1.背景
一般我们进行小说网的爬取,大致思路都是先获取小说网页的html内容,然后使用正则表达式找到对应的章节以及其对应的url。BeautifulSoup是用Python写的一个HTML/XML的解析器,它可以很好的处理不规范标记并生成剖析树(parse tree)。 它提供简单又常用的导航(navigating),搜索以及修改剖析树的操作。使用BeautifulSoup来爬取小说网,将大大减少正则表达式的使用,提高效率。
2.代码解析
2.1导包
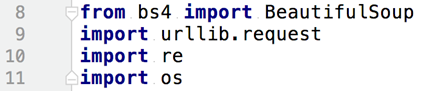
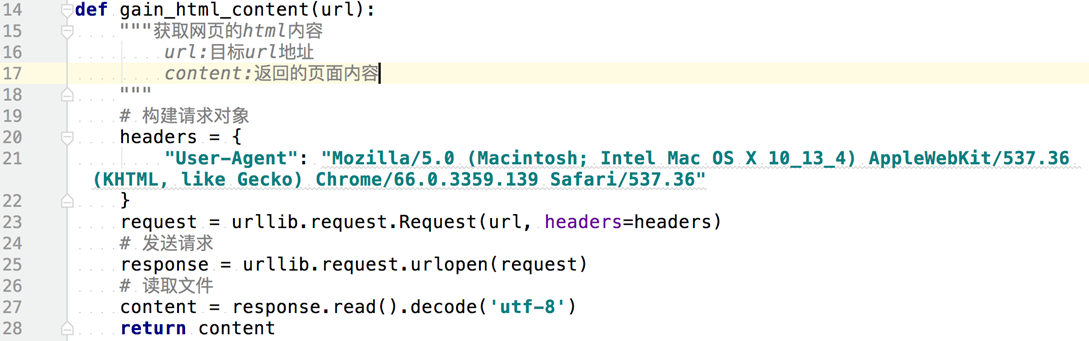
2.2函数获取html页面的内容
向函数传入一个url,函数会构造一个url请求,向目标url发送请求并获取响应对象,然后读取获得的内容,再返回。
2.3函数获取小说的章节目录
向函数传入一个html页面的内容,这里传入应该是具体小说的首页,也就是有章节目录的那个页面,函数获取章节目录页面的内容后,先构建一个soup对象,紧接着运用soup对象里面的方法,分别获取小数的标题和章节名称以及其对应的url,最后以字典的形式返回。

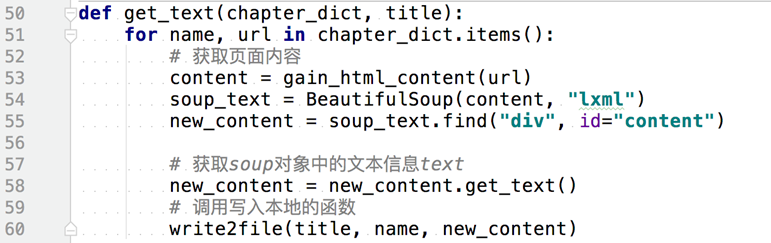
2.4函数获取小说的文本内容
向函数传入以章节名称和对应的url为键值对的字典和小说标题,函数遍历这个字典,调用gain_html_content 函数获得小说的html页面的内容,然后构建soup对象,并直接找到小说文章内容的标签,并获取其中的文本信息,最后调用write2file函数,写入本地txt文件。
2.5将小说内容写入本地文件
这个就没啥好说的了,直接将小说文本内容,写入本地。

2.6代码总览
-
# -*- coding: utf-8 -*-
-
# @Time : 2018/5/21 09:08
-
# @Author : daigua
-
# @File : 12-笔趣阁-beautifulsoup.py
-
# @Software: PyCharm
-
-
-
from bs4 import BeautifulSoup
-
import re
-
import urllib.request
-
import os
-
-
-
def gain_html_content(url):
-
"""获取网页的html内容
-
url:目标url地址
-
content:返回的页面内容
-
"""
-
# 构建请求对象
-
headers = {
-
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36"
-
}
-
request = urllib.request.Request(url, headers=headers)
-
# 发送请求
-
response = urllib.request.urlopen(request)
-
# 读取文件
-
content = response.read().decode('utf-8')
-
return content
-
-
-
def get_chapter(content):
-
# 先构建一个soup对象
-
soup = BeautifulSoup(content, "lxml")
-
# 获取小说的标题
-
title = soup.title.string
-
# 找到小说的内容(是在div标签里面,并且这个div标签的id为"list")
-
content = soup.find("div", id="list")
-
# 获取章节列表,列表里面的内容都是标签对象
-
chapter_list = content.find_all("a", attrs={"style": "", "href": re.compile(r"/.*\.html")})
-
# 定义一个空的字典,用于存放章节名称和对应url的键值对
-
chapter_dict = dict()
-
for x in chapter_list:
-
file_name = x.string
-
file_url = x.attrs["href"] # 获取a标签中href属性里面的值
-
chapter_dict[file_name] = "https://www.xs.la" + file_url
-
# 将章节字典,和标题返回
-
return chapter_dict, title
-
-
-
def get_text(chapter_dict, title):
-
for name, url in chapter_dict.items():
-
# 获取页面内容
-
content = gain_html_content(url)
-
soup_text = BeautifulSoup(content, "lxml")
-
new_content = soup_text.find("div", id="content")
-
-
# 获取soup对象中的文本信息text
-
new_content = new_content.get_text()
-
# 调用写入本地的函数
-
write2file(title, name, new_content)
-
-
-
def write2file(title, file_name, content):
-
"""将小说写入本地文件"""
-
print("%s下载中。。。" % file_name)
-
direction = title + "/" + file_name
-
if not os.path.exists(title):
-
os.mkdir(title)
-
with open(direction + ".txt", 'w') as f:
-
f.write(content)
-
print("%s下载完毕!" % file_name)
-
-
-
def main():
-
# 获取页面内容
-
tar_url = input("请输入小说网址:")
-
content = gain_html_content(tar_url)
-
# 获取 章节名字:url 字典和小说标题
-
dict1, title = get_chapter(content)
-
# 获取小说内容,并写入本地txt文件
-
get_text(dict1, title)
-
-
-
if __name__ == "__main__":
-
main()
4.一些说明
- 本例中用到一些BeautifulSoup的方法,都可以在网上查得到,所以本例并未对其具体用法进行说明;
- 本例只是一个小测试,所以还存在一些问题,比如爬到一半断网,重新爬取的时候又得从头开始,还有本例使用的是单任务,效率没有多任务高,这些问题改进就由各位去做了,本例主要目的只是展现爬取小说网的思路。