CART决策树解决分类问题
scikit-learn中为我们封装了决策树分类器,详情可参见DecisionTreeClassifier
然后我们通过查询文档来看一下DecisionTreeClassifier这个方法所需要的常用参数:

1)criterion:传入所需特征选择的准则,gini为基尼指数,entropy为信息熵,默认“gini”
2)max_depth :决策树的最大高度,默认“None”,如果不设置,决策树会一直向下延伸直至条件终止,这样很可能导致过拟合
3)min_samples_split:分割节点的最小样本数,默认值为“2”。若给定类型为int,则表示节点最小样本数;若给定类型为float,则该值为百分比值,min_samples_split * n_samples的值为每次划分的最小样本数
4)min_samples_leaf:叶节点的最小样本数,默认值为“2”,对给定类型的定义同min_samples_split
5)random_state:随机种子,默认“None”
6)max_leaf_nodes:叶节点的最大数量,默认“None”
还是老规矩,使用iris数据集,为了方便可视化,只取petal length和petal width这两个特征,仍然使用sklearn自带的分割数据集的方法,将irisdata分为train set 和 test set,然后调用DecisionTreeClassifier方法,fit,最终打印准确率:
iris = datasets.load_iris()
X = iris.data[:, 2:]
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=666)
dec_tree = DecisionTreeClassifier()
dec_tree.fit(X_train, y_train)
print("test score:", dec_tree.score(X_test, y_test))
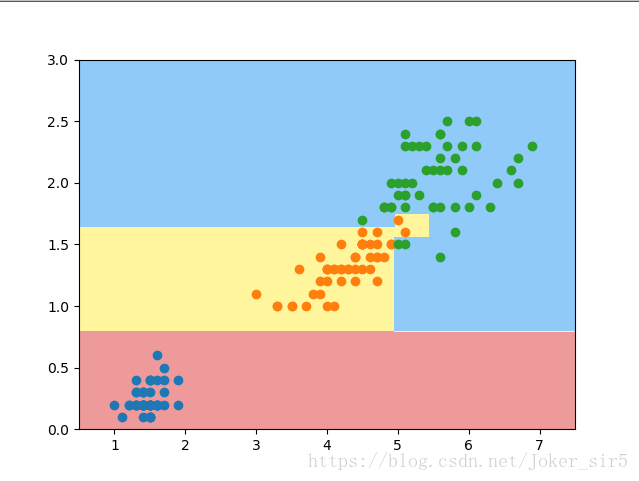
可以在可视化中看到,最终的准确率为1,效果还不错(此处其实已经出现了过拟合现象,但是由于数据的特殊性,过拟合所造成的问题还不是很严重),注意,我在代码里并未设置任何参数,即所有参数均为默认,接着我们试着设置一些参数来看看,最终会产生什么样的效果(我们设置max_depth=2):
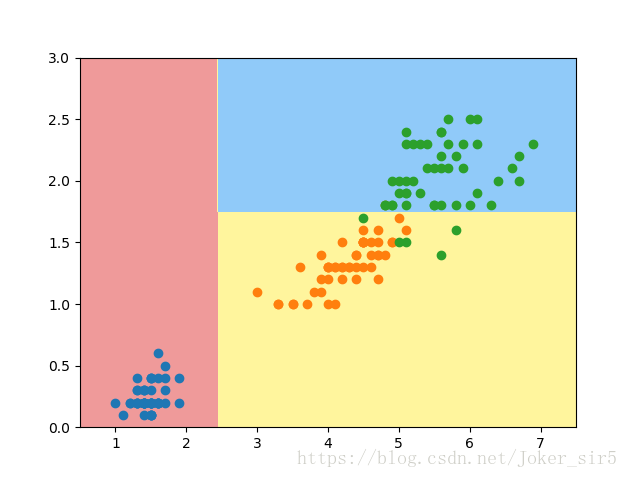
此时,我们可以看到,虽说在test set上准确率有所降低,从图中看这样分割似乎跟合理些,这也和上一篇博客 我们实现的决策树效果是一致的
我们再来看一个例子,这次我们使用sklearn中的一个很有趣的方法:make_moons,该方法可以为我们随机生成A simple toy dataset to visualize clustering and classification,当然我们这里用生成的散点解决分类问题,并最终返回生成的数据X(shape:(n_samples,2)),及对应的只有0和1的标签y(shape:(n_samples)),具体参数及用法可在文档中查询(如下图),我们这里直接用:

我这里为了展示决策树过拟合后果,将标准差=0.2的高斯噪声加到数据中
X, y = datasets.make_moons(noise=0.2, random_state=123)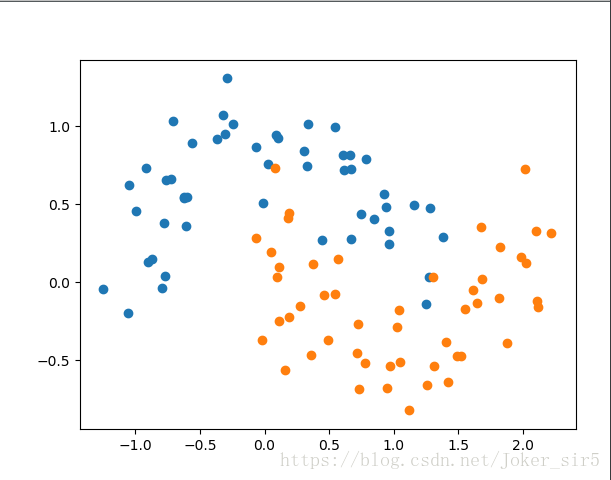
有了数据之后,我们调用DecisionTreeClassifier方法,看最终的结果:
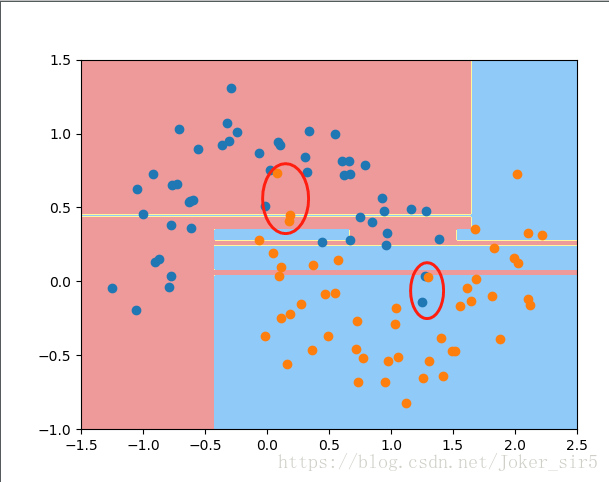
显然在未对DecisionTreeClassifier做任何约束的时候,造成了过拟合现象,使得分类器过分地考虑了一些不重要的点,从而使得分类器过于复杂,性能也随之降低,从test set准确率就可以看出:

那这个这个时候我们就要对刚才的决策树进行剪枝,如何剪枝呢?这就转到了调参的问题上,即合理地选择DecisionTreeClassifier的参数,就是在对过拟合的决策树进行剪枝,我们先来设置max_depth=2,来看效果:
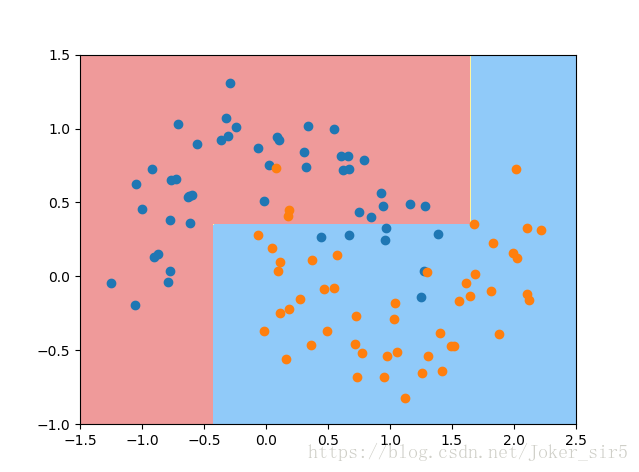
读者可以自行去调整其他参数的值,看看分类决策面会有什么变化,这里就不多展示了。通过不断地调整DecisionTreeClassifier的参数,将分类器调到最优,防止发生过拟合。
CART决策树解决回归问题
scikit-learn中为我们封装了决策树处理回归问题的方法—–DecisionTreeRegressor ,常用参数及用法和DecisionTreeClassifier类似,读者可参阅文档,这里主要进行调参工作,我们使用sklearn中封装的波士顿房价的数据集:
boston = datasets.load_boston()
X= boston.data
y = boston.target
dec_tree = DecisionTreeRegressor()
dec_tree.fit(X_train, y_train)最终结果显示:
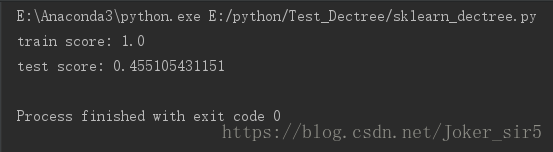
分类器在train set 中变现良好,准确率为1,但在test set中的准确率却只有0.45,为何会产生这样的现象,很明显,发生了过拟合,接下的工作就是要对决策树进行剪枝,即调参:
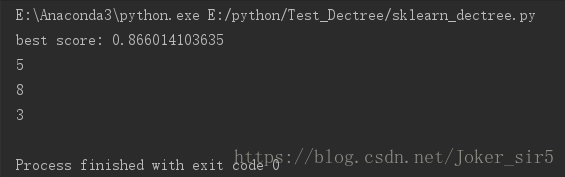
我这里通过网格搜索,测得max_depth=5, min_samples_split=8, min_samples_leaf=3时准确率最高,约有87%
总结
本篇博客我们利用sklearn实现了CART决策树,分别解决了分类问题和回归问题,并通过调参,对决策树进行剪枝,防止出现过拟合现象。上述回归问题的最终准确率约为87%,是我调参后的得到最大准确率,读者若亲身试验了代码(GitHub地址),并发现有更优的参数,或发现文中有表述错误之处,请在下方留言指出,不胜感激!