分享一下我老师大神的人工智能教程!零基础,通俗易懂!http://blog.csdn.net/jiangjunshow
也欢迎大家转载本篇文章。分享知识,造福人民,实现我们中华民族伟大复兴!
和经典的强化学习 Reinforcement Learning 最大的区别是,它将直接处理像素级的超高维度raw image state input, 而非事先人为的抽象将状态抽象为低维度state。更加贴近现实的状况。
赶紧趁着课程项目的机会,试试这个想法。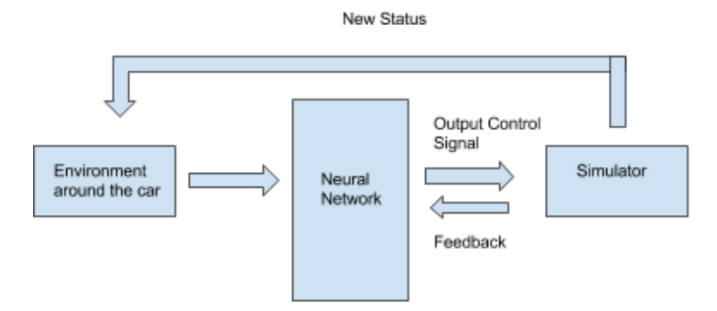
回去一做文献查阅,一看发现,唉?已经有很成熟的一个领域叫做 Deep Reinforcement Learning 在用非常类似且完备的方法去这么做了,而且创始还是由Deepmind公司的人开始做的。Deepmind最出名的就是Alpha Go了,在这之前他们用Deep Q Learning 来玩 Atari 2600游戏,玩的比人还要好,非常有意思。 看来‘创新’失败,不过花了一学期利用课程项目的机会好好学了学这个领域也是非常有收货。趁着圣诞假期记录下来,分享心得给大家,也给自己一个回顾。
Deep Reinforcement Learning 最初始的成功算法莫属 Deep Q Learning. 这个算法可以通过直接观察 Atari 2600的游戏画面和得分信息,自主的学会玩游戏,并且一个算法对几乎所有的游戏通用,非常强大,论文发表在了Nature上。
- Q Learning
在了解 Deep Q Learning 之前,先来了解下他的鼻祖 Q Learning。这也是一个在强化学习领域非常经典的算法。
(推荐阅读David Silver的强化学习课程 UCL Course on RL)
在这儿我们以赛车游戏为例子来说理论上如何应用Q Learning解决玩赛车游戏的。
先解释一些符号表示的意义,接下来会在整篇中用到:
- State s: 在每一个时间节点,agent(车) 所处的环境的表示即为State,例如整个游戏画面,或者已经抽象为位置,方向,障碍物位置等的信息。
- Action a: 在每一个 state 中,agent 可以采取的动作即为Action. 例如前,后,左,右,刹车,油门。每采取一个 action, agent 将相应会到下一个 state (可以理解为车往前开了,环境就相应变化了)。
- Reward r: 每到一个state,agent 就有可能会收到一个 reward 反馈,例如撞了墙就会收到一个负的反馈,而如果顺利到达终点就会收到一个正的反馈。
Policy P:如何选择动作的策略,我们希望能够学习到一个策略可以让 agent 得到最大的累积反馈。
一轮游戏可以被定义为一个马尔可夫决策过程 (MDPs), 反复在 state, action reward, state ... 之间转换直到游戏结束
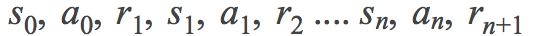
我们的目标是学会一个好的策略,我们在这儿使用discounted future reward R,discount rate为。在一个 state 例如
中,总计反馈可以这样计算:
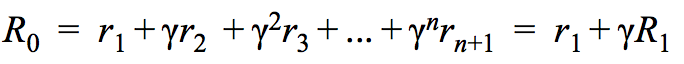
我们希望我们的车能够总是选择一个能得到最大反馈R的动作。如果我们知道每个动作相对应的R,那我们只要选择最大的那个就可以了,可事实是在每个状态中,每个动作所对应的R并不是容易得到的。
在Q Learning中,我们定义了一个Q函数 去表示在状态 s 中 采取动作 a 能够得到的最大R,在 Bell equation的帮助下,我们可以通过迭代的方法不停地更新Q值。
如果我们的Q函数足够准确,并且环境是确定的,我们只需要采取选择最大Q值动作的策略即可。
在传统的Q Learning中,Q值被储存在一个Q表格中,想象一个表格行为所有可能的 state 列为所有可能的 action。 这个方法可以很好的解决一些问题,尤其是 state 并不多,比如可以用几个量来表示的时候。但是在现实中,我们经常要用一些 raw image 来作为 state 的表示,一张10 × 10 像素 8 位的灰度图像就会有个不同 state, 我们不可能建立如此大的一个Q table,这也导致了Q Learning 很难被应用到现实问题中去.
- Deep Q Learning
那没法建立这么大的Q table 怎么办? 现在该是 Deep Q Learning登场的时候了。我们知道神经网络Neural Network可以很好对图片提取特征信息,进行抽象,分类等。那能否用Neural Network进行 Q 函数的模拟,让它去学习一副图片 state 所对应的 Q 值呢?
答案当然是可以的啊,不然我就不写了。XD
这个一个网络玩通 Atari 2600游戏,惊动Nature的方法就用Neural network 代替了Q table.
Human-level control through deep reinforcement learning
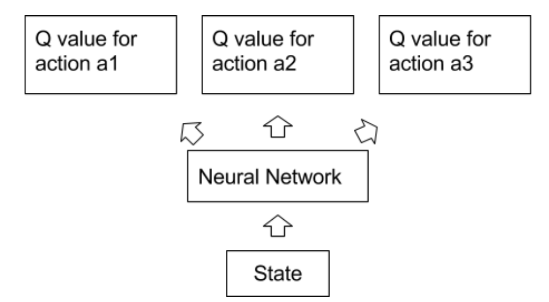
在用模拟器不停地模拟采取各种动作,收到各种反馈,再用 Bell equation 不停的训练 Q Network,并且得到一个能相对准确的估计Q值的网络以后。
我们只要在给定Q值的情况下选择相应的策略即可,比如贪心策略:
或者其他的广义上贪心策略,比如贪心策略或者 log概率搜索,去更好的探索整个问题,防止被困在一个局部最优中。
- Policy Gradient
Deep Q Learning的思维还是非常受Q Learning影响,基本的框架依然是Q Learning只是用神经网络去代替了Q Table,那还有一种更加 End to End的方法,叫做Policy Gradient。和 Deep Q Learning 用Q网络去估计Q 表然后在规定一种策略去依据Q值采取行动不同,Policy Gradient直的策略网络直接输出的就是策略,比如采取每一种行动的概率(对于离散控制问题),或者每一个动作的值(对于连续控制问题)。
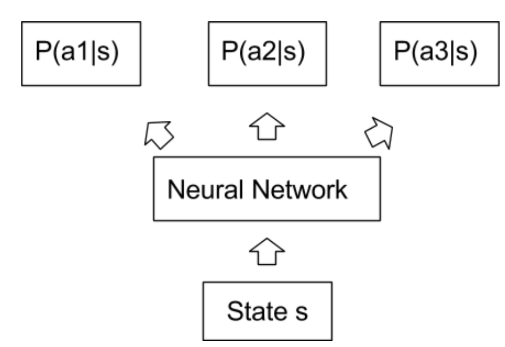 Policy Gradient 相对于 Deep Q Learning有两个主要优点,
Policy Gradient 相对于 Deep Q Learning有两个主要优点,
一来是这样更加的 End to End,不用借用强化学习的理论框架。
二来是这样既可以通过直接输出动作相应的连续量处理连续的控制量(比如对于汽车来说,油门的力度,刹车力度,转向角度),而用通过Q值选动作的方法则无法处理连续量。
在 Policy Gradient 中我们希望学会一个策略能够达到最大的期望回馈。用表示策略
表示策略网络的weights,通过学习不断更新。目标函数可以表示为
。David Silver在RL课程中为我们推导它对
的导数:
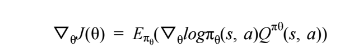 由此导数,我们可以把每轮的折扣回馈
由此导数,我们可以把每轮的折扣回馈看做该state真实价值
的无偏估计。利用Gradient ascent的方法去,
的 learning rate,不停地更新
训练一个能够达到最大期望回馈的策略网络。
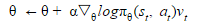
- Deep Deterministic Policy Gradient
Policy Gradient 听起来很美好是不是,但是呢,试试就发现,它基本没法学会任何东西啊!低配乞丐版的 Policy Gradient 理论上一切都好,但是实践中会有很多致命的问题让它很难收敛,例如:
1. 反馈分配,反馈在大多时候都是不存在的,比如赛车游戏,只有游戏结束,例如到达终点或者撞墙而亡的时候才收到反馈,那如何将反馈很好的和之前进行的一系列策略和动作联系到一起去是一个很大的问题。
2. 我们的算法有一个内在的假设,假设所有的抽样都是独立,并且处于相同分布的(independently and identically distributed, iid ), 但是实际上,在游戏进行的过程中,同一时间段前后的抽样是明显具有相关性的,这个iid假设并不成立,也就会影响到学习的效果。
3. 在我们通过获取反馈,折扣,然后TD来更新Q值的方法,或者直接估计策略的方法中,这些反馈信号都有非常多的噪声,这些噪声可能会让整个网络很难收敛,甚至很容易发散。
我在尝试的过程中也确实遇到了基本所有的这些问题,经常怎么训练都没法看到整个网络开始收敛,直到发现这个更加高级的方法DDPG:Continuous control with deep reinforcement learning
在这个方法中,除了有一个动作网络 Actor Network 用于直接估计动作之外,还有一个校正网络 Critic Network 用来估计Q值,其中 Actor Network 就像低配版 Policy Gradient中的 Policy Network,输入State,给出动作值 Actions。而 Critic Network 则在输入 State 的同时还输入由Actor Network 产生的 Actions,给出相应的 Q 值,并不断的用 bellman equation来进行更新。Actor Network 则是从Critic Network 对应 Actions 输入计算出的导数来进行更新。
用上面文章中的定义,动作方程 actor function 表示为, 校正方程 critic function 表示为
, Cost function J 对于
的导数为:
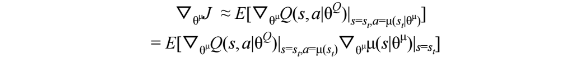 这个算法将对动作的Q值估计和策略估计给分离,让 agent 能够在探索更多的同时保持对一个确定策略的学习,让整个网络学习变得更容易。
这个算法将对动作的Q值估计和策略估计给分离,让 agent 能够在探索更多的同时保持对一个确定策略的学习,让整个网络学习变得更容易。
Replay Buffer:这是一个近乎于无限大的缓存,每次进行动作以后得到的 状态-动作-反馈- 新状态都会被保存到这个缓存中去,不同于之前的方法直接拿游戏进行过程中得到的
来进行训练,采用了Replay Buffer 以后,训练采用的 sample 则从这个缓存中随机抽样,通过这样的方法,理论上可以打破抽样直接的相关性,解决iid假设不成立的困扰
Target Network: 在训练过程中,由于环境是相对混沌的,用于更新Q网络的反馈具有很大的噪声,直接训练一个网络会非常容易让它发散而非收敛。因此,在DDPG的文章当中,有一种叫做目标网络Target Network的方法,创建Actor和Critic网络的副本和
来计算目标值,然后以
的比例缓慢的跟随原网络更新
。如此一来,目标值就会相对变得稳定许多,非常有利于学习的效果。
- 伪代码
讲了那么多昏昏欲睡的废话,现在直接贴上伪代码吧!
低配乞丐版 Policy Gradient
 高配 Deep Deterministic Policy Gradient
高配 Deep Deterministic Policy Gradient

- 训练结果
对于不同的游戏环境,训练结果也不尽相同,在经过一定时间的训练以后,一般都能看到初步的收敛,但是真正的收敛到一个接近最优的位置可能会需要好几天的训练时间。(基于Tensorflow,辣鸡GPU加速)
在寻找环境的过程中不得不提一下 OpenAI Gym.这个由 Elon Musk 赞助的非盈利性平台,提供了上百个游戏环境,搭建了一个训练General AI的平台,所有的游戏有统一的接口使用非常方便。
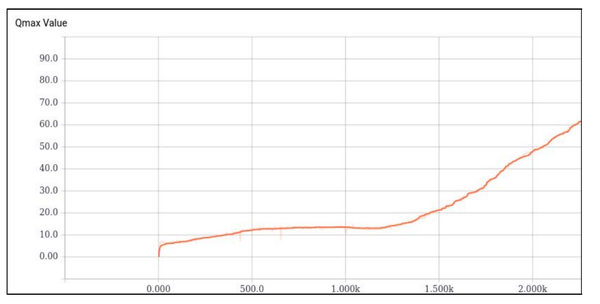
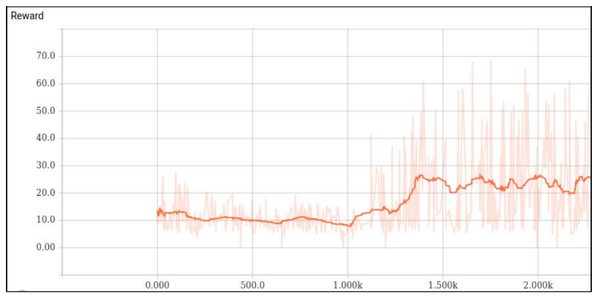
CartPole: 最简单的情况,这个控制木棍不倒下的问题应该是最经典的RL控制问题,由于相应的 State 和Action 维度很低因此也非常容易完成。我们使用了DDPG,在训练中记录了Q估计的最大值,代表了网络认为能够达到的最大收货。以及实际的 Reward,尽管非常嘈杂,但是依然可以明显的看到正在收敛。从游戏的视频来看,小木棍在后期确实非常稳定不容易倒下。
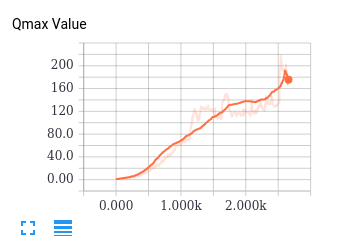
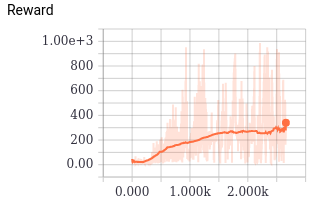
CarRacing: 相比于控制小木棍,这个控制小车的游戏相应的就困难很多,在这里并没有明确的抽象好了的state,需要直接接受画面作为state。目前这个游戏在OpenAI Gym中还没人完成(他们定义了达成一定的反馈才算做完成),经过长时间的调试和训练,我们让这个游戏的网络开始收敛,由于时间太长并且我们自己做了很多限制(比如每局最大步数)以加快训练速度,我们最终也没完成OpenAI Gym的要求,但是依然可以看到DDPG正在学到一些东西。有兴趣的朋友可以再研究研究。
- 阅读材料
这些材料包括一些网页和博客都对学习Deep Reinforcement Learning 非常有帮助! 祝大家RL的愉快!
[1] Andrej Karpathy. "Deep Reinforcement Learning: Pong from Pixels" http://karpathy.github.io/2016/05/31/rl/[2] Mnih, Volodymyr, et al. "Human-level control through deep reinforcement learning" Nature 518.7540 (2015)[3] Lever, Guy. "Deterministic policy gradient algorithms." (2014).[4] Patrick Emami. "Deep Deterministic Policy Gradients in TensorFlow" http://pemami4911.github.io/blog/2016/08/21/ddpg-rl.html#References[5] Tambet Matiisen: “Guest Post (Part I): Demystifying Deep Reinforcement Learning” : https://www.nervanasys.com/demystifying-deep-reinforcement-learning/[6] Lillicrap, Timothy P., et al. "Continuous control with deep reinforcement learning." arXiv preprint arXiv:1509.02971 (2015).[7] Heess, Nicolas, et al. "Learning continuous control policies by stochastic value gradients." Advances in Neural Information Processing Systems. 2015.[8] Mnih, Volodymyr, et al. "Asynchronous methods for deep reinforcement learning." arXiv preprint arXiv:1602.01783 (2016).[9] David Silver. Reinforcement learning Course: http://www0.cs.ucl.ac.uk/staff/D.Silver/web/Teaching.html[10] OpenAI Gym blog: https://gym.openai.com/docs/rl[11] Dulac-Arnold, Gabriel, et al. "Deep Reinforcement Learning in Large Discrete Action Spaces."[12] Mnih, Volodymyr, et al. "Asynchronous methods for deep reinforcement learning." arXiv preprint arXiv:1602.01783 (2016).[13] Yu, April, Raphael Palefsky-Smith, and Rishi Bedi. "Deep Reinforcement Learning for Simulated Autonomous Vehicle Control."给我老师的人工智能教程打call!http://blog.csdn.net/jiangjunshow
