KNeighborsClassifier
前两篇博客动手实现简单的KNN(python)、KNN优化之参数设置,我们自己动手编写了KNN分类器,产生了不错的效果,丰衣足食。这篇博客我们来整理下,如何使用scikit-learn中封装好的KNeighborsClassifier,仍然使用iris和digits数据集,直接上代码(读者若想了解更多scikit-learn中封装的KNN方法,请戳这里),老规矩还是以iris为例,digits同理:
# 导入鸢尾花数据集
iris = datasets.load_iris()
X = iris.data
y = iris.target
# 使用sklearn封装的分割方法将我们的数据集分成train set和test set
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1)
# 使用KNeighborsClassifier,传入参数k,fit
sk_knn = KNeighborsClassifier(n_neighbors=4)
sk_knn.fit(X_train, y_train)
score = sk_knn.score(X_test, y_test)我来通过查询文档分别看下train_test_split和KNeighborsClassifier这两个函数需要的参数:
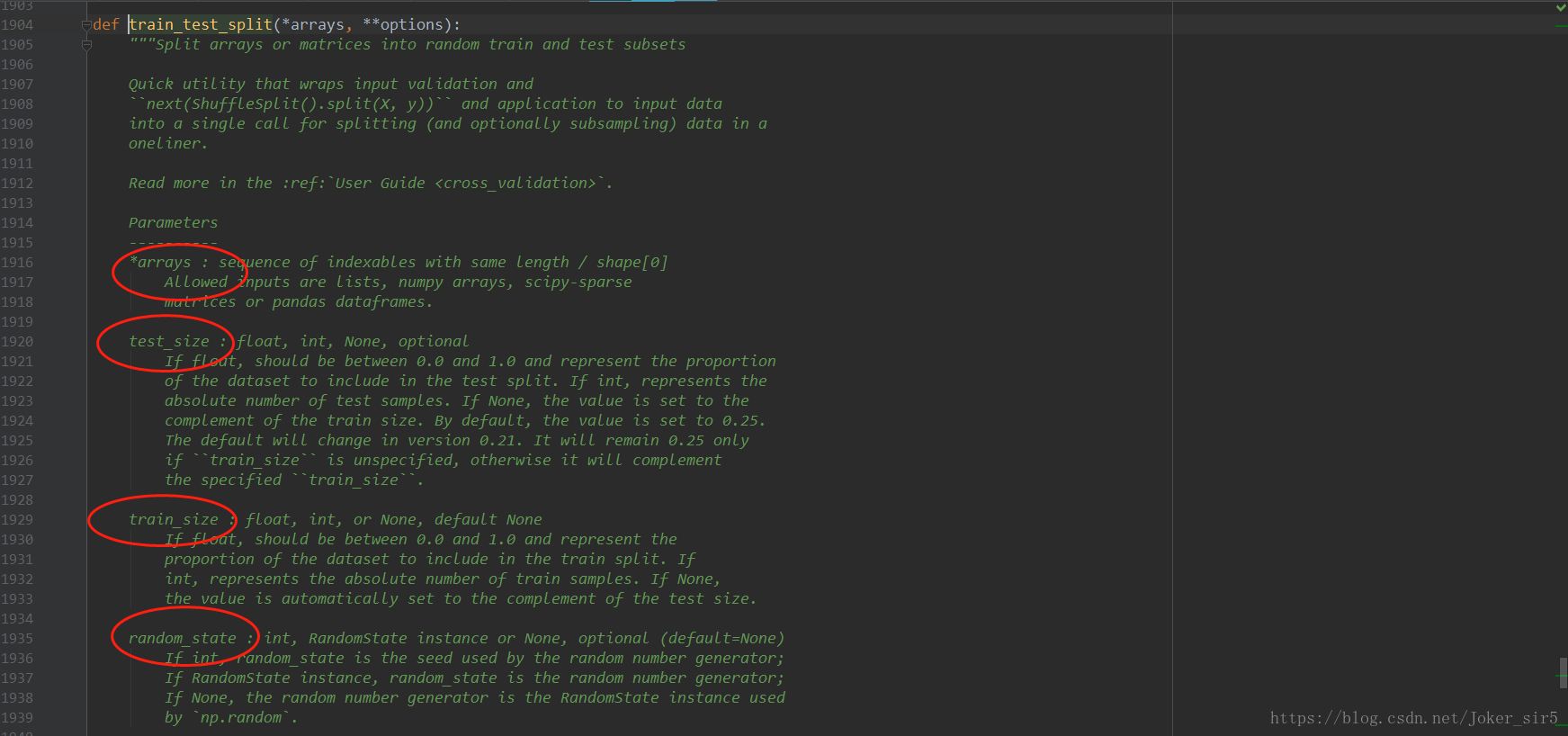
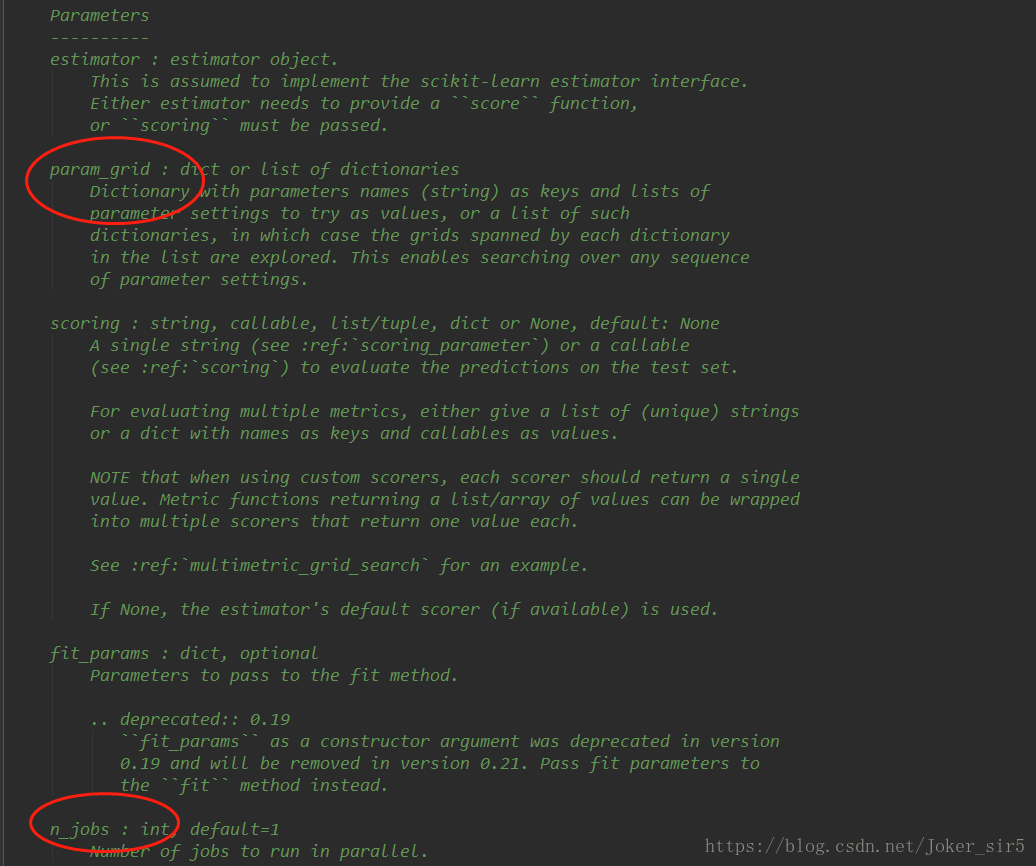
train_test_split的作用就是将数据集分割为train set和test set,被封装在sklearn.model_selection中,需要传入的常用参数如上图所示,介绍下random_state,默认“None”,它的作用就是为了是每次random出来的train set和test set的结果都是一样的,和random中的seed是一样的作用,我代码里直接默认none,大家在自己跑实验的时候若想使用,可以在方法中加入参数“random_state=xxx” 。当然在他定义下方也给出了一些examples,大家可以参照:
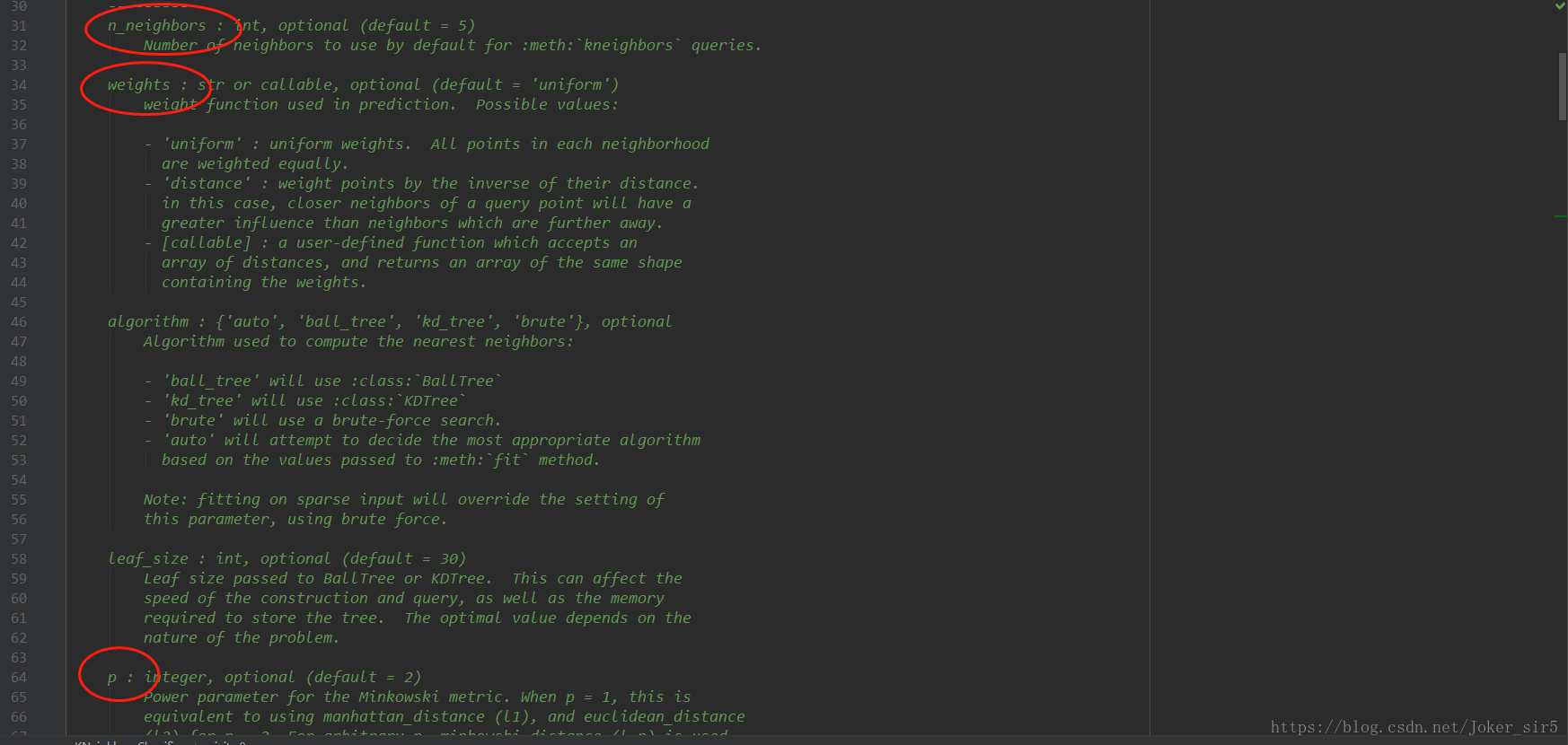
KNeighborsClassifier被封装在sklearn.neighbors中,需要传入的常用参数如下图所示,n_neighbors即KNN的k,默认5,weights即距离权重,默认“uniform”,p即闵可夫斯基距离,当p=2时,即为欧氏距离;当p=1时,即为曼哈顿距离;当p趋于无穷时,即为切比雪夫距离,默认p=2。我在代码里除了n_neighbors都使用默认值。
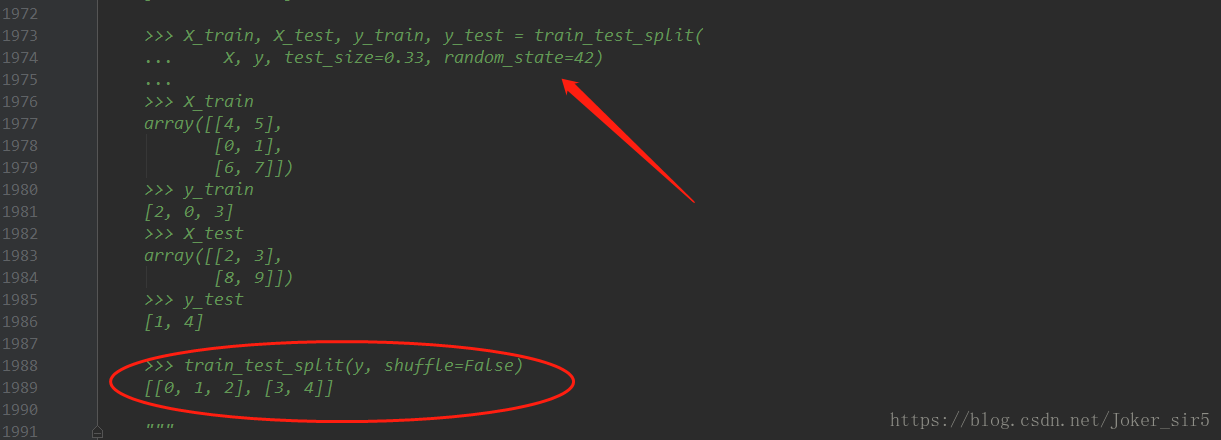
通过查询文档,我们了解了两个关键的方法的作用,读者可以试着修改下其他参数,玩一玩这个有趣的框架,这里不多赘述,直接来看实验结果:
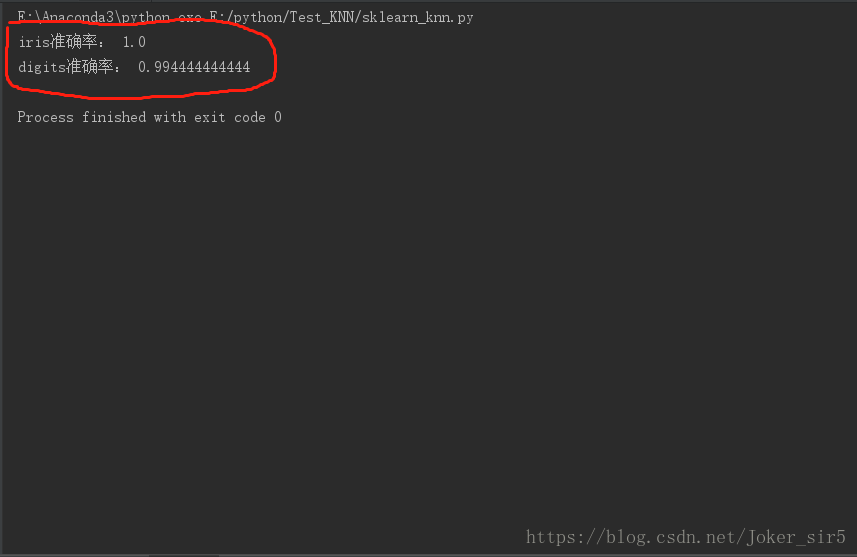
从准确率来看,我们验证了封装的KNN模型表现优良,若有新iris或digits数据,我们就可以直接进行预测了:
#预测
kNN_classifier.predict(X_predict)到此我们便完成了使用scikit-learn框架构建KNN模型,短短几行代码,便完成了我们动手实现简单的KNN(python)、KNN优化之参数设置 的大部分工作,效率大大提高!
调参
最后再来说说使用skleain调参的事情,如上述所言,主要的参数有n_neighbors,weights,p,上代码:
'''
这里我先构建自己的网格搜索:
1.不考虑weights,即uniform,这时我需要考虑参数n_neighbors(1,10);
2.考虑weights,即distance,这时我们不仅要考虑n_neighbors(1,10),
加上了距离权重,就要考虑使用什么距离,即闵可夫斯基距离中p等于多少时分类器最优(1,10)
'''
par = [
{
'weights': ['uniform'],
'n_neighbors': [i for i in range(1, 10)]
},
{
'weights': ['distance'],
'n_neighbors': [i for i in range(1, 10)],
'p': [i for i in range(1, 6)]
}
]
sk_knn = KNeighborsClassifier()
#上面的网格搜索要进行54次(9+9*5),为了速度,我将计算机的全部核都用来跑代码,所以我将n_jobs设为-1
grid_search = GridSearchCV(sk_knn, par, n_jobs=-1)
grid_search.fit(X_train, y_train)
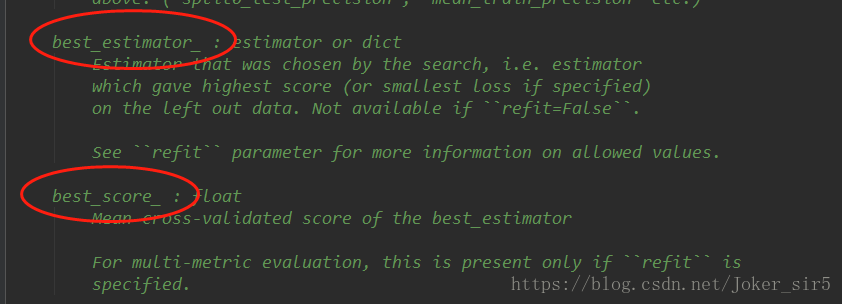
#得到最高准确率时使用的参数
print(grid_search.best_estimator_)
#打印准确率
print(grid_search.best_score_)GridSearchCV被封装在sklearn.model_selection中,我们来查询下文档,下方也有examples,感兴趣可以去查阅文档:
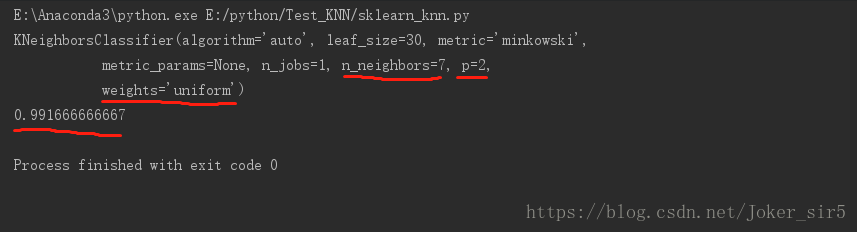
我们来看结果,iris数据集,当k=7,p=2(欧氏距离),不考虑权重(uniform)时,性能达到最优,准确率为0.991666666667,通过这样的调参,我们就可以完成对模型参数的重新改良,进而使模型达到最优!:
注意:一个小细节,如果测得的参数,如k或p偏向于给定范围的右边,那么就需要重新适当扩大网格搜索的范围,因为在原先范围的右边界处可能会有更优的参数选项!
总结
到此,我们完成了KNN的所有工作,从前两篇博客底层编写动手实现简单的KNN(python)、KNN优化之参数设置,到本篇的使用scikit-learn模型构建,使我对KNN有了更深刻的理解,随着后边的学习,愿征服所有常用的机器学习算法,在学习过程中我会经常反思,常回过头来翻阅这些算法,加深记忆,这也是我此次整理笔记的目的,愿与各位分享自己在学习过程中的体会与个人理解。文中若有表述有误之处,或不足之处,请于下方留言,不胜感激!