前提是在ubuntu16.04下配置好caffe2和fb的深度学习开源框架detectron,可以参考我前面的博客:ubuntu16.04下caffe2与dectectron配置
一、数据准备
我的数据格式是voc,而detectron要求的数据格式是json,因此首先要进行格式的转换。
1.数据放置
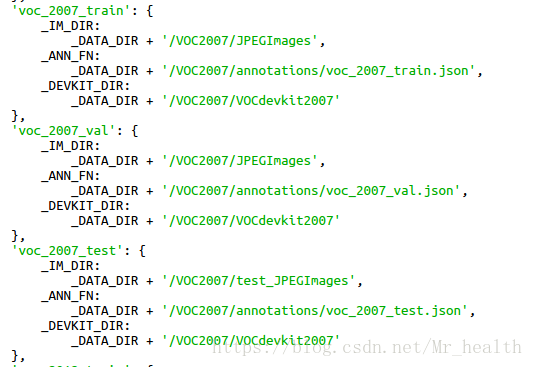
官方网站上的要求的数据存放见左图,也就是说无论我们自己要训练什么数据,文件夹的名称必须是VOC+year。但是为什么要是VOC+year这样的形式呢,我们再翻看一下datasets/dadataset_catalog.py这个函数(右图),可以看到里面有各种数据集,包括voc2007、voc2012。实际上这些就是数据接口,也就是说我们把自己的数据按照接口的形式准备好,detectron就会调用。
一般情况下,我们的数据集可以分为三部分,一部分是训练数据(train),第二部分验证数据(val)、第三部分是测试数据(test)。实际上验证数据和测试数据都可以被称为测试数据,只是功能有所不同。验证数据(val)由于其带标签,在测试中往往会输出mAP,用以评估模型的性能,而测试数据(test)不含有标签,实际上就是当我们训练好了模型,那就在我的一个数据库上试试呗,看检测出来好玩不,测试数据(test)就这样一个数据库。右图中voc_2007_train就是用于训练,voc_2007_val用于验证,voc_2007_test用于测试。
但是实际上在我们训练模型的时候,只将数据集分为训练数据和测试数据,只是这时候的测试数据功能上是对模型的评估,所以在代码的书写上都以val指代,称呼上就是测试数据(下文就这么称呼了)。

创建一个VOC2007的文件夹,将数据存放在在JPEGImages,将训练数据和测试数据的xml文件分别放置在train_Annotations和val_Annotations中。同时可以创建一个Annotations文件夹,用来存放转换后的json文件,也就是上图中的annotations。由于我选择的year=2007,因此转换后的训练数据和测试数据文件名称分别为:voc_2007_train.json,voc_2007_val.json。
最后创建VOCdevkit2007文件夹,其结构如下(里面还有一个VOC2007文件),注意其中的ImageSets/Main目录中存放的是自己数据的train.txt和val.txt,Annotations存放自己的数据的xml文件(也就是train_Annotations和val_Annotations的集合,因为模型评估中仍采用voc数据集的方式,所以只需要val数据的xml支持)
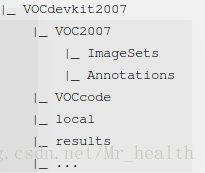
最终形成的目录应为:
VOC2007
|_ JPEGImages
| |_ <im-1-name>.jpg
| |_ ...
| |_ <im-N-name>.jpg
|_ annotations
| |_ voc_2007_train.json
| |_ voc_2007_val.json
|_ VOCdevkit2007
|_ VOC2007
|_ ImageSets
|_train.txt
|_val.txt
|_ Annotations
|_ VOCcode
|_ local
|_ results
|_ ...上图中有一处错误,不必有train.txt
因为篇幅有限,xml转json格式的代码借用xml2json。
2.修改VOCcode中的VOCinit
将其中的VOC2007 classes改为你自己的classes名称,对于我的是
VOCopts.classes={...
'airport'
'bridge'
'harbor'};
3.创建数据软链接
经过1-2步骤我们准备好了数据存放的形式,它可以保存在计算机的任何位置。但是detectron中数据接口对VOC2007文件夹的位置却是有要求的,这也就是为什么我们要建立数据软链接
DETECTRON=/home/yantianwang/clone/detectron #这个是我Detectron的目录
mkdir -p $DETECTRON/detectron/datasets/data/VOC2007 #这个是把上述的VOC2007链接到detectron中存放数据的位置
ln -s /home/yantianwang/clone/VOC2007/JPEGImages $DETECTRON/detectron/datasets/data/VOC2007/JPEGImages
ln -s /home/yantianwang/clone/VOC2007/Annotations $DETECTRON/detectron/datasets/data/VOC2007/annotations
ln -s /home/yantianwang/clone/VOC2007/VOCdevkit2007 $DETECTRON/detectron/datasets/data/VOC2007/VOCdevkit2007也就是把你自己VOC2007文件中的JPEGImages、Annotations、VOCdevkit2007创建一个快捷方式到datasets/data/VOC2007中,也就是detectron要求的位置
二、模型训练
在/home/yantianwang/clone/detectron中创建一个文件夹experiments,用于存放模型,配置文件(yaml文件),以及最后训练核测试后的结果。
这里我采用Retianet50+FPN来训练自己的数据
1.下载模型
官方下载地址:model-zoo
下载R-50.pkl到experiments文件夹中
2.设置配置文件
将configs/12_2017_baselines中的retinanet_R-50-FPN_1x.yaml拷贝到experiments文件中,主要修改
NUM_CLASSES: 你自己的类别数+1(因为有背景)
MAX_ITER:迭代次数
TRAIN:
WEIGHTS: /home/yantianwang/clone/detectron/experiments/R-50.pkl (因为我习惯在spyder中运行,所以路径是绝对路径)
DATASETS: ('voc_2007_train',) 也就是修改为我们刚刚转换格式后json文件
TEST:
DATASETS: ('voc_2007_val',) 修改成我们的val,训练完毕后会自动进行测试,输出mAP
OUTPUT_DIR: /home/yantianwang/clone/detectron/experiments/result 训练结果和测试结果的存放路径
注意,训练中很多参数是可以修改的,见detectron/core/config.py,如果你要修改的话,不用在py文件中,直接在这个.yaml文件中的相应位置写出参数名字,后面跟上修改的数值即可。例如我想修改:

该参数是归在TRAIN下的(因为是C.TRAIN) ,因此我在.yaml文件中的TRAIN下作如下添加即可:

3.开始训练
用spyder打开Detectron/tools/train_net.py文件,修改parse_args()函数:
注释掉 :
if len(sys.argv) == 1:
parser.print_help()
sys.exit(1)修改:
parser.add_argument(
'--cfg',
dest='cfg_file',
help='Config file for training (and optionally testing)',
default= '/home/yantianwang/clone/detectron/experiments/retinanet_R-50-FPN_1x.yaml', #配置文件的绝对路径
type=str修改完毕点击运行就可以了
注意:如果你不想利用spyder进行调试,而只是想通过下面的命令终端运行,那么就不用修改train_net.py,同时.yaml配置文件中的路径也统统修改为相对路径。
python2 tools/train_net.py \
--cfg experiments/retinanet_R-50-FPN_1x.yaml \
OUTPUT_DIR experiments/result