Introduction
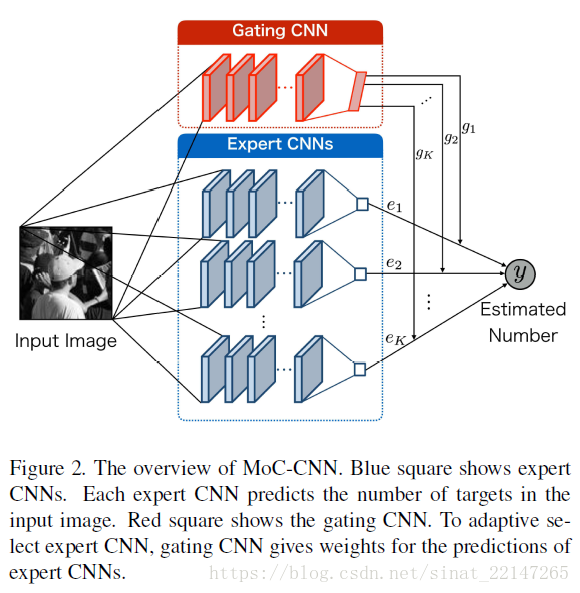
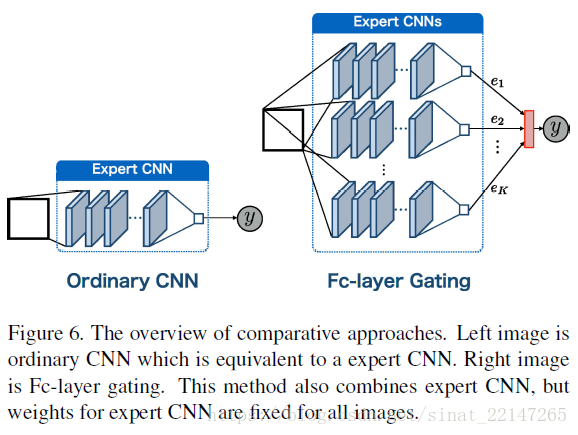
MoC-CNN由两类CNN组成:
(1)对应特定外观目标的CNN,也称为expert CNN;预测图像中的目标数目;
(2)根据目标的外观选择相应的expert CNN,称为gating CNN;预测expert CNN的概率,作为expert CNNs预测结果的整合权重依据;
最后,图像中的目标数目是expert CNNs的平均权值;
Related Works
Perspective map:解决透视扭曲简洁高效的一种方法;但是有两个缺点:(1)首先,如果拍摄地点改变了,我们必须手动重新设置透视地图的参数。(2)第二个缺点是,标准化对于只有相似大小的目标(例如人)是有效的。然而,当目标的大小改变时(例如,显微镜图像中的粒子和区域图像中的车辆),这种标准化是无效的。
Density map:用高斯分布取代点标注;优点是对图像边界的模糊目标具有鲁棒性;缺点是不考虑尺寸的改变
指出MCNN方法等也是使用了一个预测器,对外观变化不具有鲁棒性;
Proposed method
Counting by MoC-CNN:预测一张图片中的目标数目,如下公式;

training MoC-CNN:使用如下损失函数训练expert CNNs;

若gating CNN也使用上述损失函数进行训练,则无法训练到每个expert CNN,对于所有的图像将仅选择一个expert CNN;因此gating CNN使用下式作为损失函数:
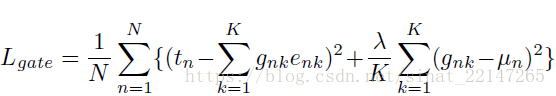
在expert CNNs和gating CNNs中输出层的更新如下:

The reason of specialization:

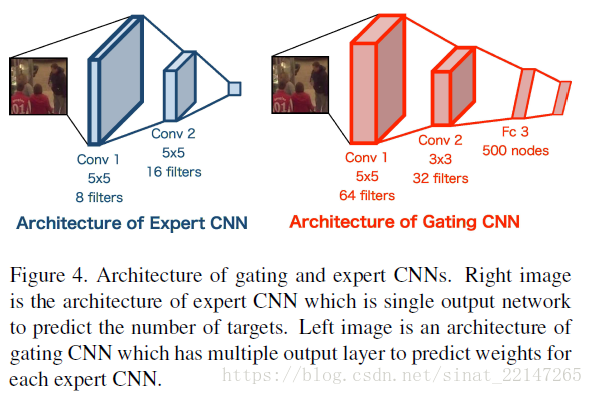
settings & Architecture of gating CNN详见论文P4
Ground Truth:使用密度图的加和;
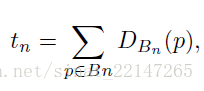
Evaluation
实验数据集:


下图是测试图片和gating CNN的输出,每张图片右侧的graph:x轴表示每个gating CNN,y轴表示gating CNN的输出;x轴数值越大,代表更少的人数以及更小的人群密度;

Conclusion
不足之处:该方法受到模糊训练数据的影响。因此,我们应该使用密度图来提高精确度。此外,我们可能会使用概念Hierarchical Mixture of Experts。它们是未来工作的主题。
Reference
论文【1】:R. A. Jacobs, M. I. Jordan, S. J. Nowlan, and G. E. Hinton. Adaptive mixtures of local experts. Neural computation, 3(1):79–87, 1991