一,介绍
隐马尔科夫模型(Hidden Markov Model,以下简称HMM)是比较经典的机器学习模型了,它在语言识别,自然语言处理,模式识别等领域得到广泛的应用。目前随着深度学习的崛起,尤其是RNN,LSTM等神经网络序列模型的火热,HMM的地位有所下降。
使用HMM模型时我们的问题一般有这两个特征:1)我们的问题是基于序列的,比如时间序列,或者状态序列。2)我们的问题中有两类数据,一类序列数据是可以观测到的,即观测序列;而另一类数据是不能观察到的,即隐藏状态序列,简称状态序列。我们常用的谷歌输入法等就可以采用HMM模型,根据你之前的输入,判断你接下来要输入什么给出提示。
模型定义:
对于HMM模型,首先我们假设Q是所有可能的隐藏状态的集合,V是所有观测状态的集合,即:
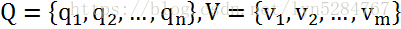
其中,N是可能的隐藏状态数,M是所有的可能的观察状态数。
对于一个长度为T的序列,I对应的状态序列, O是对应的观察序列,即:
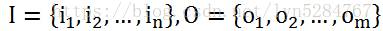
其中,任意一个隐藏状态it∈Q,任意一个观察状态ot∈V。
接着,我们做出以下假设:
1)齐次马尔科夫链假设,即任意时刻的隐藏状态只依赖于它前一个隐藏状态。我们得到如果在时刻t的隐藏状态是it=qi,在时刻t+1的隐藏状态是it+1=qj, 则从时刻t到时刻t+1的HMM状态转移概率aij可以表示为:
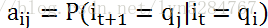
从而得到马尔科夫链的状态转移矩阵A:
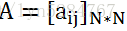
2) 观测独立性假设,即任意时刻的观察状态只仅仅依赖于当前时刻的隐藏状态。如果在时刻t的隐藏状态是it=qj, 而对应的观察状态为ot=vk, 则该时刻观察状态vk在隐藏状态qj下生成的概率为bj(k)为:
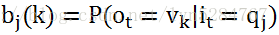
这样bj(k)可以组成观测状态生成的概率矩阵B:
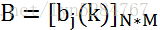
我们再获得一个初始状态t=1的初始状态概率分布Π:
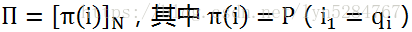
根据上面的两个假设和初始状态就可以确定一个隐马尔科夫模型。
确定HMM模型后,我们一共有三个经典的问题需要解决:
1) 评估观察序列概率。即给定模型λ=(A,B,Π)和观测序列O={o1,o2,...oT},计算在模型λ下观测序列O出现的概率P(O|λ)。这个问题的求解需要用到前向后向算法。
2)模型参数学习问题。即给定观测序列O={o1,o2,...oT},估计模型λ=(A,B,Π)的参数,使该模型下观测序列的条件概率P(O|λ)最大。这个问题的求解需要用到基于EM算法的鲍姆-韦尔奇算法。
3)预测问题,也称为解码问题。即给定模型λ=(A,B,Π)和观测序列O={o1,o2,...oT},求给定观测序列条件下,最可能出现的对应的状态序列,这个问题的求解需要用到基于动态规划的维特比算法。
二,代码实现
前向算法:
输入:HMM模型λ=(A,B,Π),观测序列O=(o1,o2,...oT)
输出:观测序列概率P(O|λ)
1) 计算时刻1的各个隐藏状态前向概率:

2) 递推时刻2,3,...T时刻的前向概率:
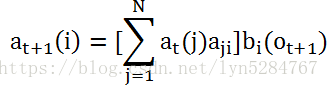
3) 计算最终结果:
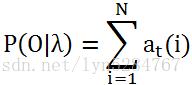
数据:
假设有三个盒子,里面装有白球和红球如下:
| 盒子 | 1 | 2 | 3 |
| 红球数 | 5 | 4 | 7 |
| 白球数 | 5 | 6 | 3 |
求O={红,白,红}概率
代码:
import numpy as np
def FB():
data = [[5,4,7],[5,6,3]] # 初始数据
pi = np.mat([0.2,0.4,0.4]) # t=1时,初始状态概率
A=np.mat([[0.5,0.2,0.3],[0.3,0.5,0.2],[0.2,0.3,0.5]]) # 状态转移矩阵
B=np.mat([[0.5,0.5],[0.4,0.6],[0.7,0.3]]) # 观察状态矩阵
N=2;M=3;O=[0,1,0] # 求输出O概率,对应为{红、白、红}
a = np.multiply(pi,B[:,O[0]].T) # 第一步,时刻1的各个隐藏状态前向概率
for i in range(1,M):
tmp = a.copy()
for j in range(M):
a[0,j]=np.multiply(tmp,A[:,j].T).sum(axis=1)*B[j,O[i]] # 第二步,递推时刻2,3,...T时刻的前向概率
p=a.sum(axis=1) # 第三步,计算最终结果
return p
if __name__=="__main__":
p=FB()
print(p){红,白,红}出现概率为:0.130218
后向算法:
输入:HMM模型λ=(A,B,Π),观测序列O=(o1,o2,...oT)
输出:观测序列概率P(O|λ)
1) 初始化时刻T的各个隐藏状态后向概率:
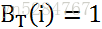
2) 递推时刻T−1,T−2,...1时刻的后向概率:
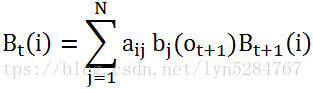
3) 计算最终结果:
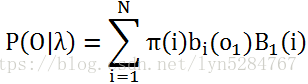
代码:
import numpy as np
# 后向算法
def BB():
pi = np.mat([0.2, 0.4, 0.4]) # t=1时,初始状态概率
A = np.mat([[0.5, 0.2, 0.3], [0.3, 0.5, 0.2], [0.2, 0.3, 0.5]]) # 状态转移矩阵
B = np.mat([[0.5, 0.5], [0.4, 0.6], [0.7, 0.3]]) # 观察状态矩阵
b=np.mat([1.0,1.0,1.0])
N = 2;M = 3;O = [0, 1, 0] # 求输出O概率,对应为{红、白、红}
i=M
while i>1:
tmp = b.copy()
for j in range(M):
ab = np.multiply(A[j,:],B[:,O[i-1]].T)
b[0,j]=np.multiply(ab,tmp).sum(axis=1) # 第二步,递推时刻2,3,...T时刻的前向概率
i-=1
pib = np.multiply(b, pi)
return np.multiply(pib,B[:,0].T).sum(axis=1)
if __name__=="__main__":
p=BB()
print(p){红,白,红}出现概率为:0.130218