前言
spark的shuffle计算模型与hadoop的shuffle模型原理相似,其计算模型都是来自于MapReduce计算模型,将计算分成了2个阶段,map和reduce阶段。
一 多维度理解shuffle:
- shuffle的作用就是把map阶段和reduce阶段连接起来,充当一个桥梁的作用。
- shuffle只能产生[k,v]类型的PairRDD中,Map端的数据被Reduce端fetch时,是通过key的hashcode分发到每一个Reducer上,此过程被叫做shuffle。
- shulle过程中经历磁盘读写和网络传输,这是影响shuffle效率的根本原因。所以要进行shuffle调优。
- 具体来说shuffle过程中就是将数据从数据在map阶段产生的结果都在不同的机器上,要经过网络传输发送到Reducer上在进行聚合的一个过程。发生网络传输个过程也叫shuffle。
- 下个stage向上个stage要数据的过程被叫做shuffle。
- RDD角度:sparkRDD模型中将数据分为partion,这些partion分发在不同的机器上,分区之间通过网络传输交换数据,分区的函数无法满足执行函数的要求,比如reducebykey等,需要重新进行聚合,这个过程也被叫叫做shuffle。
二 shuffle过程的内存分配
spark的计算过程之所以快即使因为将中间结果缓存到内存当中重复使用,shuflle过程又是一个中间过程,必然要考虑内存的使用情况。
shuflle过程中,宽依赖主要有2个过程,shuffle write和shuffle fetch。
- shuffle write:将shuffleMapTask产生的中间结果缓存到内存中。
- shuffle fetch:将中间结果交给ShuffleReduceTask 进行计算。
那么这个问题就出现了,某一数据量大的时候会发生OOM,也会产生数据倾斜。
shuffle内存管理的类是ShuffleMemoryManager :用来给task任务分配资源,等任务完成后通过Excutor释放资源。
- 早期的内存分配
给每个task分配的内存都一样。问题就出现:来的数据是动态变化的,有的task任务来的数据量大,内存可能都不够用,而有的task数据量小,一下就处理完了任务,处于闲着没事干的状态,这这样的设计肯定不行。
- 1.5版本后的内存分配
为task构建了一个内存池,内存池默认大小为运行总内存的16%,每个task分配的内存大小为1/2n<m<1/n.(n为task的数量)
但是需要注意的是,这里的n是一个变量,因为有的任务很快就完成了,manager会随时追踪n的变化,重新计算task的内存分配,但是这样仍然解决不了摸个任务数据量大的情况下OOM的问题。
【内存剖析】
三 shuffle过程中的数据倾斜
数据倾斜说白了就是某一类(key)的数据在task上数据量过大,也叫数据分布不均衡。
数据倾斜的问题会引申很多其他问题,比如,网络带宽、各重硬件故障、内存过度消耗、文件掉失。因为 Shuffle 的过程中会产生大量的磁盘 IO、网络 IO、以及压缩、解压缩、序列化和反序列化等等。
四 shuffle write过程
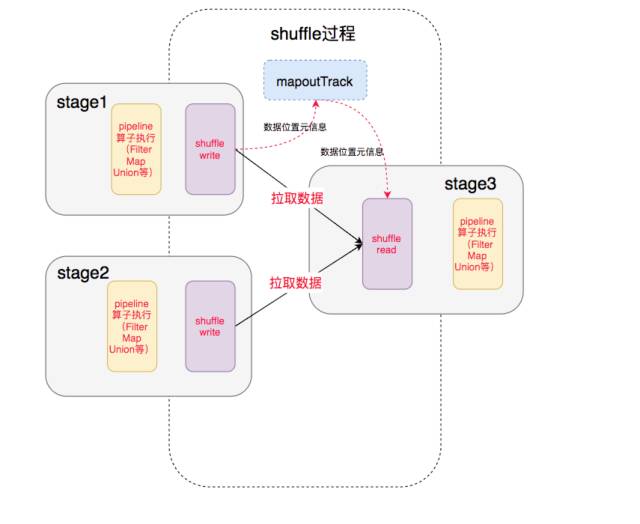
| 中间就涉及到shuffle 过程,前一个stage 的 ShuffleMapTask 进行 shuffle write, 把数据存储在 blockManager 上面, 并且把数据位置元信息上报到 driver 的 mapOutTrack 组件中, 下一个 stage 根据数据位置元信息, 进行 shuffle read, 拉取上个stage 的输出数据 |
1 spark shuffle的过程演变
- Spark 0.8及以前 Hash Based Shuffle
- Spark 0.8.1 为Hash Based Shuffle引入File Consolidation机制
- Spark 0.9 引入ExternalAppendOnlyMap
- Spark 1.1 引入Sort Based Shuffle,但默认仍为Hash Based Shuffle
- Spark 1.2 默认的Shuffle方式改为Sort Based Shuffle
- Spark 1.4 引入Tungsten-Sort Based Shuffle
- Spark 1.6 Tungsten-sort并入Sort Based Shuffle
- Spark 2.0 Hash Based Shuffle退出历史舞台
总结一下, 就是最开始的时候使用的是 Hash Based Shuffle, 这时候每一个Mapper会根据Reducer的数量创建出相应的bucket,bucket的数量是M R ,其中M是Map的个数,R是Reduce的个数。这样会产生大量的小文件,对文件系统压力很大,而且也不利于IO吞吐量。后面忍不了了就做了优化,把在统一core上运行的多个Mapper 输出的合并到同一个文件,这样文件数目就变成了 cores R 个了
2 三种shuffle write的比对,请看下面2篇博文