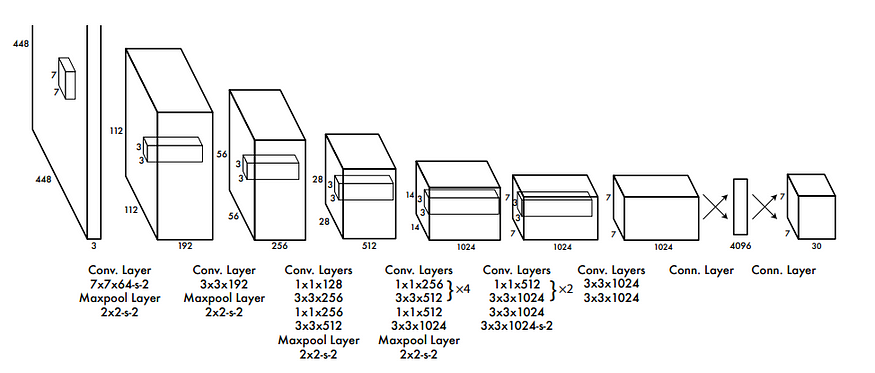
YOLO v1(2015年)原始框架
YOLO v2(2016年)解决了原始YOLO模型的一些限制。它引入了锚定框(anchor boxes),有助于更好地预测不同尺寸和宽高比的边界框。YOLO v2使用了更强大的骨干网络Darknet-19,并不仅在原始数据集(PASCAL VOC)上进行了训练,还在COCO数据集上进行了训练,大幅增加了可检测类别的数量。锚定框和多尺度训练的结合有助于提高小物体的检测性能。
YOLO v3(2018年)进一步提高了目标检测的性能。这个版本引入了特征金字塔网络的概念,具有多个检测层,允许模型在不同尺度和分辨率下检测物体。YOLO v3使用了一个更大的网络架构,拥有53个卷积层,称为Darknet-53,提高了模型的表示能力。YOLO v3在三个不同的尺度上进行检测:13x13、26x26和52x52的网格。每个尺度在每个格子单元格中预测不同数量的边界框。
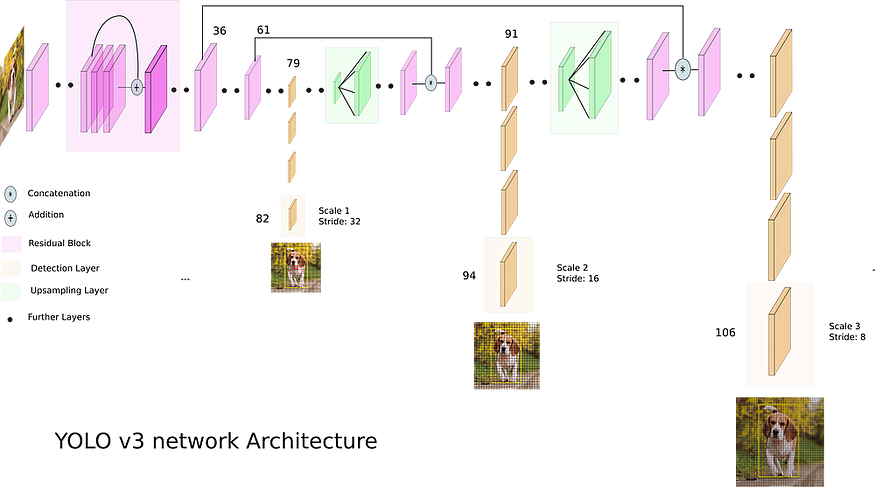
YOLO v3 框架
我们预测了多少个边界框?在416 x 416的分辨率下,YOLO v1预测了7 x 7 = 49个框。YOLO v2预测了13 x 13 x 5 = 845个框。而YOLO v3在3个不同的尺度上进行了预测:13 x 13 x 3 + 26 x 26 x 3 + 52 x 52 x 3 = 10,647个框。非极大值抑制(NMS)是一种后处理技术,用于过滤掉多余和重叠的边界框预测。在NMS算法中,首先删除置信度低于某个阈值的框。然后,具有与“当前”预测具有一定IoU(交并比)阈值(例如0.5)以上的较低置信度分数的所有其他预测被标记为多余并被抑制。
DETR(DEtection TRansformer)是一种相对新的目标检测算法,由Facebook人工智能研究(FAIR)的研究人员于2020年提出。它基于变换器架构,这是一种用于各种自然语言处理任务的强大的序列到序列模型。传统的目标检测器(例如R-CNN和YOLO)复杂并经历了多次变化,依赖于手工设计的组件(例如NMS)。与此不同,DETR是一个直接的集合预测模型,它使用变换器编码器-解码器架构一次性预测所有物体。这种方法比传统的目标检测器更简单、更高效,并在COCO数据集上实现了可比较的性能。
DETR架构简单,由三个主要组件组成:用于特征提取的CNN骨干(例如ResNet),变换器编码器-解码器和用于最终检测预测的前馈网络(FFN)。骨干处理输入图像并生成激活映射。变换器编码器减少通道维度并应用多头自注意力和前馈网络。变换器解码器使用N个物体嵌入的并行解码,并独立地预测边界框坐标和类别标签。DETR使用成对关系一次性推断所有物体,从整个图像上下文中受益。
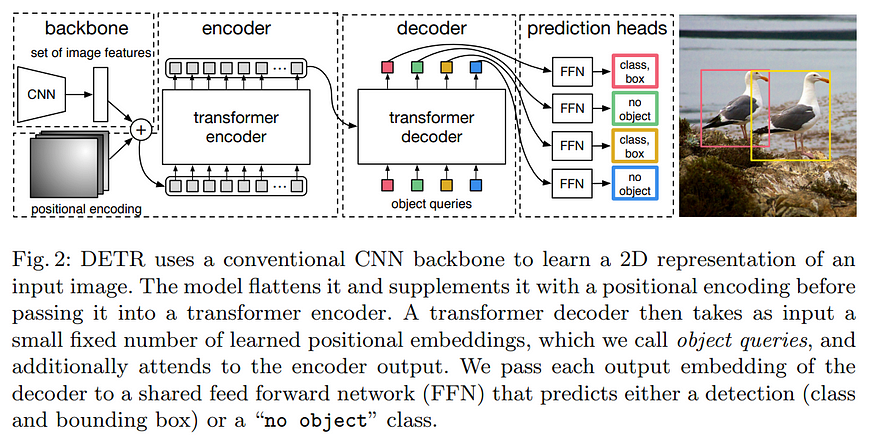
下面的代码(摘自DETR的官方GitHub存储库)定义了这个DETR模型的前向传递,它通过各种层处理输入数据,包括卷积骨干和变换器网络。我在代码中包含了网络每个层的输出形状,以使您了解所有数据的变换过程。
class DETRdemo(nn.Module):
def __init__(self, num_classes, hidden_dim=256, nheads=8,
num_encoder_layers=6, num_decoder_layers=6):
super().__init__()
# 2. create ResNet-50 backbone
self.backbone = resnet50()
del self.backbone.fc
# create conversion layer
self.conv = nn.Conv2d(2048, hidden_dim, 1)
# 3. create a default PyTorch transformer
self.transformer = nn.Transformer(
hidden_dim, nheads, num_encoder_layers, num_decoder_layers)
# 4. prediction heads, one extra class for predicting non-empty slots
# note that in baseline DETR linear_bbox layer is 3-layer MLP
self.linear_class = nn.Linear(hidden_dim, num_classes + 1)
self.linear_bbox = nn.Linear(hidden_dim, 4)
# 5. output positional encodings (object queries)
self.query_pos = nn.Parameter(torch.rand(100, hidden_dim))
# spatial positional encodings
# note that in baseline DETR we use sine positional encodings
self.row_embed = nn.Parameter(torch.rand(50, hidden_dim // 2))
self.col_embed = nn.Parameter(torch.rand(50, hidden_dim // 2))
def forward(self, inputs):
# propagate inputs through ResNet-50 up to avg-pool layer
# input: torch.Size([1, 3, 800, 1066])
x = self.backbone.conv1(inputs) # torch.Size([1, 64, 400, 533])
x = self.backbone.bn1(x) # torch.Size([1, 64, 400, 533])
x = self.backbone.relu(x) # torch.Size([1, 64, 400, 533])
x = self.backbone.maxpool(x) # torch.Size([1, 64, 200, 267])
x = self.backbone.layer1(x) # torch.Size([1, 256, 200, 267])
x = self.backbone.layer2(x) # torch.Size([1, 512, 100, 134])
x = self.backbone.layer3(x) # torch.Size([1, 1024, 50, 67])
x = self.backbone.layer4(x) # torch.Size([1, 2048, 25, 34])
# convert from 2048 to 256 feature planes for the transformer
h = self.conv(x) # torch.Size([1, 256, 25, 34])
# construct positional encodings
H, W = h.shape[-2:]
pos = torch.cat([
self.col_embed[:W].unsqueeze(0).repeat(H, 1, 1),
self.row_embed[:H].unsqueeze(1).repeat(1, W, 1),
], dim=-1).flatten(0, 1).unsqueeze(1) # torch.Size([850, 1, 256])
src = pos + 0.1 * h.flatten(2).permute(2, 0, 1) # torch.Size([850, 1, 256])
target = self.query_pos.unsqueeze(1) # torch.Size([100, 1, 256])
# propagate through the transformer
h = self.transformer(pos + 0.1 * h.flatten(2).permute(2, 0, 1),
self.query_pos.unsqueeze(1)).transpose(0, 1) # torch.Size([1, 100, 256])
linear_cls = self.linear_class(h) # torch.Size([1, 100, 92])
liner_bbx = self.linear_bbox(h).sigmoid() # torch.Size([1, 100, 4])
# finally project transformer outputs to class labels and bounding boxes
return {'pred_logits': linear_cls,
'pred_boxes': linear_bbx}以下是代码的逐步解释:
初始化:__init__方法定义了DETR模块的结构。它以几个超参数作为输入,包括类别数量(num_classes),隐藏维度(hidden_dim),注意力头数(nheads),以及编码器和解码器的层数(num_encoder_layers和num_decoder_layers)等。
BackBone和卷积层:代码创建了一个ResNet-50(self.backbone),并删除了其全连接(fc)层,因为它不会用于检测。卷积层(self.conv)被添加用于将 BackBone 的输出从2048通道转换为hidden_dim通道。
Transformer:使用nn.Transformer类创建了一个PyTorch变换器(self.transformer)。这个变换器将同时处理模型的编码器和解码器部分。编码器和解码器层数以及其他参数根据提供的超参数进行设置。
预测头:模型为预测定义了两个线性层:self.linear_class 用于预测类别对数概率。额外添加了一个类别以预测非空槽,因此类别数为num_classes + 1。self.linear_bbox 用于预测边界框的坐标。对其应用了sigmoid()函数以确保边界框坐标在[0, 1]范围内。
位置编码:位置编码对于基于变换器的模型至关重要。模型定义了查询位置编码(self.query_pos)和空间位置编码(self.row_embed和self.col_embed)。
这些编码有助于模型理解不同元素之间的空间关系。模型生成100个有效的预测。我们仅保留输出中概率高于特定限制的部分预测,并且舍弃所有其他预测。
示例
在这一部分,我展示了我的GitHub存储库中的一个示例项目,我在该项目中使用了DETR和YOLO模型来处理实时视频流。该项目的目标是研究DETR在实时视频流上的性能,与行业中大多数实时应用的首选模型YOLO进行比较。
import torch
from ultralytics import YOLO
import cv2
from dataclasses import dataclass
import time
from utils.functions import plot_results, rescale_bboxes, transform
from utils.datasets import LoadWebcam, LoadVideo
import logging
logging.basicConfig(
level=logging.DEBUG, format="%(asctime)s - %(levelname)s - %(message)s"
)
@dataclass
class Config:
source: str = "assets/walking_resized.mp4"
view_img: bool = False
model_type: str = "detr_resnet50"
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
skip: int = 1
yolo: bool = True
yolo_type = "yolov8n.pt"
class Detector:
def __init__(self):
self.config = Config()
self.device = self.config.device
if self.config.source == "0":
logging.info("Using stream from the webcam")
self.dataset = LoadWebcam()
else:
logging.info("Using stream from the video file: " + self.config.source)
self.dataset = LoadVideo(self.config.source)
self.start = time.time()
self.count = 0
def load_model(self):
if self.config.yolo:
if self.config.yolo_type is None or self.config.yolo_type == "":
raise ValueError("YOLO model type is not specified")
model = YOLO(self.config.yolo_type)
logging.info(f"YOLOv8 Inference using {self.config.yolo_type}")
else:
if self.config.model_type is None or self.config.model_type == "":
raise ValueError("DETR model type is not specified")
model = torch.hub.load(
"facebookresearch/detr", self.config.model_type, pretrained=True
).to(self.device)
model.eval()
logging.info(f"DETR Inference using {self.config.model_type}")
return model
def detect(self):
model = self.load_model()
for img in self.dataset:
self.count += 1
if self.count % self.config.skip != 0:
continue
if not self.config.yolo:
im = transform(img).unsqueeze(0).to(self.device)
outputs = model(im)
# keep only predictions with 0.7+ confidence
probas = outputs["pred_logits"].softmax(-1)[0, :, :-1]
keep = probas.max(-1).values > 0.9
bboxes_scaled = rescale_bboxes(
outputs["pred_boxes"][0, keep].to("cpu"), img.shape[:2]
)
else:
outputs = model(img)
logging.info(
f"FPS: {self.count / self.config.skip / (time.time() - self.start)}"
)
# print(f"FPS: {self.count / self.skip / (time.time() - self.start)}")
if self.config.view_img:
if self.config.yolo:
annotated_frame = outputs[0].plot()
cv2.imshow("YOLOv8 Inference", annotated_frame)
if cv2.waitKey(1) & 0xFF == ord("q"):
break
else:
plot_results(img, probas[keep], bboxes_scaled)
logging.info("************************* Done *****************************")
if __name__ == "__main__":
detector = Detector()
detector.detect()下面的server.py脚本使用了Ultralytics的YOLO v8模型和torch hub中预训练的DETR模型。server.py脚本负责从诸如网络摄像头、IP摄像头或本地视频文件等源获取数据。可以在server.py配置数据类中修改此源。性能评估结果显示,使用yolov8m.pt模型时,它在Tesla T4 GPU上实现了每秒55帧(FPS)的卓越处理速度。另一方面,使用detr_resnet50模型在Tesla T4 GPU上实现了每秒15帧(FPS)的处理速度。
结论
总之,YOLO是需要实时检测和速度的应用的绝佳选择,适用于视频分析和实时对象跟踪等应用。另一方面,DETR在需要提高准确性并处理物体之间复杂交互的任务中表现出色,这在医学影像、细粒度目标检测和检测质量高于实时处理速度的场景中可能特别重要。然而,值得注意的是,DETR的新版本——即实时DETR或RT-DETR——于2023年发布,声称在速度和准确性方面均优于所有相似规模的YOLO检测器。尽管这个创新没有在本博客中涵盖,但强调了这个领域的动态性,以及根据特定应用需求进一步优化YOLO和DETR之间的选择的潜力。
· END ·
HAPPY LIFE

本文仅供学习交流使用,如有侵权请联系作者删除