CS224n系列:
【CS224n】Neural Networks, Backpropagation
【CS224n】Neural-Dependency-Parsing
【CS224n】Language Models, RNN, GRU and LSTM
【CS224n】Neural Machine Translation with Seq2Seq
【CS224n】ConvNets for NLP
1. CNNs (Convolutional Neural Networks)
我觉得下述过程可以直接用textCNN的这个流程图来表达,清晰明了。所以,直接对着该图看下面的各个步骤会更简单一些。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VuHStIHM-1589083106609)(evernotecid://331CA178-4507-4573-914C-34BF843F1D8C/appyinxiangcom/26093810/ENResource/p177)]](https://img-blog.csdnimg.cn/20200510120002954.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0ZseWluZ19zZmVuZw==,size_16,color_FFFFFF,t_70)
1.1 Why CNNs?
为什么要再文本中使用卷积神经网络(CNN)呢?CNN通过卷积的方法,并使用不同大小的卷积核,可以捕捉到句子中不同长度短语的语义信息。
1.2 What is Convolution?
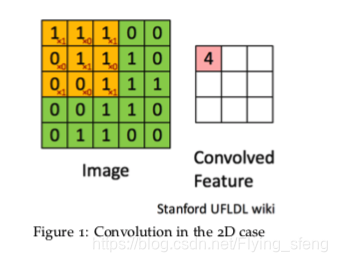
卷积操作大家应该都比较熟悉了,如下图,大矩阵为原始二维矩阵(如原始图片信息),红色的小矩阵为卷积核(图中为
矩阵);卷积操作:卷积核与原矩阵的相同大小的矩阵,对应点分别相乘,然后累加的过程。
1.3 A Single-Layer CNN
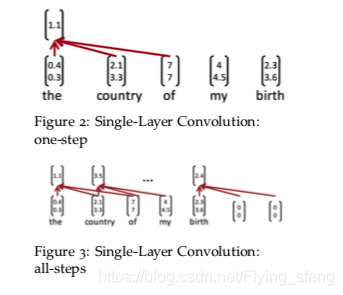
如下图,为单层的CNN。该结构的卷积核宽度为3,即每次对三个词做卷积操作。此时最后两个词没法做卷积,因此可以在最后词的后面添加2个零向量(具体数量为h-1,h为卷积核宽度),次即为padding操作。需要注意的是,在文本数据中使用CNN,一般都指的是一维卷积,即卷积核的长度必须跟词向量的维度一致(对词向量拆开做二维卷积没有意义,因为词向量的所有维度共同表示一个词)。
1.4 Pooling
进行卷积操作后,我们要进行pooling操作,目的是解决不同输入长度而导致输出长度不一致的问题,常用的Pooling操作是max-pooling。通过max-pooling操作,可以保留一个句子中最重要的信息(若干个h-grams短语中最重要的信息)。
1.5 Multiple-Filters
这表示的是不同尺寸的卷积核。比如我们可以设定卷积核大小为【2,3,4】,即我们能够捕捉到句子中bi-gram,tri-grams,quad-grams的信息。
1.6 Multiple-Channels
多通道操作目的是为了解决一个词在训练集中没有出现,但却在测试集中出现的情况。如果按上述的步骤去做,这类词是没办法学到相应的向量信息,导致测试集中的句子的词若不在训练集中存在,使用该句子得到的结果(如分类结果)会比较差。
一种解决该问题的方法是,设定双通道,两个通道都使用预训练的词向量(如w2v/glove),一个通道不做梯度计算,即词向量值不变;另一个通道通过梯度更新来改变词向量的值(如SGD)。那么怎么处理两个通道的信息呢?最常用的方法是平均两个通道的词向量的值。通过该方法,可以把预训练词向量的信息带入到神经网络中,当测试集中的词没在训练集中出现时,该词的预训练词向量也能起到一定作用。
1.7 CNN Options
上述1.4讲到的pooling,除了使用max-pooling之后,还可以使用k-max pooling。即卷积之后,使用k-max pooling,我们不仅保存句子中最重要短语的信息,而且能保存top-k个最重要短语的信息。k-max pooling可以处理句子中带转折语义的问题,如“这个店的东西很好吃,但人也太多了。”