· Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow, 2nd Edition, by Aurélien Géron (O’Reilly). Copyright 2019 Aurélien Géron, 978-1-492-03264-9.
· 环境:Anaconda(Python 3.8) + Pycharm
· 学习时间:2022.05.04~2022.05.05
第六章 决策树
与SVM一样,决策树是通用的机器学习算法,可以执行分类和回归任务,甚至多输出任务。它们是功能强大的算法,能够拟合复杂的数据集。例如,在第2章中,你在加州房屋数据集中训练了DecisionTreeRegressor模型,使其完全拟合(实际上是过拟合)。
决策树也是随机森林的基本组成部分(见第7章),它们是当今最强大的机器学习算法之一。
在本章中,我们将从讨论如何使用决策树进行训练、可视化和做出预测开始。然后,我们将了解Scikit-Learn使用的CART训练算法,并将讨论如何对树进行正则化并将其用于回归任务。最后,我们将讨论决策树的一些局限性。
文章目录
6.1 训练和可视化决策树
为了理解决策树,让我们建立一个决策树,然后看看它是如何做出预测的。以下代码在鸢尾花数据集上训练了一个DecisionTreeClassifier:
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
iris = load_iris()
X = iris.data[:, 2:] # petal length and width
y = iris.target
tree_clf = DecisionTreeClassifier(max_depth=2)
tree_clf.fit(X, y)
要将决策树可视化,首先,使用export_graphviz()方法输出一个图形定义文件,命名为iris_tree.dot:
import os
from sklearn.tree import export_graphviz
export_graphviz(
tree_clf,
out_file=os.path.join("iris_tree.dot"),
feature_names=iris.feature_names[2:],
class_names=iris.target_names,
rounded=True,
filled=True
)
然后,你可以使用Graphviz软件包中的dot命令行工具将此.dot文件转换为多种格式,例如PDF或PNG。此命令行将.dot文件转换为.png图像文件:
$ dot -Tpng iris_tree.dot -o iris_tree.png
PyCharm安装一个.dot的插件就好了。
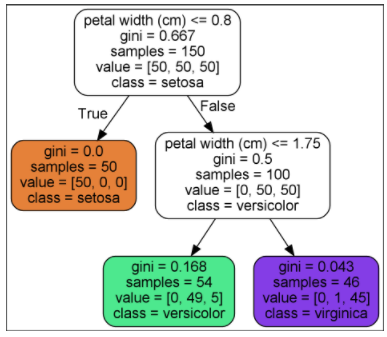
绘制如图:
6.2 做出预测
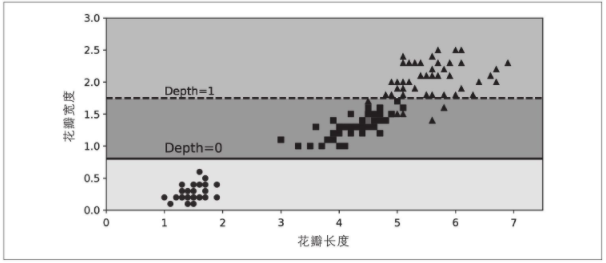
让我们看看上图中的树是如何进行预测的。假设你找到一朵鸢尾花,要对其进行分类。你从根节点开始(深度为0,在顶部):该节点询问花的花瓣长度是否小于2.45cm。如果是,则向下移动到根的左子节点(深度1,左)。在这种情况下,它是一片叶子节点(即它没有任何子节点),因此它不会提出任何问题:只需查看该节点的预测类,然后决策树就可以预测花朵是山鸢尾花(class=setosa)。
现在假设你发现了另一朵花,这次花瓣的长度大于2.45cm,你必须向下移动到根的右子节点(深度1,右),该子节点不是叶子节点,因此该节点会问另一个问题:花瓣宽度是否小于1.75cm?如果是,则你的花朵很可能是变色鸢尾花(深度2,左)。如果不是,则可能是维吉尼亚鸢尾花(深度2,右)。就是这么简单。
决策树的许多特质之一就是它们几乎不需要数据准备。实际上,它们根本不需要特征缩放或居中。
节点的samples属性统计它应用的训练实例数量。例如,有100个训练实例的花瓣长度大于2.45cm(深度1,右),其中54个花瓣宽度小于1.75cm(深度2,左)。
节点的value属性说明了该节点上每个类别的训练实例数量。例如,右下节点应用在0个山鸢尾、1个变色鸢尾和45个维吉尼亚鸢尾实例上。
最后,节点的gini属性衡量其不纯度(impurity):如果应用的所有训练实例都属于同一个类别,那么节点就是“纯”的(gini=0)。例如,深度1左侧节点仅应用于山鸢尾花训练实例,所以它就是纯的,并且gini值为0。公式6-1说明了第i个节点的基尼系数Gi的计算方式。例如,深度2左侧节点,基尼系数等于 1 – ( 0 / 54 ) 2 – ( 49 / 54 ) 2 – ( 5 / 54 ) 2 ≈ 0.168 1–(0/54)^2–(49/54)^2–(5/54)^2≈0.168 1–(0/54)2–(49/54)2–(5/54)2≈0.168。(基尼不纯度: G i = 1 − ∑ k = 1 n p i , k 2 G_i = 1-\sum^n_{k=1}p_{i,k}^2 Gi=1−∑k=1npi,k2, p i , k pi, k pi,k是第 i i i个节点中训练实例之间的 k k k类实例的比率)
Scikit-Learn使用的是CART算法,该算法仅生成二叉树:非叶节点永远只有两个子节点(即问题答案仅有是或否)。但是,其他算法(比如ID3生成的决策树),其节点可以拥有两个以上的子节点。
模型解释:白盒子与黑盒子
决策树是直观的,其决策也易于解释。这种模型通常称为白盒模型。相反,正如我们将看到的,通常将随机森林或神经网络视为黑盒模型。它们做出了很好的预测,你可以轻松地检查它们为做出这些预测而执行的计算。但是,通常很难用简单的话语来解释为什么做出这样的预测。例如,如果神经网络说某个人出现在图片上,那么很难知道是什么因素促成了这一预测:该模型识别该人的眼睛、嘴、鼻子、鞋子,甚至他们坐的沙发?相反,决策树提供了很好的、简单的分类规则,如果需要的话,甚至可以手动应用这些规则(例如,用于花的分类)。
6.3 估计类概率
决策树同样可以估算某个实例属于特定类k的概率:首先,跟随决策树找到该实例的叶节点,然后返回该节点中类k的训练实例占比。例如,假设你发现一朵花,其花瓣长5cm,宽1.5cm。相应的叶节点为深度2左侧节点,因此决策树输出如下概率:山鸢尾花,0%(0/54);变色鸢尾花,90.7%(49/54);维吉尼亚鸢尾花,9.3%(5/54)。当然,如果你要求它预测类,那么它应该输出变色鸢尾花(类别1),因为它的概率最高。我们试一下:
tree_clf.predict_proba([[5, 1.5]])
# 输出:array([[0. , 0.90740741, 0.09259259]])
tree_clf.predict([[5, 1.5]])
# 输出:array([1])
完美!注意,在图6-2的右下角矩形中,任意点的估计概率都是相同的,例如,如果花瓣长6cm,宽1.5cm(即使看起来很可能是维吉尼亚鸢尾花)。
6.4 CART训练算法
Scikit-Learn使用分类和回归树(Classification and Regression Tree,CART)算法来训练决策树(也称为“增长树”)。该算法的工作原理是:首先使用单个特征k和阈值tk(例如,“花瓣长度”≤2.45cm”)将训练集分为两个子集。如何选择 k k k和 t k t_k tk?它搜索产生最纯子集(按其大小加权)的一对( k k k和 t k t_k tk)。
下面的公式给出了算法试图最小化的成本函数( G l e f t / r i g h t G_{left/right} Gleft/right测量左右子集的不纯度, m l e f t / r i g h t m_{left/right} mleft/right测量左右子集的实例数)。
J ( k , t k ) = m l e f t m G l e f t + m r i g h t m G r i g h t J(k,t_k) = \frac{m_{left}}{m}G_{left} + \frac{m_{right}}{m}G_{right} J(k,tk)=mmleftGleft+mmrightGright
一旦CART算法成功地将训练集分为两部分,它就会使用相同的逻辑将子集进行分割,然后再分割子集,以此类推。一旦达到最大深度(由超参数max_depth定义),或者找不到可减少不纯度的分割,它将停止递归。其他一些超参数(稍后描述)可以控制其他一些停止条件(min_samples_split、min_samples_leaf、min_weight_fraction_leaf和max_leaf_nodes)。
如你所见,CART是一种贪婪算法:从顶层开始搜索最优分裂,然后每层重复这个过程。几层分裂之后,它并不会检视这个分裂的不纯度是否为可能的最低值。贪婪算法通常会产生一个相当不错的解,但是不能保证是最优解。
而不幸的是,寻找最优树是一个已知的NP完全问题(NP-C问题):需要的时间是 O ( e x p ( m ) ) O(exp(m)) O(exp(m)),所以即使是很小的训练集,也相当棘手。这就是为什么我们必须接受一个“相当不错”的解。
NP就是Non-deterministic Polynomial的问题,也即是多项式复杂程度的非确定性问题。而如果任何一个NP问题都能通过一个多项式时间算法转换为某个NP问题,那么这个NP问题就称为NP完全问题(Non-deterministic Polynomial complete problem)。NP完全问题也叫做NPC问题。是世界七大数学难题之一(千僖难题),被看作逻辑和计算机科学中最突出的问题之一。。
6.5 计算复杂度
进行预测需要从根到叶遍历决策树。决策树通常是近似平衡的,因此遍历决策树需要经过大约 O ( l o g 2 m ) O(log_2^m) O(log2m)个节点(注: l o g 2 log^2 log2是二进制对数。它等于 l o g 2 m = l o g m / l o g 2 log_2^m=log^m/log^2 log2m=logm/log2)。由于每个节点仅需要检查一个特征值,因此总体预测复杂度为 O ( l o g 2 m ) O(log_2^m) O(log2m)。与特征数量无关。因此,即使处理大训练集,预测也非常快。
训练算法比较每个节点上所有样本上的所有特征(如果设置了max_features,则更少)。比较每个节点上所有样本的所有特征会导致训练复杂度为 O ( n × m l o g 2 m ) O(n×m log_2^m) O(n×mlog2m)。对于小训练集(少于几千个实例),Scikit-Learn可以通过对数据进行预排序(设置presort=True)来加快训练速度,但是这样做会大大降低大训练集的训练速度。
6.6 基尼不纯度或熵
默认使用的是基尼不纯度来进行测量,但是,你可以将超参数criterion设置为"entropy"来选择熵作为不纯度的测量方式。熵的概念源于热力学,是一种分子混乱程度的度量:如果分子保持静止和良序,则熵接近于零。后来这个概念推广到各个领域,其中包括香农的信息理论,它衡量的是一条信息的平均信息内容[1]:如果所有的信息都相同,则熵为零。在机器学习中,它也经常被用作一种不纯度的测量方式:如果数据集中仅包含一个类别的实例,其熵为零。
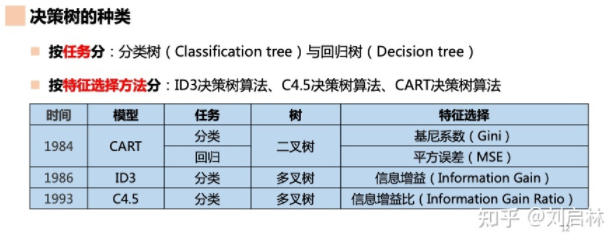
决策树的种类及其实现:
基于Sklearn实现的各种决策树的代码如下:
from sklearn.tree import DecisionTreeClassifier dtree = DecisionTreeClassifier() # CART分类树(criterion=”gini”, CART, 分类与回归树) dtree = DecisionTreeClassifier(criterion='entropy') # ID3分类树(Iterative Dichotomiser 3) # C4.5将训练树(即id3算法的输出)转换为 if-then 规则集。然后评估每个规则的这些准确性,以确定应用它们的顺序。剪枝是通过删除规则的前提条件来完成的,如果没有这个前提条件规则的准确性会有所提高。
那么到底应该使用基尼不纯度还是熵呢?其实,大多数情况下,它们并没有什么大的不同,产生的树都很相似。基尼不纯度的计算速度略微快一些,所以它是个不错的默认选择。它们的不同在于,基尼不纯度倾向于从树枝中分裂出最常见的类别,而熵则倾向于生产更平衡的树。
【ileanu and Stoffel,见周志华《机器学习》第11章. 2004】对信息增益和基尼指数进行的理论分析也显示出、它们仅在2%情况下会有所不同。
6.7 正则化超参数
决策树极少对训练数据做出假设(比如线性模型就正好相反,它显然假设数据是线性的)。如果不加以限制,树的结构将跟随训练集变化,严密拟合,并且很可能过拟合。这种模型通常被称为非参数模型,这不是说它不包含任何参数(事实上它通常有很多参数),而是指在训练之前没有确定参数的数量,导致模型结构自由而紧密地贴近数据。相反,参数模型(比如线性模型)则有预先设定好的一部分参数,因此其自由度受限,从而降低了过拟合的风险(但是增加了欠拟合的风险)。
为避免过拟合,需要在训练过程中降低决策树的自由度。现在你应该知道,这个过程被称为正则化。正则化超参数的选择取决于使用的模型,但是通常来说,至少可以限制决策树的最大深度。在Scikit-Learn中,这由超参数max_depth控制(默认值为None,意味着无限制)。减小max_depth可使模型正则化,从而降低过拟合的风险。
⭐DecisionTreeClassifier类还有一些其他的参数,同样可以限制决策树的形状:min_samples_split(分裂前节点必须有的最小样本数)、min_samples_leaf(叶节点必须有的最小样本数量)、min_weight_fraction_leaf(与min_samples_leaf一样,但表现为加权实例总数的占比)、max_leaf_nodes(最大叶节点数量),以及max_features(分裂每个节点评估的最大特征数量)。增大超参数min_*或减小max_*将使模型正则化。
还可以先不加约束地训练模型,然后再对不必要的节点进行剪枝(删除)。如果一个节点的子节点全部为叶节点,则该节点可被认为不必要,除非它所表示的纯度提升有重要的统计意义。标准统计测试(比如χ2测试)用来估算“提升纯粹是出于偶然”(被称为零假设)的概率。如果这个概率(称之为p值)高于一个给定阈值(通常是5%,由超参数控制),那么这个节点可被认为不必要,其子节点可被删除。直到所有不必要的节点都被删除,剪枝过程结束。
决策树剪枝的基本策略有"预剪枝"(prepruning)和"后剪枝"(post-pruning)【Quinlan,1993】。预剪枝是指在决策树生成过程中,对每个结点在划分前先进行估计,若当前结点的划分不能带来决策树泛化性能提升,则停止划分并将当前结点标记为叶结点;后剪枝则是先从训练集生成一棵完整的决策树,然后自底向上地对非叶结点进行考察,若将该结点对应的子树替换为叶结点能带来决策树泛化性能提升,则将该子树替换为叶结点。
般情形下,后剪枝决策树的欠拟合风险很小,泛化性能往往优于预剪枝决策树、但后剪枝过程是在生成完全决策树之后进行的,并且要自底向上地对树中的所有非叶结点进行逐一考察、因此其训练时间开销比未剪枝决策树和预剪枝决策树都要大得多。
6.8 回归
决策树还能够执行回归任务。让我们使用Scikit-Learn的DecisionTreeRegressor类构建一个回归树,并用max_depth=2在一个有噪声的二次数据集上对其进行训练:
from sklearn.tree import DecisionTreeRegressor
tree_reg = DecisionTreeRegressor(max_depth=2)
tree_reg.fit(X, y)
生成的树如图所示:
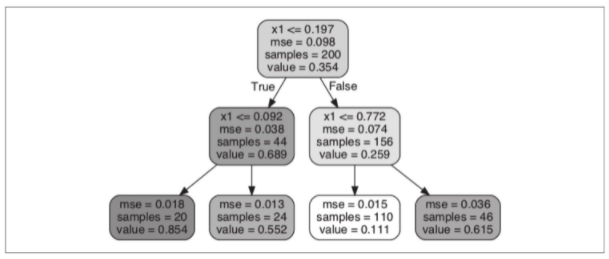
这棵树看起来与之前建立的分类树很相似。主要差别在于,每个节点上不再预测一个类别而是预测一个值。例如,如果你想要对一个x1=0.6的新实例进行预测,那么从根节点开始遍历,最后到达预测value=0.111的叶节点。这个预测结果其实就是与这个叶节点关联的110个实例的平均目标值。在这110个实例上,预测产生的均方误差(MSE)等于0.015。
下图的左侧显示了该模型的预测。如果设置max_depth=3,将得到如下图右侧所示的预测。注意看,每个区域的预测值永远等于该区域内实例的目标平均值。算法分裂每个区域的方法就是使最多的训练实例尽可能接近这个预测值。
CART算法的工作原理与以前的方法大致相同,不同之处在于,它不再尝试以最小化不纯度的方式来拆分训练集,而是以最小化MSE的方式来拆分训练集。
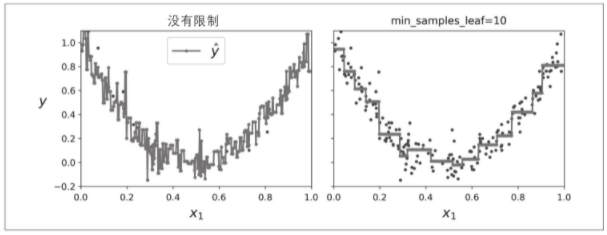
就像分类任务一样,决策树在处理回归任务时容易过拟合。如果不进行任何正则化(如使用默认的超参数),你会得到下图左侧的预测。这些预测显然非常过拟合训练集。只需设置min_samples_leaf=10就可以得到一个更合理的模型,如下图右侧所示。
6.9 不稳定性
希望到目前为止,你已经确信决策树有很多用处:它们易于理解和解释、易于使用、用途广泛且功能强大。但是,它们确实有一些局限性。首先,你可能已经注意到,决策树喜欢正交的决策边界(所有分割都垂直于轴),这使它们对训练集旋转敏感。例如,下图显示了一个简单的线性可分离数据集:在左侧,决策树可以轻松地对其进行拆分,而在右侧,将数据集旋转45度后,决策边界看起来复杂了(没有必要)。尽管两个决策树都非常拟合训练集,但右侧的模型可能无法很好地泛化。限制此问题的一种方法是使用主成分分析(见第8章),这通常会使训练数据的方向更好。
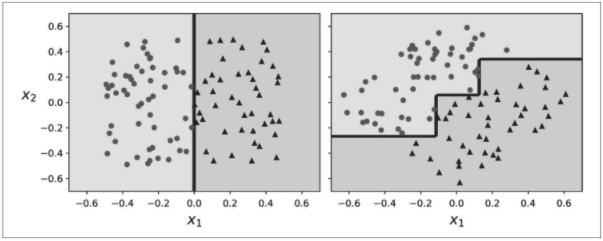
更概括地说,决策树的主要问题是它们对训练数据中的小变化非常敏感。例如,如果你从鸢尾花数据集中移除花瓣最宽的变色鸢尾花(花瓣长4.8cm,宽1.8cm),然后重新训练一个决策树,你可能得到如下图所示的模型。这跟之前图6-2的决策树看起来截然不同。事实上,由于Scikit-Learn所使用的算法是随机的,即使是在相同的训练数据上,你也可能得到完全不同的模型(除非你对超参数random_state进行设置)。
随机森林可以通过对许多树进行平均预测来限制这种不稳定性,正如我们将在第7章中看到的那样。
6.10 练习题
问题
-
如果训练集有100万个实例,训练决策树(无约束)大致的深度是多少?
-
通常来说,子节点的基尼不纯度是高于还是低于其父节点?是通常更高/更低?还是永远更高/更低?
-
如果决策树过拟合训练集,减少max_depth是否为一个好主意?
-
如果决策树对训练集欠拟合,尝试缩放输入特征是否为一个好主意?
-
如果在包含100万个实例的训练集上训练决策树需要一个小时,那么在包含1000万个实例的训练集上训练决策树,大概需要多长时间?
-
如果训练集包含10万个实例,设置presort=True可以加快训练吗?
-
为卫星数据集训练并微调一个决策树。
- a. 使用make_moons(n_samples=10000,noise=0.4)生成一个卫星数据集。
- b.使用train_test_split()拆分训练集和测试集。
- c.使用交叉验证的网格搜索(在GridSearchCV的帮助下)为DecisionTreeClassifier找到适合的超参数。提示:尝试max_leaf_nodes的多种值。
- d.使用超参数对整个训练集进行训练,并测量模型在测试集上的性能。你应该得到约85%~87%的准确率。
-
按照以下步骤种植森林。
- a.继续之前的练习,生产1000个训练集子集,每个子集包含随机挑选的100个实例。提示:使用Scikit-Learn的ShuffleSplit来实现。
- b.使用前面得到的最佳超参数值,在每个子集上训练一个决策树。在测试集上评估这1000个决策树。因为训练集更小,所以这些决策树的表现可能比第一个决策树要差一些,只能达到约80%的准确率。
- c.见证奇迹的时刻到了。对于每个测试集实例,生成1000个决策树的预测,然后仅保留次数最频繁的预测(可以使用SciPy的mode()函数)。这样你在测试集上可获得大多数投票的预测结果。
- d.评估测试集上的这些预测,你得到的准确率应该比第一个模型更高(高出0.5%~1.5%)。恭喜,你已经训练出了一个随机森林分类器!
答案
-
一个包含m个叶节点的均衡二叉树的深度等于log2(m)(注:log2是基2对数,log2(m)=log(m)/log(2)。),取整。通常来说,二元决策树(只做二元决策的树,就像Scikit-Learn中的所有树一样)训练到最后大体都是平衡的,如果不加以限制,最后平均每个叶节点一个实例。因此,如果训练集包含100万个实例,那么决策树的深度为log2(106)≈20层(实际上会更多一些,因为决策树通常不可能完美平衡)。
-
一个节点的基尼不纯度通常比其父节点低。这是由于CART训练算法的成本函数。该算法分裂每个节点的方法,就是使其子节点的基尼不纯度的加权之和最小。但是,如果一个子节点的不纯度远小于另一个,那么也有可能使子节点的基尼不纯度比其父节点高,只要那个不纯度更低的子节点能够抵偿这个增加即可。举例来说,假设一个节点包含4个A类的实例和1个B类的实例,其基尼不纯度等于
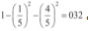
。现在我们假设数据集是一维的,并且实例的排列顺序如下:A,B,A,A,A。你可以验证算法将在第二个实例后拆分该节点,从而生成两个子节点,分别包含的实例为A,B和A,A,A。第一个子节点的基尼不纯度为1-(1/2)2-(1/2)2=0.5,比其父节点要高。这是因为第二个子节点是纯的,所以总的加权基尼不纯度等于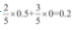
,低于父节点的基尼不纯度。 -
如果决策树过拟合训练集,降低max_depth可能是一个好主意,因为这会限制模型,使其正则化。
-
决策树的优点之一就是它们不关心训练数据是缩放还是集中,所以如果决策树不适合训练集,缩放输入特征不过是浪费时间罢了。
-
决策树的训练复杂度为O(n×mlog(m))。所以,如果将训练集大小乘以10,训练时间将乘以K=(n×10m×log(10m))/(n×m×log(m))=10×log(10m)/log(m)。如果m=106,那么K≈11.7,所以训练1000万个实例大约需要11.7小时。
-
只有当数据集小于数千个实例时,预处理训练集才可以加速训练。如果包含100 000个实例,设置presort=True会显著减慢训练。
对于练习7和练习8的解答,参见Jupyter notebooks:https://github.com/ageron/handson-ml2的Jupyter notebook。