版权声明:本文为博主原创学习笔记,如需转载请注明来源。 https://blog.csdn.net/SHU15121856/article/details/84344295
学习《scikit-learn机器学习》时的一些实践。
决策树拟合泰坦尼克号数据集
这里用绘制参数-score曲线的方式去直观看出模型参数对模型得分的影响,作者使用了GridSearchCV来自动做k-fold交叉验证,并且能在多组模型参数中找到最优的一组和最优值(用平均score来评估)。
这种方式可以避免一次随机划分造成的不确定性太大,得到的曲线很不稳定。
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
import numpy as np
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import GridSearchCV
# 使matplotlib正常显示负号
plt.rcParams['axes.unicode_minus'] = False
BASE_DIR = "E:/WorkSpace/ReadingNotes/scikit-learn机器学习/data/"
'''
泰坦尼克号数据集: https://www.kaggle.com/c/titanic/data
'''
# 读取泰坦尼克号数据,并做一定的预处理
def read_dataset(file):
# index_col指定作为行索引的列,这里第一列是PassengerId
df = pd.read_csv(file, index_col=0)
# 丢弃无用的特征(指定axis=1即列),inplace=True则在df对象上操作,而不是返回操作后的df
df.drop(["Name", "Ticket", "Cabin"], axis=1, inplace=True)
# 将性别转换为男1女0:先转换为True/False序列再进行类型转换
df['Sex'] = (df['Sex'] == 'male').astype('int')
# 将登船港口数据转化为数值型数据,先获得其中的所有可能取值放在列表中,再直接取其在列表中的下标即可
embarked_unique = df['Embarked'].unique().tolist()
df['Embarked'] = df['Embarked'].apply(lambda x: embarked_unique.index(x))
# 缺失数据(NaN)设置为0
df = df.fillna(0)
return df
# 计算决策树模型在指定参数下训练集和验证集上的得分
def get_score(X, y, **kwargs):
clf = DecisionTreeClassifier(**kwargs)
clf.fit(X, y)
train_score = clf.score(X_train, y_train)
cv_score = clf.score(X_cv, y_cv)
return (train_score, cv_score)
# 寻找模型中参数的较优值,这里寻找max_depth(决策树前剪枝:最大深度)
def find_max_depth():
global X_train, y_train
depths = range(2, 15)
scores = [get_score(X_train, y_train, max_depth=d) for d in depths]
train_scores, cv_scores = [s[0] for s in scores], [s[1] for s in scores]
# 找出cv_scores中数值最大的数字的下标,交叉验证集中评分最高的对应的索引,这和depths中的索引相对应
best_cv_score_index = np.argmax(cv_scores)
# 从而找到最好的参数值和对应的验证集评分
print("最好的参数值:{},对应的验证集评分:{}".format(depths[best_cv_score_index], cv_scores[best_cv_score_index]))
# 绘制得分随参数值变化的曲线
plt.figure(figsize=(6, 4), dpi=144)
plt.grid()
plt.xlabel("决策树的max_depth参数")
plt.ylabel("score")
plt.plot(depths, train_scores, '.r--', label="训练集得分")
plt.plot(depths, cv_scores, '.b--', label="验证集得分")
plt.legend()
plt.show()
# 寻找min_impurity_decrease(决策树前剪枝:信息熵或基尼不纯度的阈值)
def find_min_impurity_decrease():
global X_train, y_train
values = np.linspace(0, 0.5, 50)
# 这里criterion='gini'指定用基尼不纯度作为衡量信息不确定性的指标,即是CART
scores = [get_score(X_train, y_train, criterion='gini', min_impurity_decrease=d) for d in values]
train_scores, cv_scores = [s[0] for s in scores], [s[1] for s in scores]
# 找出cv_scores中数值最大的数字的下标,交叉验证集中评分最高的对应的索引,这和depths中的索引相对应
best_cv_score_index = np.argmax(cv_scores)
# 从而找到最好的参数值和对应的验证集评分
print("最好的参数值:{},对应的验证集评分:{}".format(values[best_cv_score_index], cv_scores[best_cv_score_index]))
# 绘制得分随参数值变化的曲线
plt.figure(figsize=(6, 4), dpi=144)
plt.grid()
plt.xlabel("决策树的min_impurity_decrease参数")
plt.ylabel("score")
plt.plot(values, train_scores, '.r--', label="训练集得分")
plt.plot(values, cv_scores, '.b--', label="验证集得分")
plt.legend()
plt.show()
# clf.cv_results保存了计算过程的所有中间结果,用它来绘制score随参数变化图
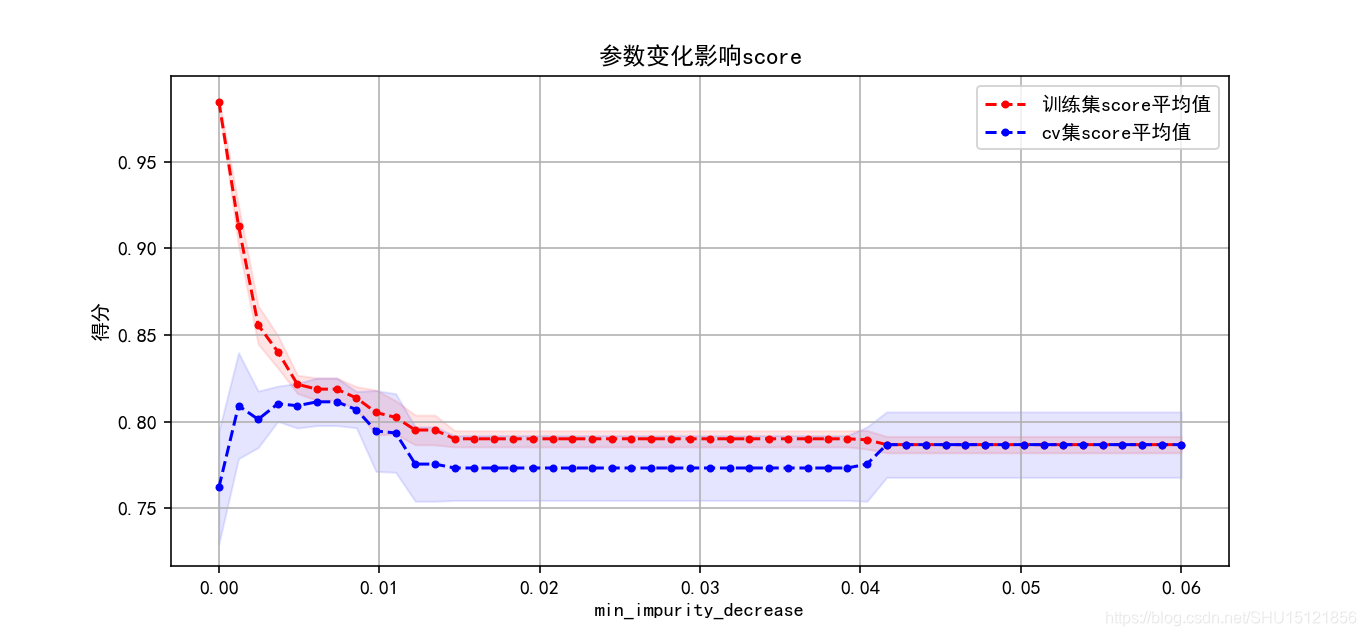
def plot_curve(xs, cv_results, xlabel):
train_score_mean = cv_results['mean_train_score']
train_score_std = cv_results['std_train_score']
test_score_mean = cv_results['mean_test_score']
test_score_std = cv_results['std_test_score']
plt.figure(figsize=(6, 4), dpi=144)
plt.title("参数变化影响score")
plt.grid()
plt.xlabel(xlabel)
plt.ylabel("得分")
plt.fill_between(xs, train_score_mean - train_score_std, train_score_mean + train_score_std, alpha=0.1, color='r')
plt.fill_between(xs, test_score_mean - test_score_std, test_score_mean + test_score_std, alpha=0.1, color='b')
plt.plot(xs, train_score_mean, '.--', color='r', label='训练集score平均值')
plt.plot(xs, test_score_mean, '.--', color='b', label='cv集score平均值')
plt.legend(loc='best')
plt.show()
# 在多组参数中选择最优的参数
def find_in_mix():
global X, y
entropy_thhs = np.linspace(0, 1, 50)
gini_thhs = np.linspace(0, 0.5, 50)
# 参数表
param_grid = [
{'criterion': ['entropy'], 'min_impurity_decrease': entropy_thhs, 'max_depth': range(2, 10),
'min_samples_split': range(2, 30, 2)},
{'criterion': ['gini'], 'min_impurity_decrease': gini_thhs, 'max_depth': range(2, 10),
'min_samples_split': range(2, 30, 2)}
]
# 将对参数表中每个字典中的多组参数进行组合,找到最优的一组
clf = GridSearchCV(DecisionTreeClassifier(), param_grid, cv=5)
clf.fit(X, y)
print("最佳参数和参数值:{}\n最佳得分:{}".format(clf.best_params_, clf.best_score_))
if __name__ == '__main__':
with open(BASE_DIR + "z7/train.csv") as f:
df = read_dataset(f)
# 标签即"是否存活"一列
y = df['Survived'].values
# 特征里要去掉标签这一列
X = df.drop(['Survived'], axis=1).values
# 划分训练集和验证集
X_train, X_cv, y_train, y_cv = train_test_split(X, y, test_size=0.2)
'''
# 决策树训练和评估
train_score, cv_score = get_score(X_train, y_train)
print("训练集得分:{},验证集得分:{}".format(train_score, cv_score))
# 寻找两个预剪枝参数的较优值,这种方式多次运行不稳定,因为太随机了,可以用后面的GridSearchCV做交叉验证取平均
find_max_depth()
find_min_impurity_decrease()
'''
thresholds = np.linspace(0, 0.06, 50) # 在观察图像后调整范围
# 参数表
param_grid = {'min_impurity_decrease': thresholds}
# 枚举参数表中的所有值来构建模型,cv折交叉验证,最终得到指定参数值的平均评分和标准差等
# 注意,这里指定了return_train_score=True才能用后面的clf.v_results_等
clf = GridSearchCV(DecisionTreeClassifier(), param_grid, cv=5, return_train_score=True)
clf.fit(X, y)
print("最佳参数和参数值:{}\n最佳得分:{}".format(clf.best_params_, clf.best_score_))
plot_curve(thresholds, clf.cv_results_, "min_impurity_decrease")
# 测试下多组混合
print('-' * 20 + '多组混合' + '-' * 20)
find_in_mix()
运行结果:
最佳参数和参数值:{'min_impurity_decrease': 0.006122448979591836}
最佳得分:0.8114478114478114
--------------------多组混合--------------------
最佳参数和参数值:{'criterion': 'entropy', 'max_depth': 8, 'min_impurity_decrease': 0.0, 'min_samples_split': 22}
最佳得分:0.819304152637486
第一次提交Kaggle
在Kaggle上可以看到有三个csv文件,除了训练集和测试集(不带标签)之外,还有一个就是提交的样本。提交的时候是提交一个和提交样本格式一样的csv,服务器会根据提交的结果和测试集实际的标签进行对比,这个问题里是用ACC来评分的。
前面得到了最佳(其实是在给定的参数内使得cv集的平均score最高)的参数,用它来对整个样本集拟合,然后生成模型,对测试集进行预测,然后变成指定格式的csv文件提交即可。
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
import numpy as np
BASE_DIR = "E:/WorkSpace/ReadingNotes/scikit-learn机器学习/data/"
# 读取泰坦尼克号数据,并做一定的预处理
def read_dataset(file):
# index_col指定作为行索引的列,这里第一列是PassengerId
df = pd.read_csv(file, index_col=0)
# 丢弃无用的特征(指定axis=1即列),inplace=True则在df对象上操作,而不是返回操作后的df
df.drop(["Name", "Ticket", "Cabin"], axis=1, inplace=True)
# 将性别转换为男1女0:先转换为True/False序列再进行类型转换
df['Sex'] = (df['Sex'] == 'male').astype('int')
# 将登船港口数据转化为数值型数据,先获得其中的所有可能取值放在列表中,再直接取其在列表中的下标即可
embarked_unique = df['Embarked'].unique().tolist()
df['Embarked'] = df['Embarked'].apply(lambda x: embarked_unique.index(x))
# 缺失数据(NaN)设置为0
df = df.fillna(0)
return df
if __name__ == '__main__':
with open(BASE_DIR + "z7/train.csv") as f:
df = read_dataset(f)
# 标签即"是否存活"一列
y = df['Survived'].values
# 特征里要去掉标签这一列
X = df.drop(['Survived'], axis=1).values
clf = DecisionTreeClassifier(criterion='entropy', max_depth=8, min_impurity_decrease=0.0, min_samples_split=22)
clf.fit(X, y)
print(clf.score(X, y))
# 读入测试集并做预测,然后保存结果
with open(BASE_DIR + "z7/test.csv") as f2:
test_df = read_dataset(f2)
predictions = clf.predict(test_df.values)
# 转换成要求的格式
result = pd.DataFrame({'PassengerId': test_df.index, 'Survived': predictions.astype(np.int32)})
# print(result)
result.to_csv("./titanic.csv", index=False)