原文链接,引用请标明出处
部分译文参考自 https://blog.csdn.net/forever1993/article/details/78405280
摘要
收集注释良好的图像数据集来训练现代机器学习算法对于许多任务而言过于昂贵。 一个有吸引力的替代方案是渲染数据,并在其中自动生成ground truth。不幸的是,纯粹基于渲染图像训练的模型通常无法推广到真实图像。 为解决这个缺点,先前的工作引入了无监督的域自适应算法,该算法试图在两个域之间映射一些表示,或提取域不变的特征。在这项工作中,作者提出了一种新方法,以监督的方式学习像素空间中从一个域到另一个域的变换。本文基于生成对抗网络(GAN)的模型使源域图像看起来好像是从目标域中绘制的。本文的方法不仅产生合理的样本,而且在许多无监督的域适应场景中也以大幅度优于最先进的样本。 最后,作者证明了适应过程推广到训练期间看不到的对象类。
1 引言
大型且注释良好的数据集,例如ImageNet[9],COCO[29]和Pascal VOC[12] 被认为是推动计算机视觉研究的关键。但创建这样的数据集非常昂贵。一种替代方案是使用合成数据进行模型训练。计算机视觉中的长期目标是使用游戏引擎或渲染器来生产几乎无限量的产品标记数据。 实际上,某些研究领域,例如机器人任务的深度强化学习,有效地要求模型在合成领域进行训练,因为在现实环境中的训练可能过于昂贵 [38, 43]。因此,人们对合成领域的训练模型以及在实际环境中应用它们产生了新的兴趣 [8, 48, 38, 43, 25, 32, 35, 37]。不幸的是,对合成数据进行天真训练的模型通常不会推广到真实图像。
该问题的解决方案是使用无监督域适应。 在此设置中,我们希望将从我们已标记数据的源域中获取的知识传输到我们没有标签的目标域。 以前的工作要么尝试查找从源域的表示到目标的表示的映射 [41], 或寻求找到两个域之间共享的域不变表示[14, 44, 31, 5]. 虽然这些方法已经取得了良好的进展,但它们仍然不能与仅在目标领域进行过培训的纯监督方法相提并论。
在这项工作中,我们训练模型以从源域更改图像,使其看起来好像是从目标域中采样,同时保持其原始内容。 我们提出了一种新颖的基于生成对抗网络(GAN)的架构,能够以无人监督的方式学习这种转换,即不使用来自两个域的相应对。 本文无监督像素级域自适应方法(PixelDA)与现有方法相比具有许多优势:
与特定任务的体系结构分离: 在大多数域自适应方法中,域自适应过程和用于推理的任务特定体系结构紧密集成。 无需重新训练整个域适应过程,就无法切换模型的任务特定组件。 相比之下,因为我们的PixelDA模型在像素级别将一个图像映射到另一个图像,所以我们可以更改任务特定的体系结构,而无需重新训练域适配组件。
跨标签空间的泛化: 因为先前的模型将域适应与特定任务相结合,所以源域和目标域中的标签空间被约束为匹配。 相比之下,我们的PixelDA模型能够处理测试时目标标签空间与训练时标签空间不同的情况。
训练稳定性: 依赖某种形式的对抗性培训的领域适应方法 [5, 14] 对随机初始化很敏感。 为了解决这个问题,本文结合了针对源图像和生成图像进行训练的任务特定损失以及允许我们避免模式崩溃的像素相似性正则化 [40] 并稳定培训。通过这些工具能够在模型的不同随机初始化中减少相同超参数的性能差异(第四章)。
数据增强: 传统的域自适应方法仅限于从有限的源和目标数据集中学习。然而,通过调节源图像和随机噪声矢量,本文的模型可用于创建其类似于目标域的图像的大量随机样本。
可解释性: PixelDA(域适应图像)的输出比域自适应特征向量更容易解释。
为了证明本文策略的效果,本文专注于对象分类和姿态估计的任务,其中感兴趣的对象在给定源域和目标域图像的前景中被给出。本文的方法在一系列用于对象分类和姿态估计的数据集上优于最先进的无监督域自适应技术,同时生成看起来与目标域非常相似的图像(参见 图1 )。

图1 使用本文的模型生成的RGBD样本与来自Cropped Linemod数据集的真实RGBD样本 [22, 46]的对比。
每个子图的顶行是图像的RGB部分,底行是相应的深度通道。每列对应于数据集中某个特定对象。更多细节见第四章。
2 相关工作
学习无监督的域适应是一个开放的理论和实践问题。虽然以前的工作很多,但本文的文献综述主要集中在卷积神经网络(CNN)方法,因为它们在问题上具有经验优势 [14, 31, 41, 45]。
无监督域适应: Ganin等[13, 14]和Ajakan等人[3]提出了域-对抗神经网络(DANN):一种经过训练可以提取领域不变特征的架构。他们的模型的前几层被共享到两个分类器:第一个在提供源数据时预测特定于任务的类标签,而第二个分类被训练以预测其输入的域。DANN针对域分类器特定的参数最小化域分类损失,同时相对于两个分类器共有的参数最大化它。通过使用梯度反转层,可以在一个步骤中实现这种minimax优化。虽然DANN的域自适应方法是使从两个域提取的特征相似,但本文的方法是使源图像看起来好像它们是从目标域中提取的。Tzeng等[45]和龙等人[31]提出的DANN变种中域分类损失的最大化被从每个域的样本集中提取的特征之间计算最大平均差异(MMD)度量的最小化所取代[20]。Ghifary等提出了一种替代模型,在这个模型中源域的任务损失与目标域的重建损失相结合,这导出了学习域的不变特征。Bousmalis等[5]引入一个模型,该模型明确地将每个域专用的组件与两个域共有的组件分开。它们利用每个域的重建损失,鼓励域不变性的相似性损失(例如DANN,MMD)和与共同和私有表示组件互补的差异损失。
其他相关技术涉及在特征级别学习从一个域到另一个域的映射。在这种设置中,在域自适应优化期间固定特征提取流水线。这种设定已经应用于各种基于非CNN的方法中[17, 6, 19]以及最近的基于CNN的相关对齐(CORAL)[41]算法。
生成对抗网络: 本文的模型使用GAN[18]以源图像和噪声向量为条件。最近的其他工作也试图使用以图像为条件的GAN。 Ledig等[28]使用了图像为条件的GAN用于超分辨率生成。Yoo等[47]提出通过对模特和所穿的相应的衣服对进行训练,从穿着它们的模特的图像中产生生成衣服图像的任务。以图像和噪声矢量为条件的方法,和本文的方法都不适用于完全不同的问题空间。
与本文最相似的工作是刘和Tuzel[30]他们引入了一对耦合GAN的架构,一个用于源,一个用于目标域,其生成器共享其高层权重,其判别器共享其低层权重。以这种方式,它们能够生成相应的图像对,这种方法可以用于无监督的域自适应。
风格转移: Gatys等人的工作中[15, 16]提出了一种风格转移方法,在保持图像内容固定的同时将图像转移到另一种样式。 该过程需要反向传播回像素。约翰逊等[24]提出了一种前馈式转移模型。他们训练以图像为条件的网络以产生输出图像,其在预训练模型上的激活类似于输入图像(高级内容激活)和单个目标图像(低级激活)。然而,这两种方法都经过优化,可以复制单个图像的样式,而本文的工作试图复制整个图像域的风格。
3 模型
作者首先在图像分类的语境中解释无监督像素级域自适应模型(PixelDA),尽管本文的方法并不特定于此任务。给定源域中的标记数据集和目标域中的未标记数据集,作者的目标是训练来自源域数据的分类器,并将其泛化到目标域。以前的工作使用单个网络执行此任务,该网络执行域自适应和图像分类,使域自适应过程特定于分类器体系结构。本文的模型将域适应过程与分类过程这一特定任务分离,因为它的主要功能是调整源域中的图像,使它们看起来好像是从目标域中采样的。适应过程一旦进行,便可以训练任何现成的分类器以执行手头的任务,就像不需要域适配一样。值得注意的是,本文假设域之间的差异主要是低级别的(由于噪声,分辨率,光照,颜色)而不是高级(物体类型,几何变化等)。
更正式地说,令 代表标记来自源域的 已标注的样本数据集,并令 代表来自目标域的无标签数据集 。本文的像素自适应模型由生成函数 组成,由 参数化,将源域图像 和噪声向量 映射到适应的或假的图像 。给定生成函数 ,可以创建任何大小的新数据集 。最后,给定适应的数据集 ,可以训练针对特定任务的分类器,就如同训练和测试数据来自相同的分布。
3.1 学习
为了训练本文的模型,作者采用生成对抗目标来帮助 生成与目标域类似的图像。在训练期间,生成器 将源图像 和噪声矢量 映射到适应图像 。此外,通过判别器函数 来增强模型,判别器函数 输出从给定目标域采样的图像 的似然性 。判别器试图区分由生成器产生的“假”图像 和来自目标域 的“真实”图像。值得注意的是,与标准GAN公式[18]相反,GAN的生成器仅受噪声矢量调节,而本文的生成器以噪声矢量和来自源域的图像为条件。除了判别器之外,本文还使用分类器 来增强模型,其将任务特定标签 分配给图像 。
本文的方法优化以下的minimax目标:
其中
和
是控制损失之间相互作用的权值。
表示以下的域损失:
是一个针对任务的特定损失,在分类的情况下,用一下的典型交叉熵损失:
其中 是源输入 类别标签的one-hot编码。值得注意的是,作者使用经过适配的和未适配的源图像训练T。当仅在适配的图像上训练T时,可以实现类似的性能,但由于模型的不稳定性,这样做可能需要许多具有不同初始化的运行。确实,如果没有关于源的训练,该模型可以自由地改变分类工作(例如,第一类变成第二类,第二类变成第三类等),同时仍然成功地优化了训练目标。作者发现,源和适配图像上训练的分类器 避免了这种情况,并极大地稳定了训练(见 表5 )。并且可以使用不同的标签空间(见 表4 )。
在本文的实现中, 是具有残差连接的卷积神经网络,其保持原始图像的分辨率,如 图2 所示。判别器D也是卷积神经网络。minimax优化 公式1 通过在两个步骤之间交替来实现:在第一步中,更新判别器和任务特定参数 ,同时保持生成器参数 固定;在第二步中,固定 并更新 。
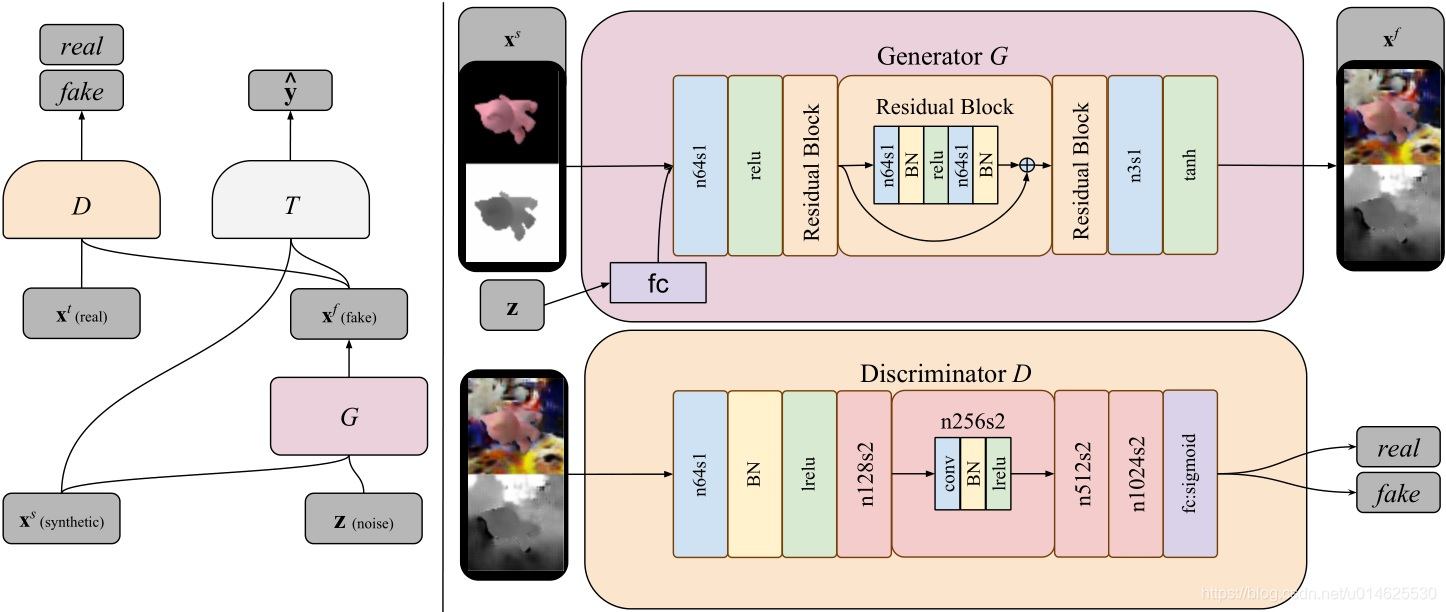
图2 模型体系结构的概述。左侧描绘了遵循[34]样式的整体模型架构。在右侧,作者扩展了生成器和判别器组件的细节。生成器G生成以合成
和噪声矢量
为条件的图像。判别器
区分真实和伪造图像。任务特定的分类器
将特定标签
分配给图像。具有步幅1和64通道的卷积在上图中表示为n64s1。lrelu代表leak-relu非线性单元。BN代表批量标准化层,FC代表完全连接的层。请注意,这里作者没有显示
的细节,因为每个任务的细节不同,并且与域适应过程分离。
3.2 内容相似性损失
在某些情况下有一些关于低级图像适应过程的先验知识。例如,可以预期源和适配图像的色调是相同的。在本文作者的一些实验中,在黑色背景上渲染单个对象,作者期望从这些渲染中改编的图像具有与原图像相似的前景和不同的背景。渲染器通常提供对z-buffer掩码,能够区分前景像素和背景像素。这种先验知识可以通过使用额外的损失来形式化,该损失仅惩罚前景像素的源图像和生成图像之间的大差异。这种相似性损失使生成过程成为原始图像的基础,并有助于稳定极小极大优化,如 第4.4章 和 表5 所示。基于这种考虑,优化目标变成:
其中
是控制这几个损失之间相互左右的权值,
是内容-相似度损失。
许多损失可以以某种有意义的方式将生成的图像对应到原始图像(例如L1或L2损失,预训练VGG网络激活的相似性)。在从渲染图像中学习对象实例分类的实验中,作者使用masked PMSE,它是成对均方误差(PMSE)[11] 的变化。这种损失会惩罚像素对之间的差异,而不是输入和输出之间的绝对差异。作者使用mask版本计算生成的前景和源前景之间的PMSE。形式上,给定二元掩模
,masked PMSE损失可以用如下式子表示:
其中
是输入
中的像素数,
是L2-范数的平方,◦是Hadamard乘积。 这种损失允许模型学习重建被建模物体的整体形状,而不会在输入的绝对颜色或强度上浪费建模能力,同时允许对抗训练使用一致的方式改变对象。值得注意的是,损失不会妨碍前景的改变,而是鼓励前景以一致的方式改变。在这项工作中,由于数据的性质,作者对单个前景对象应用了masked PMSE损失,但是可以将其简单地扩展到多个前景对象。
4 评估
作者在先前工作中使用的对象分类数据集上评估本文的方法,包括MNIST,MNIST-M[14],和USPS[10]以及Cropped Linemod数据集的一种变体[22, 46](一个对象识别和3D姿态估计的标准),作者使用合成和实际数据进行了评估。作者的评估使用了许多无监督的域适应方案,由定性和定量评估组成。定性评估包含通过对生成图像进行视觉评估,来检查本文的方法学习从源域到目标域基础像素适应的能力。 定量评估包含对本文模型与以前的工作性能的比较,以及不使用任何域适应的“只有源”和“只有目标”的baseline的比较。在第一种情况下,仅根据未改变的源训练数据训练模型并评估目标测试数据。在“只有目标”的情况下,仅在目标域训练集上训练模型,并在目标域测试集上进行评估。作者考虑的无监督域适配方案如下所示。
从MNIST到USPS: 来自MNIST[27]的10个数字图像数据集(0-9)用作源域,来自USPS[10]的相同十位数年龄段数据集用作目标域。为了确保 “只有源” 和域适应实验之间的公平比较,作者在最初60000个MNIST训练图像中的50000张图像的子集上对模型进行训练,其余10000张图像用作 “只有来源” 实验的验证集。在本文的实验中使用了USPS的标准拆分,包括6562个训练样本,729个验证样本,和2007张测试图像。
从MNIST到MNIST-M: MNIST[27]数据集的数字作为源域,MNIST-M[14]数据集的数字代表目标域。MNIST-M是为了实现监督域适应变化,在MNIST基础上提出的。它的图像是通过每个MNIST数字为二进制掩码和它的背景图像的颜色反相创建。背景图像是随机从伯克利分割数据集(BSDS500)[4]均匀采样。本文所有的实验遵循[14]的协议。作者使用有1000个标签的59001个MNIST-M训练样本来寻找最优参数。
从合成Cropped Linemod到Cropped Linemod:Cropped Linemod数据集[22]包含一系列在混乱的室内环境中具有各种姿势的小目标图像。作者使用一个版本的数据集[46],每个图像的中心有以下11个目标之一。11个对象里面包含“猿”、“台钳”、“罐子”,“猫”,“电钻”,“鸭子”,“打孔器”,“铁”,“灯”,“电话”,“凸轮”。一个数据集由这些相同的11个物体的CAD模型以各种姿态在黑色背景上呈现,作者称之为合成Cropped Linemod。作者把合成Cropped Linemod作为源数据集,和真实Cropped Linemod作为目标数据集。作者用109208张渲染的源图像用于训练模型,并将9673张真实目标图像用于域适应,使用1000张图像进行验证,目标域有2655张图像用于测试。在此方案下,作者的任务包括分类和姿态估计。因此,针对本任务的网络
输出一个类别 $\hat y $ 和单位四元矢量形式的三维姿态估计
。这个任务的损失可以被写为:
第一和第二项是分类损失,类似于 方程3 ,第三和第四项是三维旋转度量的对数[23]。 是姿态损失的权值, 是样本三维姿态的ground truth, 。 表2 显示的是目标从预测到ground truth(在一个固定的三维轴)[22]需要旋转的平均角度。
4.1 实施细节
所有的模型都使用tensorflow[1]实现,并使用Adam优化器训练[26]。对于 “MNIST到USPS”和“MNIST到MNIST-M”,作者优化 公式1 ;对于“合成Cropped Linemod到Cropped Linemod”,作者优化 公式4 。每个批次有来自各个域的32个样本。输入图像被修正为以零为中心,并重新调整[1,1]的范围。作者让 以卷积残差网络的形式存在,以维持原始图像的重建,如 图2 所示。 是一个有 个元素的向量,每一个都从均匀分布 中采样。然后它被送到全连接层,以将其变换到与图像分辨率相同的信道数,并与输入相拼接作为一个额外的通道。在本文的实验中,作者令 。判别器 是一个卷积神经网络,其层数取决于图像分辨率:第一层是步幅1x1的卷积[33],其次是重复堆叠的步幅 2x2 的卷积,直到降低分辨率到小于或等于 4×4 。 的所有滤波器的数量是64, 第一层的滤波器数目也是64,并在后续层中反复翻番。金字塔的输入被送入一个全连接的域分类损失的单激活函数。为了能与之前的无监督域适应方法相对比,所有的实验用于分类的任务使用了与[14,5]相同的CNN拓扑结构。
4.2 量化结果
现在还没有一种普适的方法来优化监督域适应参数。因此,作者按照[5]的实验方案并使用小集合(1000)标记的目标域数据作为验证集作为超参数,与其他所有方法进行比较。作者用相同的方法进行所有实验,去保证公平、有意义的比较。在这个验证集上的表现可以作为无监督域适应的满意度度量的上界。正如作者在 4.5章 所讨论的那样, 作者也在目标域的1000个标记样本上也评估本文的模型,以确认PixelDA仍然在小的标记样本集上能够提高这个简单的训练方法的效果。
作者使用上述的源和目标数据集的组合评估该模型,在相同任务体系下比较本文模型的与其他state of art的无监督域适应技术的性能。如上所述,为了评估本文模型的有效性,作者首先在“只有源”的设定下比较模型的准确度。这个设定用于评估性能的下界。接下来作者在“只有目标”的设定下比较这些模型。这个设定是为了评估一个弱的上界。可想而知,一个好的监督域适应模型可以改善这些结果。
这些比较的定量结果列于 表1 和 表2 。本文的方法不仅能在“MNIST到MNIST-M”数据集上实现比以前的方法更好的结果,也能够超越“只有目标”的表现。此外,作者还能够在“MNIST到USPS”的情况下实现先进的结果。最后,pixelDA能减少“合成Cropped Linemod到Cropped Linemod”应用下相比以前超过一半的平均角误差。
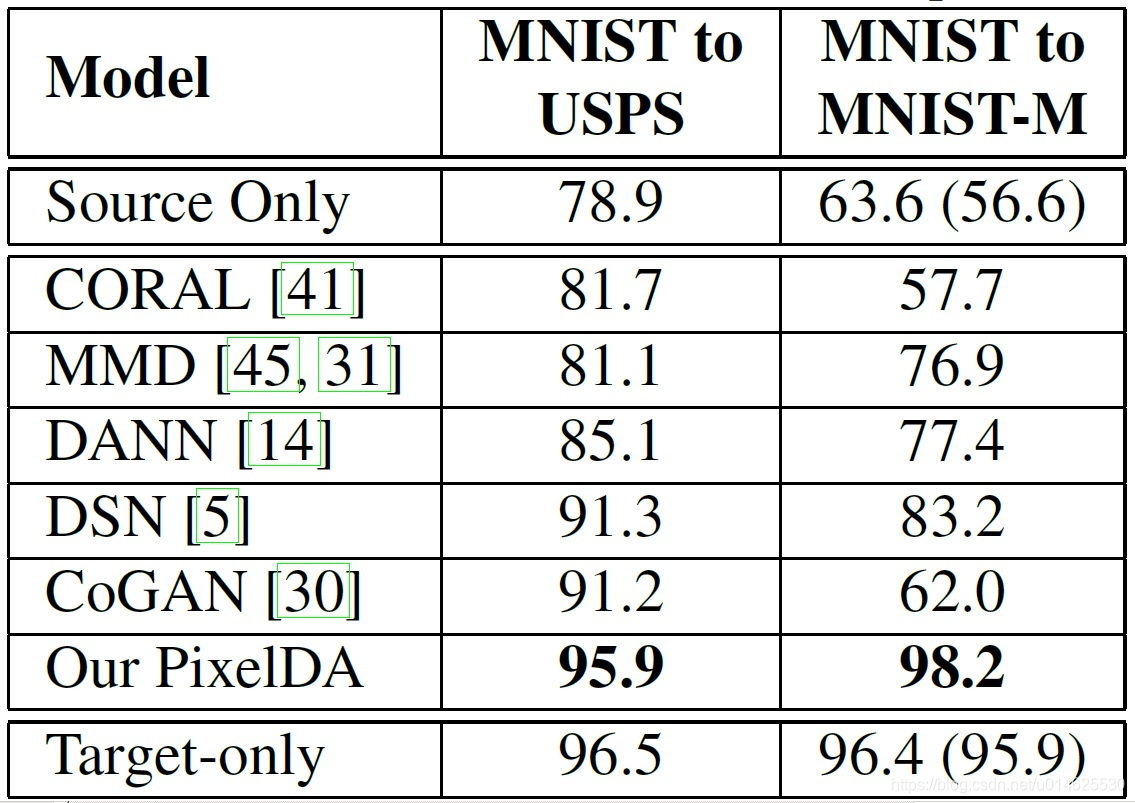
表1 数字数据集的平均分类准确率(%)。“只有源”和“只有目标”两行是不使用域适应训练,只在源或目标域各自训练。本文中源和目标的baseline结果也与之前发表的工作是不同的,它们被注释在括号里。
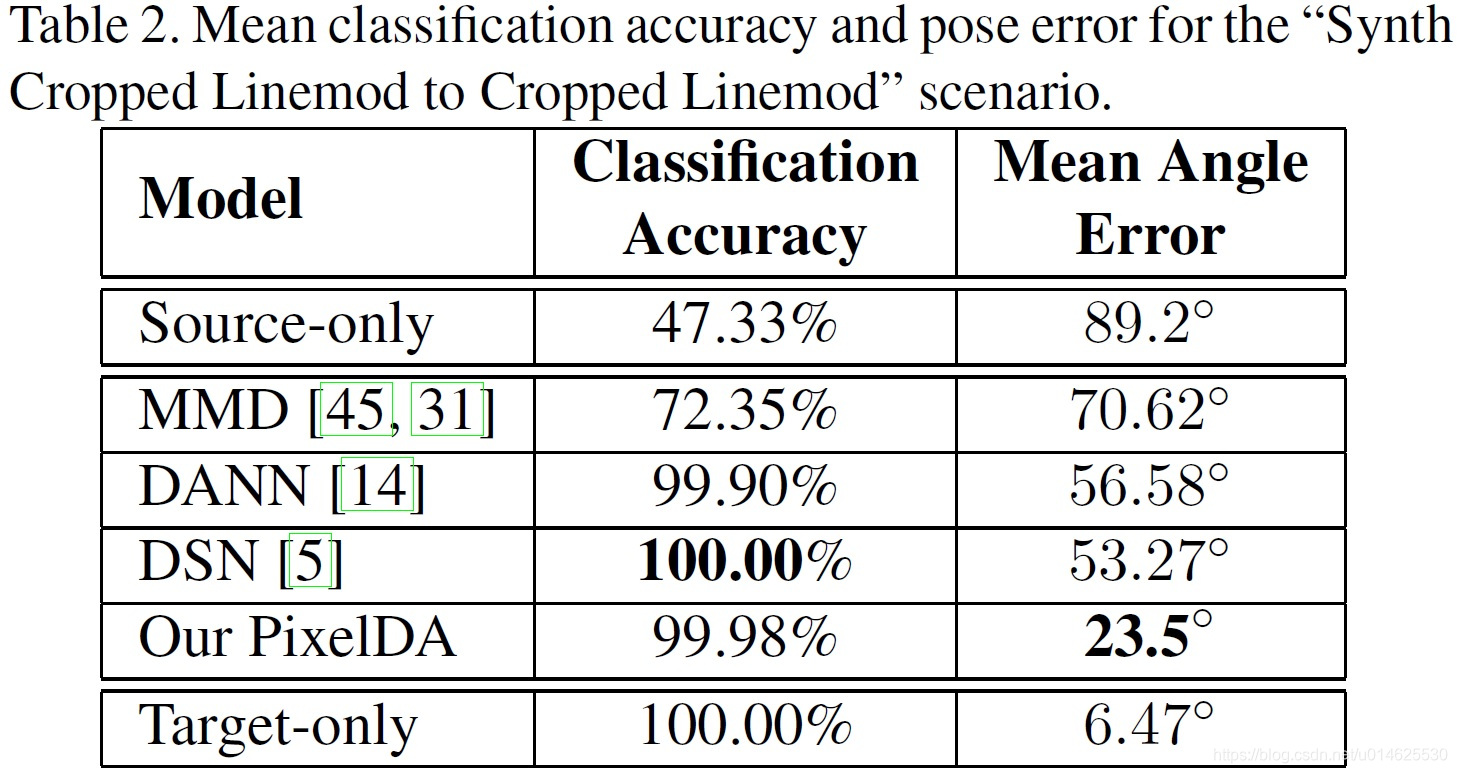
表2 从合成Cropped Linemod到Cropped Linemod的分类精度与姿态误差。
4.3 定性评估
模型的定性结果表示 图1, 图3 ,和 图4 。在 图3 和 图4 人们可以看到生成过程的可视化,以及生成的样本在目标域的最近邻。在这两种情况下,本文的方法的方法能够将原始图像适应变换到所需要的目标域,并使他们看起来像是属于目标域的。要提醒的是,该MNIST-M数字已使用MNIST作为二进制掩码进行生成,去逆转图像背景的颜色。很明显从 图3 在“MNIST到MNIST-M”的情况下,本文的模型不仅仅能够从不同噪声向量
产生背景,但也能学习这种转化过程。图中数字3和6把这一特性展示的很明显。在“合成Cropped Linemod到Cropped Linemod”的情况下,本文的模型能在RGB通道、现实背景中采样,并将前景物体的光度特性调整的与背景一致,并能在深度通道中学习一个合理的噪声模型。
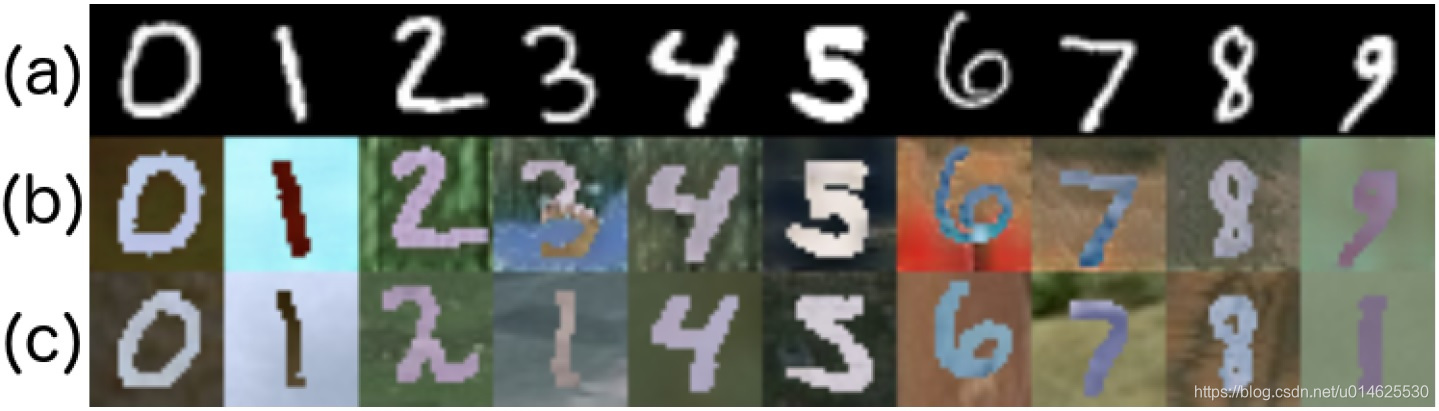
图3 本文的模型在训练使MNIST适应到MNIST-M时,生成样本的能力的可视化。
(a)来自MNIST的源图像
;(b)使用
采样得到的样本;
(c)中间行中生成的样本的MNIST-M训练集中的最近邻居。
中间行和底行之间的差异表明该模型没有记住目标数据集。

图4 将合成Cropped Linemod适应到Cropped Linemod时,模型生成能力的可视化。
第一行:来自合成Cropped Linemod的源RGB和深度图像对
;
第二行:使用模型
与随机噪声
所适配产生的样本;
第三行:第二行中的生成图像在目标训练集的近邻。
生成的图像和目标图像之间的差异表明,模型没有记住目标数据集。
4.4 模型分析
作者提出了一些额外的实验证明该模型的工作原理,并探讨该模型潜在的局限性。
所使用背景的敏感性 在“MNIST到MNIST-M”、“合成Cropped Linemod到Cropped Linemod”两个应用场景下,源域是在黑色背景上的数字或物体的图像。作者的定量评价( 表1 和 表2 )说明本文的模型将源图像适配到目标域风格的能力。但这里面有两个问题:它是重要的源图像的背景是黑色的,如何成功的数据增强策略,使用一个随机选择的背景图片呢?作者进行了额外的实验,作者用各种背景替代了Cropped Linemod合成数据集的黑色背景。背景是从ImageNet数据集中随机选择的。在这些实验中只使用图像的RGB部分的源和目标域,因为没有相当的“背景”深度通道。如 表3 所示,pixelDA能够在黑色或者随机ImageNet背景的情况下提升“只有源”的模型。
模型的泛化能力 模型的另外两个方面也与其性能有关。首先是模型是成功的学习了像素级数据适应的过程,还是是简单的记忆目标图像,并把它的原图像替代为目标图像集?其次,训练中的模型是否能在不限定的目标类之间进行泛化?
为了回答第一个问题,作者首先运行生成器
从源图像创建一个适应数据集。此后,对每个变换后的图像,作者用像素空间 L2 最近邻查找目标训练图像,来确定模型是否是简单的从目标数据集记忆图像。 图3 和 图4 的第一行样本来自
,中间行是
产生的样本,第三行是训练集中最近邻的目标。很显然,模型并不是简单记住目标训练集的图像。
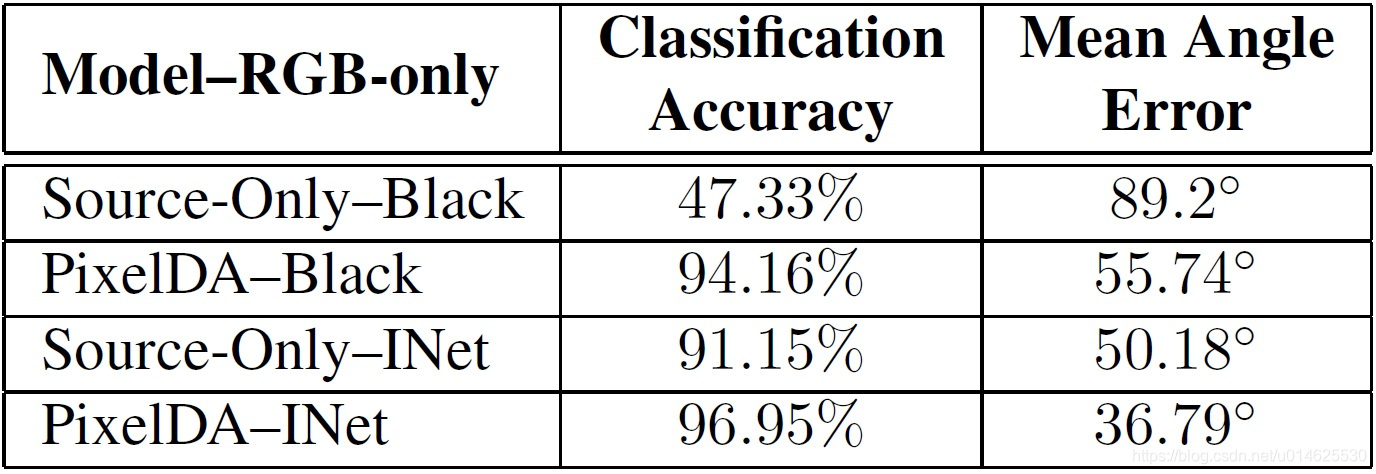
表3 平均分类准确率和到源域的位置姿态误差。这些实验只使用图像的RGB部分,没有把背景添加到深度图像中。为了进行对比,作者显示了在“只有源”的设定和只有RGB设定下黑色背景和Imagenet的背景(INet)的结果。
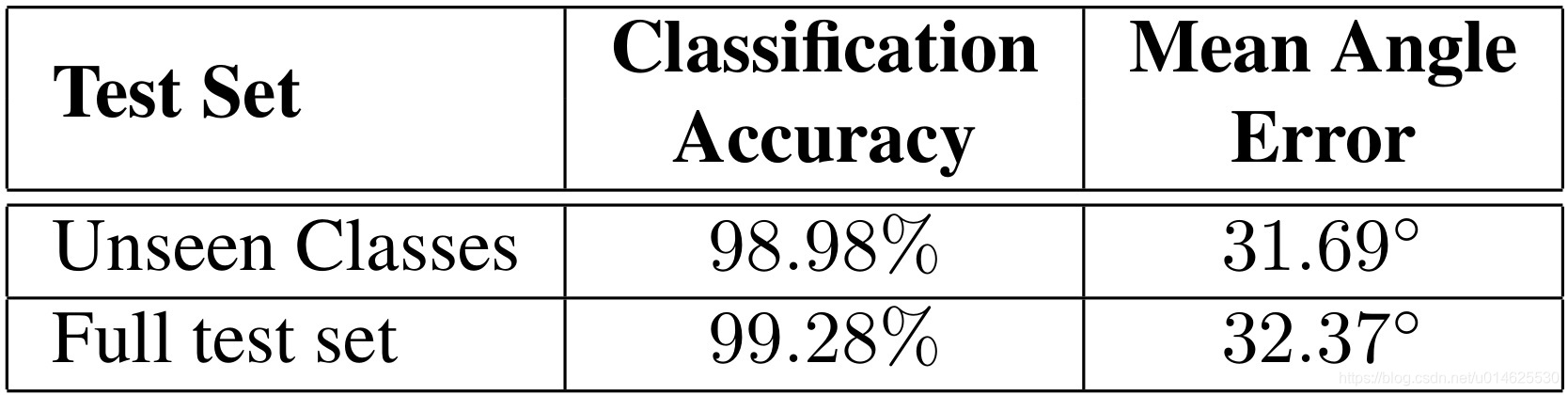
表4 本文的模型在Cropped Linemod对象的11个中的6个上训练。
第一行,“看不见的类,对剩余的5五个没有训练的Cropped Linemod目标的所有样本上显示的性能。
第二行,全测试集,在所有设置11个对象的目标域测试的性能。
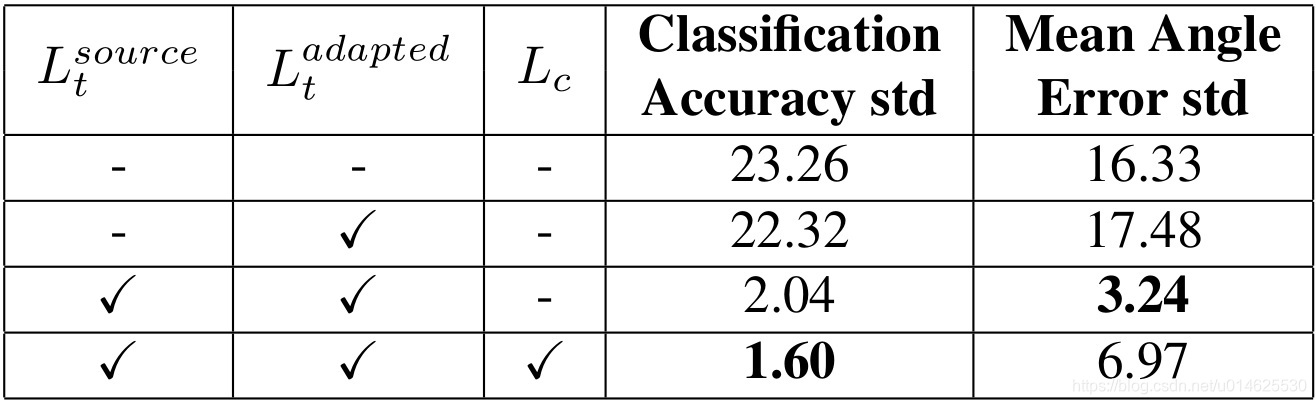
表5 使用任务和内容损失
的标准差(std)在“合成Cropped Linemod到Cropped Linemod”的情景的场景下对模型性能的研究。
意味着使用源数据训练
;
意味着使用生成数据训练
;
意味着使用本文的内容–相似性损失。低的标准差意味着结果更容易复制。
接下来,作者对模型推广到训练期间看不到的类的能力进行了评估。为此,作者使用来自源域和目标域的图像子集重新训练文中的模型,其中仅包括“合成Cropped Cropped Cropped Linemod”到“Cropped Cropped Linemod”场景中一半的对象类。具体而言,物体“猿”、“蓝色台钳”、“罐子”、“猫”、“电钻”、“鸭子”这几类在训练中可以被观察到,而其他对象只能用于测试期间。当 是被训练时,其权值被锁定,并将源域的整个训练集传递到用于训练任务分类器 的生成图像。然后作者在未观测到的全集上(6060个样本)探讨了 的性能,并与所有物体目标域的测试集进行对比,结果如 表2 所示。
稳定性研究 作者还探讨了模型的不同组成部分的重要性。作者表明,虽然任务和内容的损失不提高模型的整体性能,他们显著地稳定了训练。训练不稳定是生成对抗模型的一个共同特点,因此预防模型发散、模型崩溃[40]的策略是很必要的。作者通过使用不同的随机参数初始化运行每个模型10次,但使用相同的超参数来测量模型性能的标准偏差。 表5 说明了任务和内容相似性损失降低了不同次运行之间的可变性。
4.5 半监督学习的实验
最后,作者在半监督设定下评估本文的模型,假设有一个数目较小的已标记目标的训练集。在分类器
的训练期间,半监督版本的模型简单的使用增量训练样本作为输入。作者从Cropped Linemod采样1000个样本,这些样本在之前的训练过程中没有被使用过,作者使用它们作为额外的训练数据。作者在Cropped Linemod目标域的测试集上针对以下2个baseline评估本文模型的半监督版本:
(a)仅对这1000个目标样本训练分类器,而没有任何域适应,称之为“1000-only”;
(b)对1000个目标样本和整个没有域适应的合成Cropped Linemod训练集进行分类训练, 这一设置称为“Synth+1000”。从 表6 中可以看出,本文的模型有明显的提高。PixelDA利用这些样本来实现比在完全无监督的设置更好的性能(表2)。

表6 半监督实验的“合成Cropped Linemod到Cropped Linemod”的情景。当一个有1000个已经目标数据的小集合被提供给模型,这个小集合能够提高训练的准确率,高于两个baseline:(1)只有一千个样本;(2)有标记目标样本的合成增强训练集。
5 结论
作者提出了无监督的领域适应的一个state of the art的方法。PixelDA模型比以前的无监督域适应方法表现更好,并在具有挑战性的“合成Cropped Linemod到Cropped Linemod”的情况下,PixelDA模型相比以前的最好成绩减小了一半以上误差。本文的方法能够做到利用GAN为基础的技术,通过一个特定任务的损失和一个新的内容–相似损失稳定地训练。此外,本文的模型将域适应过程与特定任务的架构分离,并通过适应图像的可视化,提供了易于理解的图像输出。
致谢
作者要感谢Luke Metz,Kevin Murphy,Augustus Odena,Ben Poole,Alex Toshev,Vincent Vanhoucke等对于初稿所提出的的建议。
参考文献
[1] M. Abadi et al. Tensorflow: Large-scale machine learning on heterogeneous distributed systems. Preprint arXiv:1603.04467, 2016.
[2] D. B. F. Agakov. The im algorithm: a variational approach to information maximization. In Advances in Neural Information Processing Systems 16: Proceedings of the 2003 Conference, volume 16, page 201. MIT Press, 2004.
[3] H. Ajakan, P. Germain, H. Larochelle, F. Laviolette, and M. Marchand. Domain-adversarial neural networks. In
Preprint, http://arxiv.org/abs/1412.4446, 2014.
[4] P. Arbelaez, M. Maire, C. Fowlkes, and J. Malik. Contour detection and hierarchical image segmentation. TPAMI, 33(5):898–916, 2011.
[5] K. Bousmalis, G. Trigeorgis, N. Silberman, D. Krishnan, and D. Erhan. Domain separation networks. In Proc. Neural
Information Processing Systems (NIPS), 2016.
[6] R. Caseiro, J. F. Henriques, P. Martins, and J. Batist. Beyond the shortest path: Unsupervised Domain Adaptation by
Sampling Subspaces Along the Spline Flow. In CVPR, 2015.
[7] X. Chen, Y. Duan, R. Houthooft, J. Schulman, I. Sutskever, and P. Abbeel. Infogan: Interpretable representation learning by information maximizing generative adversarial nets. arXiv preprint arXiv:1606.03657, 2016.
[8] P. Christiano, Z. Shah, I. Mordatch, J. Schneider, T. Blackwell, J. Tobin, P. Abbeel, and W. Zaremba. Transfer from
simulation to real world through learning deep inverse dynamics model. arXiv preprint arXiv:1610.03518, 2016.
[9] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei. ImageNet: A Large-Scale Hierarchical Image Database. In CVPR09, 2009.
[10] J. S. Denker, W. Gardner, H. P. Graf, D. Henderson, R. Howard, W. E. Hubbard, L. D. Jackel, H. S. Baird, and
I. Guyon. Neural network recognizer for hand-written zip code digits. In NIPS, pages 323–331, 1988.
[11] D. Eigen, C. Puhrsch, and R. Fergus. Depth map prediction from a single image using a multi-scale deep network. In NIPS, pages 2366–2374, 2014.
[12] M. Everingham, S. A. Eslami, L. Van Gool, C. K. Williams, J. Winn, and A. Zisserman. The pascal visual object classes challenge: A retrospective. International Journal of Computer Vision, 111(1):98–136, 2015.
[13] Y. Ganin and V. Lempitsky. Unsupervised domain adaptation by backpropagation. arXiv preprint arXiv:1409.7495, 2014.
[14] Y. Ganin et al. Domain-Adversarial Training of Neural Networks. JMLR, 17(59):1–35, 2016.
[15] L. A. Gatys, A. S. Ecker, and M. Bethge. A neural algorithm of artistic style. arXiv preprint arXiv:1508.06576, 2015.
[16] L. A. Gatys, A. S. Ecker, and M. Bethge. Image style transfer using convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2414–2423, 2016.
[17] B. Gong, Y. Shi, F. Sha, and K. Grauman. Geodesic flow kernel for unsupervised domain adaptation. In CVPR, pages 2066–2073. IEEE, 2012.
[18] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D.Warde-Farley, S. Ozair, A. Courville, and Y. Bengio. Generative
adversarial nets. In Advances in Neural Information Processing Systems, pages 2672–2680, 2014.
[19] R. Gopalan, R. Li, and R. Chellappa. Domain Adaptation for Object Recognition: An Unsupervised Approach. In ICCV, 2011.
[20] A. Gretton, K. M. Borgwardt, M. J. Rasch, B. Sch¨olkopf, and A. Smola. A Kernel Two-Sample Test. JMLR, pages
723–773, 2012.
[21] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In Computer Vision and Pattern Recognition (CVPR), 2016 IEEE Conference on, 2016.
[22] S. Hinterstoisser et al. Model based training, detection and pose estimation of texture-less 3d objects in heavily cluttered scenes. In ACCV, 2012.
[23] D. Q. Huynh. Metrics for 3d rotations: Comparison and analysis. Journal of Mathematical Imaging and Vision,
35(2):155–164, 2009.
[24] J. Johnson, A. Alahi, and L. Fei-Fei. Perceptual losses for real-time style transfer and super-resolution. arXiv preprint arXiv:1603.08155, 2016.
[25] M. Johnson-Roberson, C. Barto, R. Mehta, S. N. Sridhar, and R. Vasudevan. Driving in the matrix: Can virtual worlds replace human-generated annotations for real world tasks? arXiv preprint arXiv:1610.01983, 2016.
[26] D. Kingma and J. Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
[27] Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner. Gradientbased learning applied to document recognition. Proceedings of the IEEE, 86(11):2278–2324, 1998.
[28] C. Ledig, L. Theis, F. Huszar, J. Caballero, A. Aitken, A. Tejani, J. Totz, Z. Wang, and W. Shi. Photo-realistic single image super-resolution using a generative adversarial network. arXiv preprint arXiv:1609.04802, 2016.
[29] T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Doll´ar, and C. L. Zitnick. Microsoft coco: Common objects in context. In European Conference on Computer Vision, pages 740–755. Springer, 2014.
[30] M.-Y. Liu and O. Tuzel. Coupled generative adversarial networks. arXiv preprint arXiv:1606.07536, 2016.
[31] M. Long and J. Wang. Learning transferable features with deep adaptation networks. ICML, 2015.
[32] A. Mahendran, H. Bilen, J. Henriques, and A. Vedaldi. Researchdoom and cocodoom: Learning computer vision with games. arXiv preprint arXiv:1610.02431, 2016.
[33] A. Odena, V. Dumoulin, and C. Olah. Deconvolution and checkerboard artifacts. http://distill.pub/2016/deconvcheckerboard/, 2016.
[34] A. Odena, C. Olah, and J. Shlens. Conditional Image Synthesis With Auxiliary Classifier GANs. ArXiv e-prints, Oct. 2016.
[35] W. Qiu and A. Yuille. Unrealcv: Connecting computer vision to unreal engine. arXiv preprint arXiv:1609.01326, 2016.
[36] A. Radford, L. Metz, and S. Chintala. Unsupervised representation learning with deep convolutional generative adversarial networks. CoRR, abs/1511.06434, 2015.
[37] S. R. Richter, V. Vineet, S. Roth, and V. Koltun. Playing for data: Ground truth from computer games. In European
Conference on Computer Vision, pages 102–118. Springer, 2016.
[38] A. A. Rusu, M. Vecerik, T. Roth¨orl, N. Heess, R. Pascanu, and R. Hadsell. Sim-to-real robot learning from pixels with progressive nets. arXiv preprint arXiv:1610.04286, 2016.
[39] K. Saenko et al. Adapting visual category models to new domains. In ECCV. Springer, 2010.
[40] T. Salimans, I. Goodfellow,W. Zaremba, V. Cheung, A. Radford, and X. Chen. Improved techniques for training gans. arXiv preprint arXiv:1606.03498, 2016.
[41] B. Sun, J. Feng, and K. Saenko. Return of frustratingly easy domain adaptation. In AAAI. 2016.
[42] C. Szegedy, V. Vanhoucke, S. Ioffe, J. Shlens, and Z. Wojna. Rethinking the inception architecture for computer vision. arXiv preprint arXiv:1512.00567, 2015.
[43] E. Tzeng, C. Devin, J. Hoffman, C. Finn, X. Peng, S. Levine, K. Saenko, and T. Darrell. Towards adapting deep visuomotor representations from simulated to real environments. arXiv preprint arXiv:1511.07111, 2015.
[44] E. Tzeng, J. Hoffman, T. Darrell, and K. Saenko. Simultaneous deep transfer across domains and tasks. In CVPR, pages 4068–4076, 2015.
[45] E. Tzeng, J. Hoffman, N. Zhang, K. Saenko, and T. Darrell. Deep domain confusion: Maximizing for domain invariance. Preprint arXiv:1412.3474, 2014.
[46] P. Wohlhart and V. Lepetit. Learning descriptors for object recognition and 3d pose estimation. In CVPR, pages 3109–3118, 2015.
[47] D. Yoo, N. Kim, S. Park, A. S. Paek, and I. S. Kweon. Pixel level domain transfer. arXiv preprint arXiv: 1603.07442,
2016.
[48] Y. Zhu, R. Mottaghi, E. Kolve, J. J. Lim, A. Gupta, L. Fei-Fei, and A. Farhadi. Target-driven visual navigation in
indoor scenes using deep reinforcement learning. arXiv preprint arXiv: 1609.05143, 2016.