本文为原创文章转载必须注明本文出处以及附上 本文地址超链接 以及 博主博客地址:http://blog.csdn.net/qq_20259459 和 作者邮箱( [email protected] )。
(如果喜欢本文,欢迎大家关注我的博客或者动手点个赞,有需要可以邮件联系我)
接上一篇文章(阅读上一篇文章:http://blog.csdn.net/qq_20259459/article/details/54602056 )
在介绍完MatConvNet相关的Code之后,现在开始介绍如何使用这个toolbox来训练自己的data。
首先我想介绍如何利用mnist的模型来训练自己的data。在网上我看到有很多人在用imagenet的模型来训练自己的数据,写的都很好,但是好像很少有人写mnist的模型所以我想写一下。当然后面也会更新imagenet相关的介绍。
在我自己学习使用的过程中我发现mnist的模型似乎并不可以使用长方形的input。否则在训练多类误差的过程中会出现维度的错误,当然我也认为是可以修改的,不过与其修改不如直接使用imagenet模型更为便捷。
训练自己的数据的时候,有一些问题需要注意,否则没法运行。
一、input不一定要为正方形,但是在softmax层的INPUT需要为1*1的数据。
二、根据input的大小需要增加layers以确保最后的softmax的数据size为1*1。
三、所需要训练的数据必须有完整的test和train的部分,可自己分配一般比例为3比7。
四、每次训练结束之后如需改变input需要手动删除以创建的train的结构体。
五、在创建label的时候一定要注意test和train的需要分开以免调用的时候出现错位影响结果。
六、当运行可以的时候要做的就是调整,需要通过改变相关的变数和网络的层数以得到最佳的结果。
今天我先写一下通过改变mnist的大小作为自己的新的数据来尝试第一次训练,以证明程序可行性。
主要Code(尝试扩大2倍):
function cnn_mnist_NNclass(varargin)
warning off
% CNN_MNIST Demonstrated MatConNet on MNIST
%% 运行初始化CNN网络
% run( fullfile(fileparts(mfilename('fullpath')), '../matlab/vl_setupnn.m') ) ;
run('C:\Users\Desktop\matconvnet-1.0-beta23\matconvnet-1.0-beta23\matlab/vl_setupnn.m') ;
%% 初始化网络相关数据
opts.dataDir = 'data/mnist' ; % data的标签的路径
opts.expDir = 'data/mnist-baseline' ; % data的路径
opts.imdbPath = fullfile(opts.expDir, 'imdb.mat'); % data的fullfile=data/mnist-baseline/imdb.mat
opts.train.batchSize = 100 ; % 选择batch大小
opts.train.numEpochs = 100 ; % 选择epoch个数
opts.train.continue = true ; % 选择判断条件
% opts.train.useGpu = true ;
opts.train.gpus = [];
% opts.train.gpus = 1; % 选择是否使用GPU
opts.train.learningRate = 0.001 ; % 选择CNN学习率
opts.train.expDir = opts.expDir ; % 训练数据的保存位置
opts = vl_argparse(opts, varargin); % 调用vl_argparse函数
opts.train.subsetSize = 1e4; % statsogk 子图的大小
%% 准备数据
% --------------------------------------------------------------------
% Prepare data
% --------------------------------------------------------------------
if exist(opts.imdbPath) % 如果存在imdb.mat
imdb = load(opts.imdbPath) ; % 载入数据
else % 如果不存在
imdb = getMnistImdb(opts) ; % 获得数据
mkdir(opts.expDir) ; % 调用mkdir
save(opts.imdbPath, '-struct', 'imdb') ; % 保存在路径下
end
% Use a subset of the images for faster training.
if opts.train.subsetSize > 0 % 如果子图大小大于0
imdb = getSubset(imdb,opts); % 调用getSubset
end
%% 定义CNN网络
% Define a network similar to LeNet
f=1/100 ; % 初始化一个f
net.layers = {} ; % 初始化一个空layer
net.layers{end+1} = struct('type', 'conv', ... %% 定义C1层
'filters', f*randn(5,5,1,20, 'single'), ... % filter大小(5*5*1)*20
'biases', zeros(1, 20, 'single'), ... %
'stride', 1, ... % 移动为1
'pad', 0) ; % 没有pad
net.layers{end+1} = struct('type', 'pool', ... %% 定义pooling层
'method', 'max', ... % pooling类型为max
'pool', [2 2], ... % filter大小为2*2
'stride', 2, ... % 移动为2
'pad', 0) ; % 没有pad
net.layers{end+1} = struct('type', 'conv', ... %% 定义C2层
'filters', f*randn(5,5,20,50, 'single'),...
'biases', zeros(1,50,'single'), ...
'stride', 1, ...
'pad', 0) ;
net.layers{end+1} = struct('type', 'pool', ... %% 定义pooling层
'method', 'max', ...
'pool', [2 2], ...
'stride', 2, ...
'pad', 0) ;
net.layers{end+1} = struct('type', 'conv', ... %% 定义C3层
'filters', f*randn(4,4,50,100, 'single'),...
'biases', zeros(1,100,'single'), ...
'stride', 1, ...
'pad', 0) ;
net.layers{end+1} = struct('type', 'pool', ... %% 定义pooling层
'method', 'max', ...
'pool', [2 2], ...
'stride', 2, ...
'pad', 0) ;
net.layers{end+1} = struct('type', 'conv', ... %% 定义C2层
'filters', f*randn(3,3,100,500, 'single'),...
'biases', zeros(1,500,'single'), ...
'stride', 1, ...
'pad', 0) ;
net.layers{end+1} = struct('type', 'pool', ... %% 定义pooling层
'method', 'max', ...
'pool', [2 2], ...
'stride', 2, ...
'pad', 0) ;
% % % % net.layers{end+1} = struct('type', 'conv', ... %% 定义C2层
% % % % 'filters', f*randn(3,3,500,1000, 'single'),...
% % % % 'biases', zeros(1,1000,'single'), ...
% % % % 'stride', 1, ...
% % % % 'pad', 0) ;
% % % % net.layers{end+1} = struct('type', 'pool', ... %% 定义pooling层
% % % % 'method', 'max', ...
% % % % 'pool', [2 2], ...
% % % % 'stride', 2, ...
% % % % 'pad', 0) ;
net.layers{end+1} = struct('type', 'relu') ; %% 定义relu层
net.layers{end+1} = struct('type', 'conv', ... %% 定义FC层
'filters', f*randn(1,1,500,10, 'single'),... % 大小为1*1的全连接,厚度为500,10次
'biases', zeros(1,10,'single'), ... %
'stride', 1, ... % 移动为1
'pad', 0) ; % 没有pad
net.layers{end+1} = struct('type', 'softmaxloss') ; % 定义SMFC
%% Train 部分
% --------------------------------------------------------------------
% Train
% --------------------------------------------------------------------
% Take the mean out and make GPU if needed
imdb.images.data = bsxfun(@minus, imdb.images.data, mean(imdb.images.data,4)) ; % 减去mean值
% if opts.train.useGpu
if opts.train.gpus % 如果使用GPU
imdb.images.data = gpuArray(imdb.images.data) ; % 读取data
end
%% 调用CNN_Train
[ net, info ] = cnn_train(net, imdb, @getBatch, opts.train, 'val', find(imdb.images.set == 3)) ;
%% 得到data和相应的label。
% --------------------------------------------------------------------
function [im, labels] = getBatch(imdb, batch)
% --------------------------------------------------------------------
im = imdb.images.data(:,:,:,batch) ;
labels = imdb.images.labels(1,batch) ;
%% 打开data文件
% --------------------------------------------------------------------
function imdb = getMnistImdb(opts)
% --------------------------------------------------------------------
files = {'train-images-idx3-ubyte', ...
'train-labels-idx1-ubyte', ...
't10k-images-idx3-ubyte', ...
't10k-labels-idx1-ubyte'} ;
%% 获得data
mkdir(opts.dataDir) ;
for i=1:4
if ~exist(fullfile(opts.dataDir, files{i}), 'file')
url = sprintf('http://yann.lecun.com/exdb/mnist/%s.gz',files{i}) ;
fprintf('downloading %s\n', url) ;
gunzip(url, opts.dataDir) ;
end
end
f=fopen(fullfile(opts.dataDir, 'train-images-idx3-ubyte'),'r') ;
x1=fread(f,inf,'uint8');
% x1=zscore(x1);
fclose(f) ;
x1=permute(reshape(x1(17:end),28,28,60e3),[2 1 3]) ;
x11 = x1(:,:,1);
x12 = x1(:,:,2);
x13 = x1(:,:,3);
x11 = imresize(x11,2);
x12 = imresize(x12,2);
x1 = cat(3,x11,x12,x13);
f=fopen(fullfile(opts.dataDir, 't10k-images-idx3-ubyte'),'r') ;
x2=fread(f,inf,'uint8');
% x2=zscore(x2);
fclose(f) ;
x2=permute(reshape(x2(17:end),28,28,10e3),[2 1 3]) ;
x21 = x2(:,:,1);
x22 = x2(:,:,2);
x23 = x2(:,:,3);
x21 = imresize(x21,2);
x22 = imresize(x22,2);
x2 = cat(3,x21,x22,x23);
f=fopen(fullfile(opts.dataDir, 'train-labels-idx1-ubyte'),'r') ;
y1=fread(f,inf,'uint8');
fclose(f) ;
y1=double(y1(9:end)')+1 ;
f=fopen(fullfile(opts.dataDir, 't10k-labels-idx1-ubyte'),'r') ;
y2=fread(f,inf,'uint8');
fclose(f) ;
y2=double(y2(9:end)')+1 ;
imdb.images.data = single(reshape(cat(3, x1, x2),56,56,1,[])) ;
imdb.images.labels = cat(2, y1, y2) ; % 得到[ y1 y2 ]
imdb.images.set = [ones(1,numel(y1)) 3*ones(1,numel(y2))] ;
imdb.meta.sets = {'train', 'val', 'test'} ;
imdb.meta.classes = arrayfun(@(x)sprintf('%d',x),0:9,'uniformoutput',false) ;
% ------------------------------------------------------------------------------
function imdb = getSubset(imdb,opts)
% ------------------------------------------------------------------------------
assert(opts.train.subsetSize <= nnz(imdb.images.set == 1),...
'Subset size is bigger than the total train set size')
inds = find(imdb.images.set == 1); % indices must be from the train set
inds = randsample(inds, length(inds)-opts.train.subsetSize );
imdb.images.labels(inds) = [];
imdb.images.set(inds) = [];
imdb.images.data(:,:,:,inds) = [];
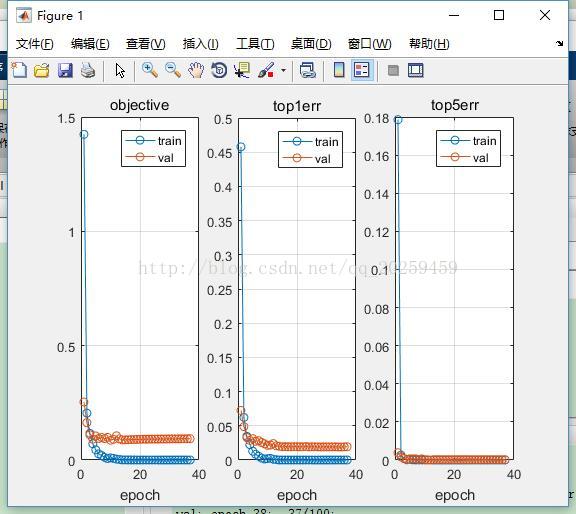
虽然并没有训练结束,大家可以看到至少我们得到了正确的结果。
先写到这里,大家可以根据上面的code理解一下。
后面会持续更新。
本文为原创文章转载必须注明本文出处以及附上 本文地址超链接 以及 博主博客地址:http://blog.csdn.net/qq_20259459 和 作者邮箱( [email protected] )。
(如果喜欢本文,欢迎大家关注我的博客或者动手点个赞,有需要可以邮件联系我)