作者:
Ari S. Morcos, David G.T. Barrett, Neil C. Rabinowitz, & Matthew Botvinick
DeepMind
London, UK
ICLR 2018
发布时间:22 May 2018
这篇文章是来探究direction(可以简单理解为节点)的和某一类的对应程度和重要性程度的关系,试图给以神经网络学习出来的东西以解释性。
APPROACH
PERTURBATION ANALYSES
Ablations消融
用去除某一single direction,网络的性能降低的程度来衡量了direction对网络计算的重要性。对于MLPs,我们去除某个节点,对于卷积网络,我们去除一整特特征图。我们把他们称之为‘units’。
有意思的是我们发现将units的值置为平均值对网络性能的影响要大于直接置为0,如下图。
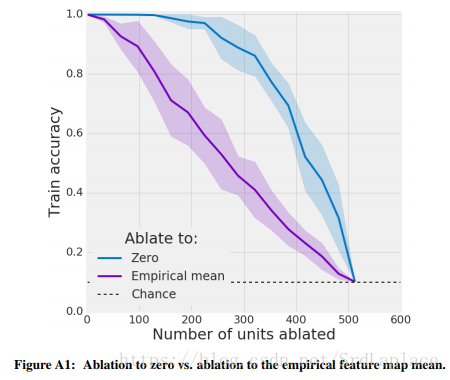
一个明显的推理是网络在低维激活子空间上越依赖,随着单个方向被消融,准确度将下降得越快。
Addition of noise
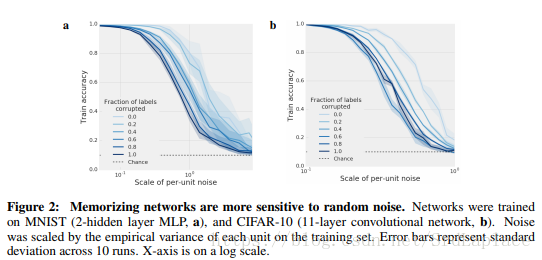
对每个unit加上均值为0的高斯白噪声来测试网络性能的下降。这样来测试网络对随机direction的依赖。(消融测试的是对coordinate-aligned single directions的影响)
QUANTIFYING CLASS SELECTIVITY
类别选择性:
表示label为某个类别时某个unit的平均激活水平,
表示label不为某个类别时某个unit的平均激活水平。这个类别选择性在0和1之间,0表示这个unit对所有类别都一样,1表示这个unit只有在某个类别时才激活。
我们也用互信息作为类别选择性的指标。
EXPERIMENTS
GENERALIZATION
按一定比例改变随机给与样本标签,随机比例越多,每一类别的相似性越差,就需要网络死记硬背一些标签,这样的网络泛化能力差,我们称之为memorizing network,与之相反的称为structurefinding network。
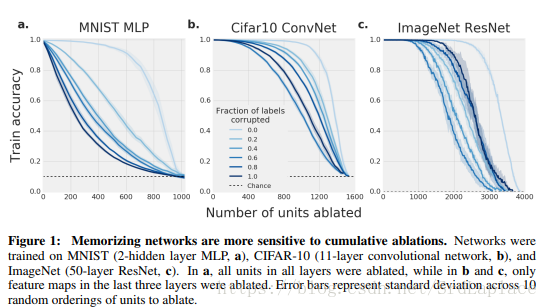
直观上,泛化能力弱的memorizing network应该比泛化能力好的structurefinding network需要调用更多的模型容量,因为在训练集上的正确性只是单纯的记住,所以需要更多特征来描述输入样本,进而需要更多的single directions。所以如下图所示,记忆网络更容易被ablations和random noise影响。
我们训练200个相同拓扑结构的神经网络,仅仅是初始化权重,learning rate,数据的顺序不同,画出泛化误差最好和最差的5个模型的消融曲线,然后再画出AUC和泛化误差的关系,如下图
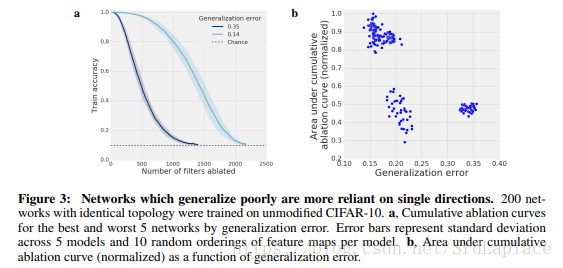
这些结果表明,泛化性能和single direction之间的依赖关系不仅仅是使用错误标签进行训练的副作用,而且存在于具有相同训练数据的网络集合中。
RELIANCE ON SINGLE DIRECTIONS AS A SIGNAL FOR MODEL SELECTION
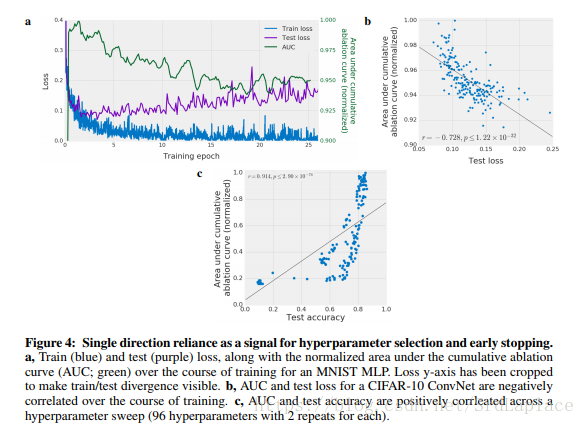
既然single direction依赖可以估计泛化性能,我们来探究一下测试集上的性能、early-stop、hyperpameter selection与single direction的关系,下图显示了消融曲线的AUC与test loss负相关,与test acc正相关。
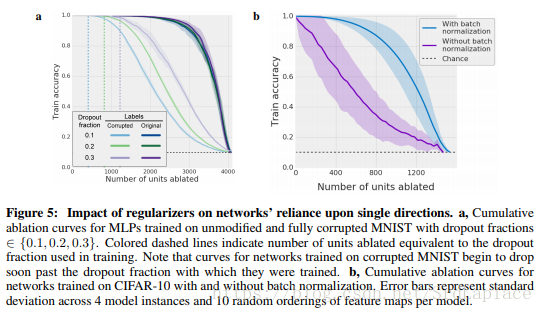
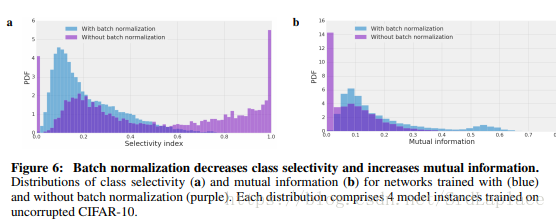
下图展示了dropout和BN与消融的关系,感觉上是这两种正则化都是减少single direction依赖来提高网络的泛化性能。
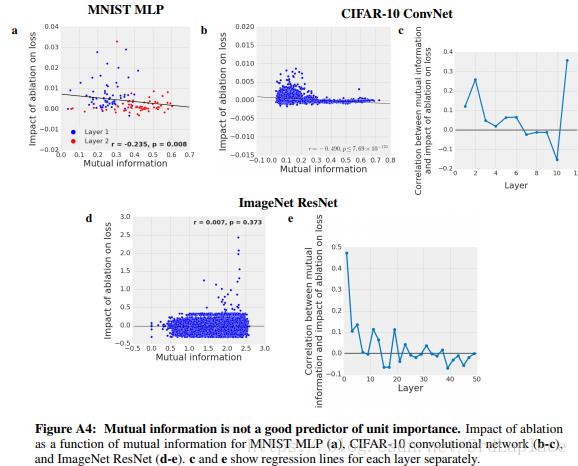
RELATIONSHIP BETWEEN CLASS SELECTIVITY AND IMPORTANCE
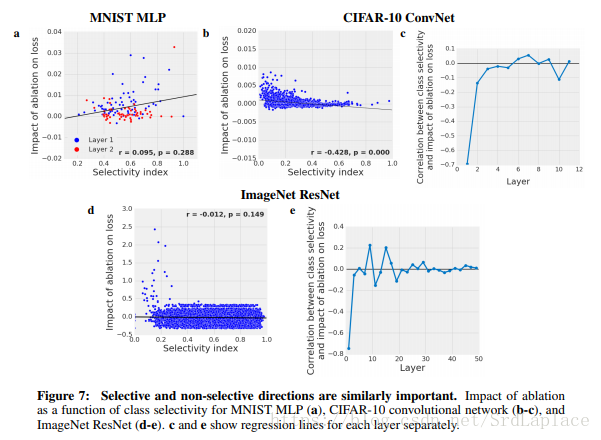
下图展示了类别选择性和unit重要性的关系,发现负相关或者是不相关
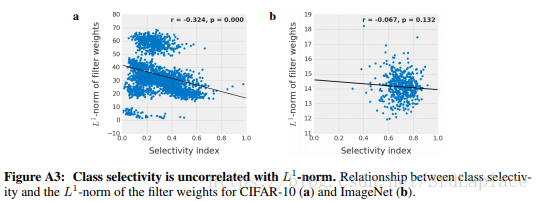
最后我们发现类别选择性和L1正则化有一定的负相关。
这些结果表明类别选择性不是网络性能良好的预测因子,并且类别选择性实际上可能对网络性能有害。者可能需要进一步的工作来确认这个结论。
DEPTH-DEPENDENCE OF CLASS SELECTIVITY
网络深度和类别选择性的关系,由下图可以看出,越深类别选择性越强。
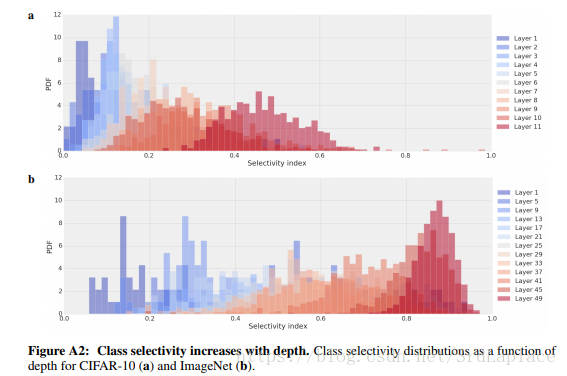
这也符合直觉,因为输出层显然是类别选择性极高的。
DISCUSSION
实验表明,泛化能力与网络one direction依赖性有关;实验还表明,BN似乎是通过降低one direction依赖性来进行正则化的。
这项工作的一个明显的扩展是构建一个更直接对single direction reliance惩罚的正则项。最明显的regularize single direction reliance是dropout和变种dropout,但是结果表明提高drop比例并没有提高消融曲线的AUC。
文章中展示的结果表明,人们能够在不使用验证或测试集的情况下预测网络的泛化性能,我们可以用下面几种方式利用这个性质:
- 在标记的训练数据稀少的情况下,测试网络single direction reliance可以提供评估泛化性能的机制,而不需要牺牲用作验证集的训练数据。
- 通过使用容易计算的single direction reliance,用作 early-stopping或超参数选择的信号。 我们已经证明这在简单数据集中是可行的,但是需要进一步的工作来评估更复杂的数据集中的可行性。
进一步研究的另一个有趣方向是评估不同正则化下single direction reliance与泛化误差之间的关系。
读后感
这篇工作的结论还是有点出乎意料的。因为想当然的是网络的输出层明显是direction reliance,不然没法进行预测,但这篇工作告诉我们single direction的类别选择性与它们对网络输出的最终重要性在很大程度上不相关,而且BN降低了single direction的类别选择性,这表明,高的类别选择性unit实际上可能对网络性能有害。说明分析高选择性单个unit来理解神经网络的方法,可能思路不正确,那么神经网络就更加像是个黑盒了。