目标
爬取豆瓣电影上至少10部电影的短评数据。
本例中爬取开始的链接是豆瓣电影排行榜,可以看到刚好有10部。
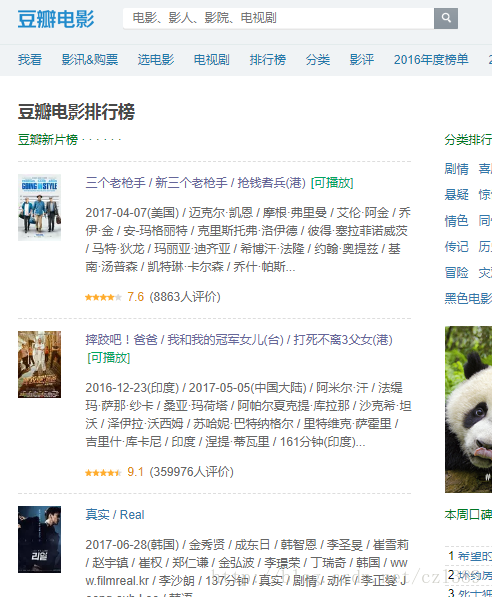
点击每个电影的标题会切入电影简介页。
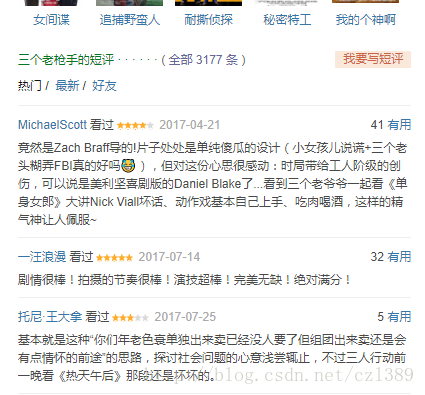
这个页面仅包含电影的部分评论。通过访问“全部**条”超链,可进入评论页。
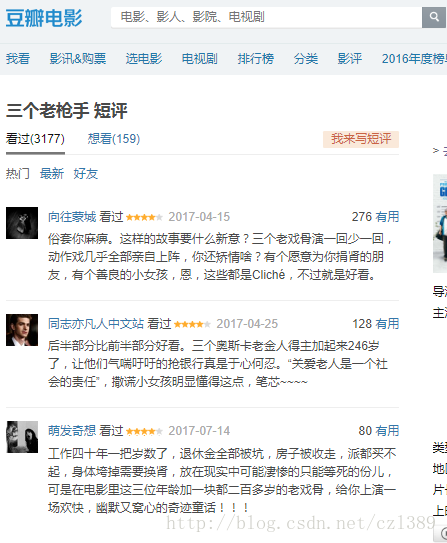
我们从该页面获取电影的片名、评论用户、评分、评论内容数据。
另外为了获得全部的评论数据,需要注意翻页,我们会在程序中处理这种情况。

建立scrapy项目
通过命令行scrapy startproject douban 建立一个叫做douban的项目。本项目中间件,pipeline中没有任何自定义内容。在item中定义要爬取的字段:
扫描二维码关注公众号,回复:
2639677 查看本文章

# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class DoubanItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
movie = scrapy.Field()
user = scrapy.Field()
star = scrapy.Field()
comment = scrapy.Field()包含模拟登陆的爬虫
主要的工作量在于完成爬虫。为了防止权限问题,在爬虫部分加入了模拟登陆。
# -*- coding:utf-8 -*-
import scrapy
from douban.items import DoubanItem
from faker import Factory
import urlparse
f = Factory.create()
class CommentSpider(scrapy.Spider):
name = "comment_spider"
start_urls = [
#'https://movie.douban.com/chart'
'https://www.douban.com'
]
formdata={
'form_email': '[email protected]',
'form_password': 'Glory05&',
# 'captcha-solution': '',
# 'captcha-id': '',
#'login': '登录',
#'redir': 'https://www.douban.com/',
'source':'index_nav'
}
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3',
'Connection': 'keep-alive',
#'Host': 'accounts.douban.com',
#'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36'
'User-Agent': f.user_agent()
}
def start_requests(self):
return [scrapy.Request(url='https://www.douban.com/accounts/login',
headers=self.headers,
meta={'cookiejar': 1},
callback=self.parse_login)]
def parse_login(self, response):
# 如果有验证码要人为处理
if 'captcha_image' in response.body:
print 'Copy the link:'
link = response.xpath('//img[@class="captcha_image"]/@src').extract()[0]
print link
captcha_solution = raw_input('captcha-solution:')
captcha_id = urlparse.parse_qs(urlparse.urlparse(link).query, True)['id']
self.formdata['captcha-solution'] = captcha_solution
self.formdata['captcha-id'] = captcha_id
return [scrapy.FormRequest.from_response(response,
formdata=self.formdata,
headers=self.headers,
meta={'cookiejar': response.meta['cookiejar']},
callback=self.after_login
)]
def after_login(self, response):
#站内的测试链接,用来判断是否登入成功
test_url = "https://www.douban.com/people/90868630/"
if response.url==test_url:
if response.status==200:
print '***************'
print u'登录成功'
print '***************\n'
else:
print '***************'
print u'登录失败'
print '***************\n'
yield scrapy.Request(test_url,
meta={'cookiejar': response.meta['cookiejar']},
headers=self.headers,
callback=self.after_login)
#self.headers['Host'] = "www.douban.com"
yield scrapy.Request(url='https://movie.douban.com/chart',
meta={'cookiejar': response.meta['cookiejar']},
headers=self.headers,
callback=self.parse_movie_url)
#def start_requests(self):
# return [scrapy.Request(url='https://movie.douban.com/chart',
# headers=self.headers,
# callback=self.parse_movie_url)]
def parse_movie_url(self, response):
for movie_url in response.xpath('.//div[@class="article"]/div/div/table//td[1]//a[@class]/@href').extract():
#yield {'url':movie_url}
yield scrapy.Request(movie_url,headers=self.headers,callback=self.parse_comments_url)
def parse_comments_url(self,response):
comment_url=response.xpath('.//div[@id="comments-section"]/div/h2/span/a/@href').extract_first()
#yield {'url':comment_url}
yield scrapy.Request(comment_url,headers=self.headers,callback=self.parse_comments)
def parse_comments(self,response):
print response.status
print response.url
movie_name=response.xpath('.//div[@id="content"]/h1/text()').extract_first()
comments=response.xpath('.//div[@class="article"]/div[@class="mod-bd"]/div[@class="comment-item"]/div[@class="comment"]')
next_page=response.xpath('//div[@id="paginator"]//a[@class="next"]')
for comment in comments:
user_name=comment.xpath('./h3/span[2]/a/text()').extract_first()
star=comment.xpath('./h3/span[2]/span[2]/@class').extract_first()
comment_content=comment.xpath('./p/text()').extract_first()
item=DoubanItem()
item['movie']=movie_name
item['user']=user_name
item['star']=star
item['comment']=comment_content
yield item
if(len(next_page)!=0):
next_page_url=response.urljoin(next_page.xpath('./@href').extract_first())
print '\n\n'
print next_page_url
print '\n\n'
yield scrapy.Request(next_page_url,headers=self.headers,callback=self.parse_comments)函数调用的入口在于start_requests,它是爬虫基类的成员函数。
parse_login实现了模拟登陆的功能,验证码通过访问验证码地址,手动输入。下面的语句实现了提交表单进行登陆:
return [scrapy.FormRequest.from_response(response,
formdata=self.formdata,
headers=self.headers,
meta={'cookiejar': response.meta['cookiejar']},
callback=self.after_login
)]在after_login完成了登陆验证。原理是尝试访问一个只有账号登陆之后才能访问的链接,如果能够正常访问,则打印“登录成功”。另外对电影的url进行解析,发起request,并交由parse_url处理。
根据页面的层次深度,解析评论内容并获得各字段数据的函数是parse_comments。其中加入了是否有下一页的判断,如果有,则发起request,并交由parse_comments处理。