总说
这篇主要是如何一步步说明RNN和LSTM的形式的构造,方便对模型有一个更直观的理解。写的比较随意。
RNN
我们知道,卷积是一个输入,得到一个输出。但有时候我们想输出一串,然后得到一串输出呢?并且是这一串都是相互有关联的,比如句子翻译。我们就需要一种能针对历史信息进行融合的单元,比如RNN。其实想想,只要以某种形式,将历史信息与当前输入进行有效融合的方式,应该都可以处理类似的问题。
和CNN的区别是,RNN有一个隐层状态
比如第一次,我们先设置一个
我们通过增加了一个隐层状态,从而使得RNN能够将当前输入与历史输入进行有效的融合。隐层状态是历史信息的载体。
对于每次新的输入
RNN还要有输出,既然是迭代的,显然对于第
所以自然就有下面:
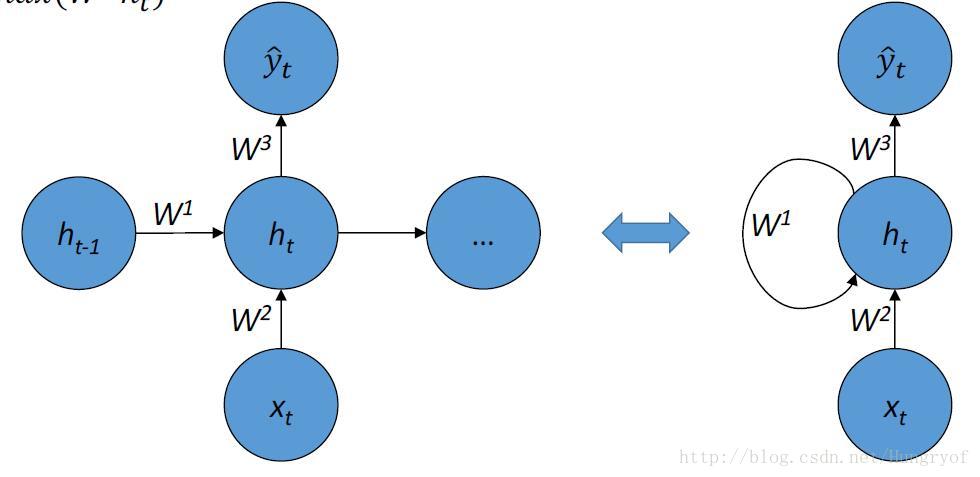
值得注意的是,这幅图左边是展开形式。那么要定义给一个RNN,我们当然要定义这个
看看pytorch的对应函数,emmm,没啥问题。默认的隐层激活函数是tanh, 也可以选择 relu.

num_layers是什么?
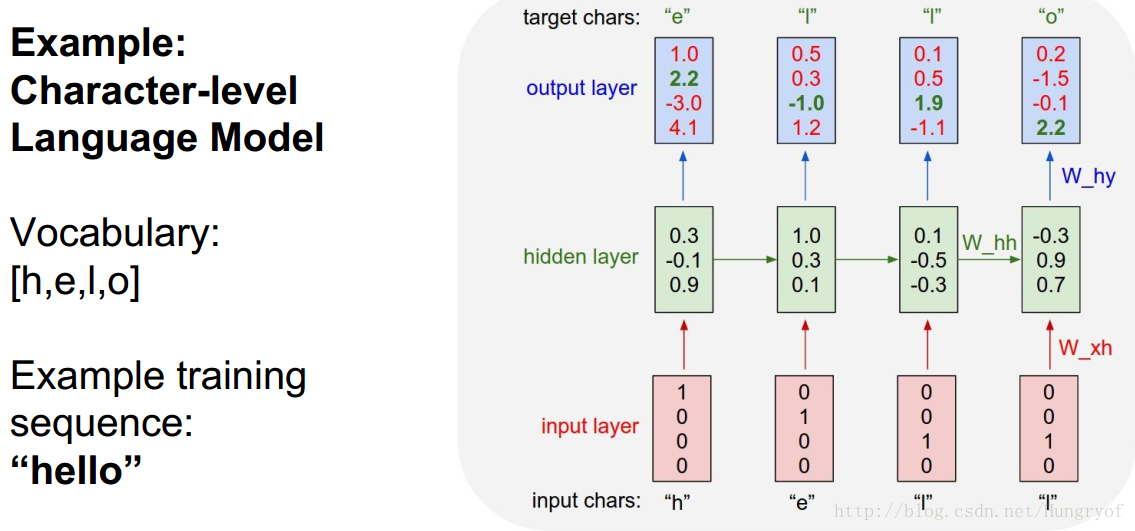
是RNN有多少层,前面看到的都是一层的RNN。比如很经典的预测下一个字母:
输入是one-hot形式的4*1向量,红色层是输入层。隐层浅绿色,状态是3*1。因此
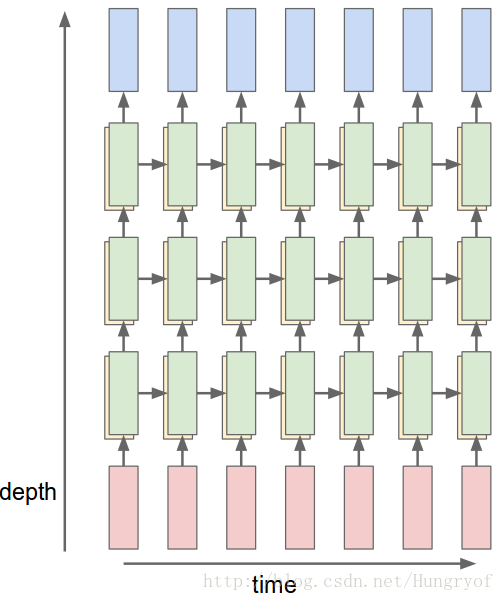
前面的例子都是,输入经过经过一次线性变换,成为隐层状态,再经过一次线性变换,直接变成输出了。为了增加复杂性,可以让隐层状态经过多次线性变换,再到输出。这就是多层RNN!
下面是3层的(绿色代表深度为3的隐层,红色是输入层,蓝色是输出层)
BPTT
反向传播的梯度推导如下,看看就行。



显然容易出现梯度爆炸或者梯度消失的现象。对于梯度爆炸,直接梯度裁剪就行。但是梯度消失,就不好弄了,你不可能直接乘以一个数吧~~。
如何解决RNN的梯度消失问题
看看原来咋弄的:
原来的当前隐层状态的得到,是直接将当前输入和上一次迭代的隐层状态,进行简单融合。那么求导时,自然就会有连乘形式,那就容易爆炸或是消失啊! 要不转换成“连加”吧。
现在是,上一次迭代的隐层状态和当前的输入,融合后的

注意:后面
一个更好的解决梯度消失的办法
其实上面的模型可能还是有点简单,原因在于
其中
值得注意的是:
为什么设置
个人认为效果很可能会降低。我们是不知道针对已有的状态
既然有针对隐层状态的门了,同理可以定义针对“input”和“output”的门。
再次升级模型v2
我们可以看到
其实我们想想,当前状态
模型2.0:
我们看到了,
再次升级到v3
既然我们已经让“状态和已有的状态
其实想到这里,应该挺兴奋了,因为现在的模型已经想的比较复杂了,建模能力应该挺高了。
ummm,想想怎么加啊。之前已经是这样的形式了:
比如RNN时,对
然后我们需要把output门,作用在“前面的经过input门和forget门得到的东西”。嗯,既然说到这里了,我们就不能用
我们将“经过input门和forget门得到的东西,称为
注意这里有一个tanh。
进过遗忘门,输入门以及输出门,这三个门的作用,我们得到了
LSTM
前面的模型进化到v3时,就已经是LSTM了。
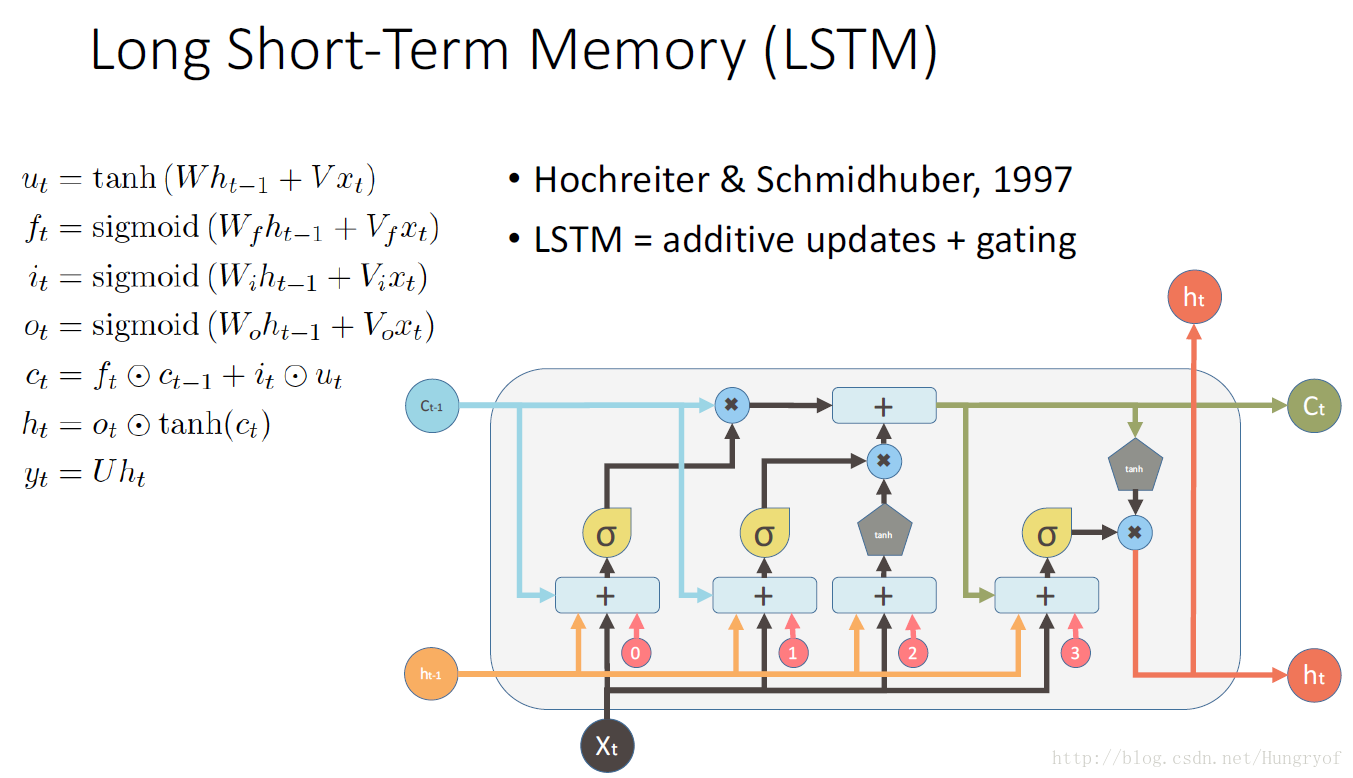
再来简单回顾一下:
我们建立了三个门:
所以上面的公式应该很容易理解了,另外一点是,这个论文的原版设置就是,中间三个门用sigmoid来弄,其他两个用tanh来弄。其实你sigmoid换成tanh也差不多的,只要是原点处是单调平滑递增的就行。不过可能当时提出来的时候,用sigmoid可以时得到的矩阵的值介于0-1之间,类似一种权重分配吧,比较符合直观。
TODO
加入GRU和其他变体,等理解更加深刻之后再完善吧。。又立flag了~哈哈
pytorch中的lstm
具体用法看文档。
一个例子:
x = self.CNN(x) # CNN是vgg
x = x.view(x.size()[0], 512, -1) # 将spatial size拉成向量
# (batch, input_size, seq_len) -> (batch, seq_len, input_size)
x = x.transpose(1, 2)
# (batch, seq_len, input_size) -> (seq_len, batch, input_size)
x = x.transpose(0, 1).contiguous() #一定要转成这种形式
x, _ = self.LSTM1(x)其中LSTM可能是:
self.BiLSTM1 = nn.LSTM(input_size=nIn, hidden_size=nHidden, num_layers=1, dropout=0)conv-lstm
以前lstm的那些权重都是线性变换矩阵,但是有些是用卷积来做的。比如:
Convolutional LSTM Network: A Machine LearningApproach for Precipitation Nowcasting.
代码例子:
https://github.com/Atcold/pytorch-CortexNet/blob/master/model/ConvLSTMCell.py