版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/u012292754/article/details/86159471
1 Shuffle 原理
1.1 出现 Shffle 的情况
reduceByKeygroupByKeysortByKeycountByKeyjoincogroup
2 shuffle 原理图
- 假设有一个节点,只有2个CPU,上面运行了4个ShuffleMapTask;
- 假设有另外一个节点,上面也运行了4个 ResultTask,等待获取 ShuffleMapTask 的输出数据,来完成比如 reduceByKey等操作;
- 每个
ShuffleMapTask,都会为每个ResultTask创建一份bucket缓存,以及对应的ShuffleBlockFile磁盘文件 ShuffleMapTask的输出,会作为MapStatus发送到DAGScheduler的MapOutputTrackerMaster中;MapStatus包含了 每个ResultTask要拉取的数据的大小;- 每个
ResultTask会用BlockStoreShuffleFetcher去MapOutputTrackerMaster获取自己的要拉取的文件信息,然后底层通过Blockmanager将数据拉取过来
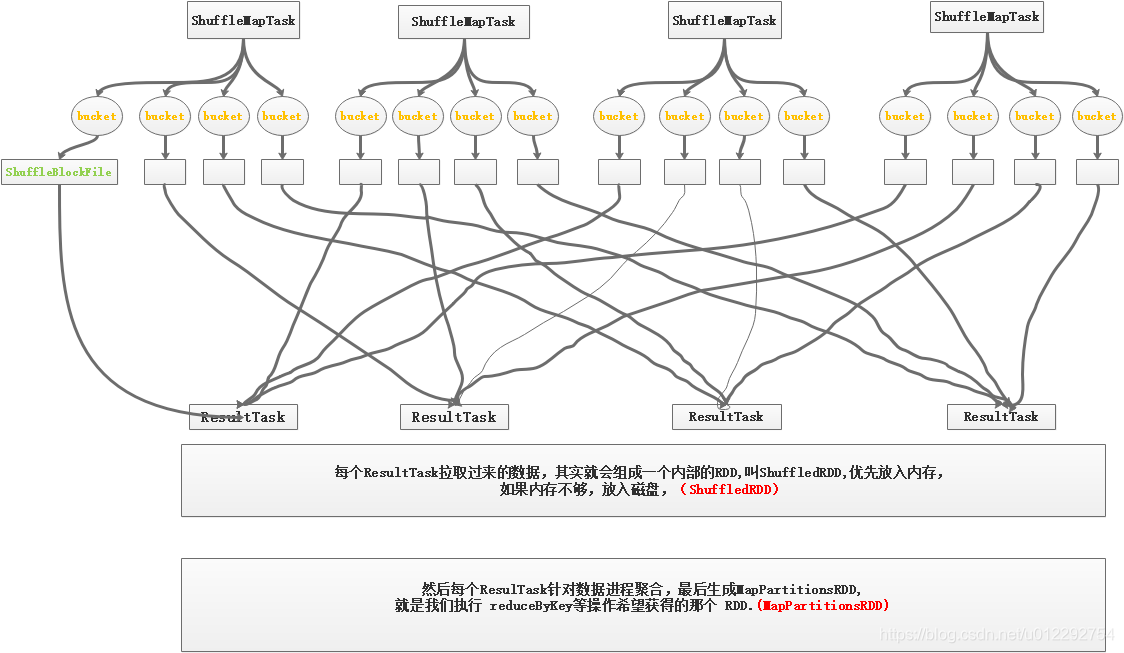
所以假设,如果有100 个 map task ,100 个result task ,
本地磁盘要产生 10000个文件,磁盘 IO 过多,影响性能
2.1 Spark Shuffle 操作的2个特点
2.1.1 特点1
- 在 Spark 早期版本中,bucket 缓存非常重要,因为需要将一个 ShuffleMapTask 所有的数据都写入内存缓存后,才会刷新磁盘。但是这就产生问题,如果 map side 数据过多,很容易造成内存溢出。所以新版本的 spark 中,优化了,默认那个内存是 100kb。然后写入一点数据达到了刷新到磁盘的阈值之后,就会将数据一点点地刷新到磁盘;
- 这种操作的优点,是不容易发生内存溢出。缺点在于,如果内存缓存太小,可能发生太多的磁盘写IO操作;
2.1.2 特点2
- 与 MapReduce 完全不一样的是,MapReduce 必须将所有的数据都写入本地磁盘文件后,才能启动 reduce 操作,来拉取数据。因为 mapreduce 要实现默认的根据 key 的排序。要排序,肯定得写完所有的数据,才能排序,然后 reduce 来拉取;
- Spark 不需要,默认情况下,是不会对数据进行排序的。因此 ShuffleMapTask 每写入一点数据, ResulTask 就可以拉取一点数据,然后在本地执行用户定义的聚合函数和算子,进行计算;
- spark 这种机制的好处在于,速度比 mapreduce 快。但是也有一个问题,mapreduce 提供的 reduce,是可以处理每个 key 对应的 value 上的,很方便。但是 spark ,由于这种实时拉取的机制,因此提供不了直接处理 key 对应的 values 的算子,只能通过 groupByKey ,先 shuffle ,有一个 MapPartitionsRDD,然后用 map 算子,来处理每个 key 对应的 values 。
3 Shuffle 改进

- 在新版本中,引入了
consolidation机制,也就是提出ShuffleGroup的概念; - 一个
ShuffleMapTask将数据写入ResultTask数据的本地文件不变。但是,当下一个ShuffleMapTask运行的时候,可以直接将数据写入之前的ShuffleMapTask的本地文件,相当于是,对多个ShuffleMapTask的输出进行了合并,从而减少本地磁盘的数量;
3.1 优化
假设机器是 2 个 CPU,也就是说 4 个 ShuffleMapTask ,有 2 个 ShuffleMapTask 可以并行执行的。
- 并行执行的
ShuffleMapTask,写入的文件,一定是不同的; - 当一批并行执行的 ShuffleMapTask 运行完之后,那么新的一批ShuffleMapTask 启动起来并行执行的时候,优化机制就开始发挥作用了(
consolidation机制)。 - 开启了
consolidation机制之后的 shuffle write 操作,那么每个节点上的磁盘文件,数量是不是变成了 cpu core数量 * ResultTask 数量。比如每个节点有 2 个 CPU,有100 个ResultTask,那么每个节点一共才 200 个磁盘文件。但是普通的 shuffle ,每一个节点上有2个CPU,100个 ShuffleMapTask,就会产生 100 * 100 个磁盘文件,就是 10000个。 - 优化后的 shuffle 操作,主要通过在
SparkConf中,设置一个参数即可。