1、Yarn资源不足无法提交Spark的问题
2、Yarn-Client下网络流量的问题
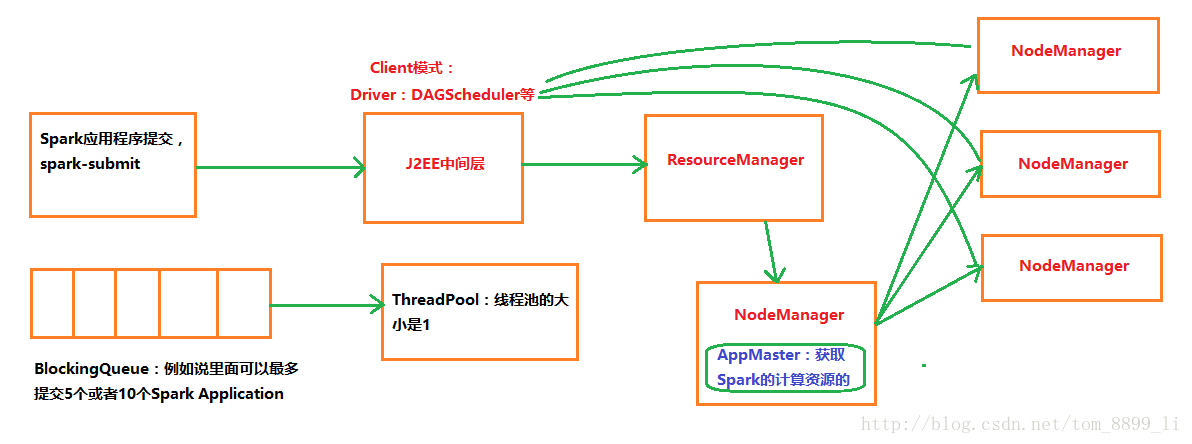
ResourceManager会接收你的提交请求吗?Yarn一般把自己的资源分成不同的类型,我们接收的时候会专门提交到分配给Spark那一组资源,例如说此时资源信息如下:Memory 1000G,Cores 800个,此时你要提交的Spark应用程序可能需要900G的内存和700个Core,一定会没有问题吗?不一定!
另外一种情况就是当前的作业可以提交运行,已经消耗了900G的内存和700个Cores,然后又提交了一个消耗500G的内存和300个Cores的Spark应用程序,这个时候资源不够,无法提交
解决方案:
第一:在J2EE中间层,通过线程池技术来实现顺利提交,可以让线程池的大小设定为1;
第二:如果你提交的Spark应用程序有些比较耗时,例如均是超过10分钟,而其他的Spark程序都在2分钟内执行完成,这个时候可以继续把Spark拥有的资源进行分类(耗时任务和快速任务),此时你可以使用2个线程池,每个线程池都是一条线程。
第三:只有一个程序在运行的时候,你可以把Memory和Cores都调整到最大,这样最大化的使用资源来最快速的完成程序的计算,同时也简化了集群的运维和故障解决。
Yarn的运行模式:
Client和Cluster模式,Cluster是Driver也在集群中,Client模式反之
在这里我们先研究Client模式。由于Driver在客户端上,和集群的网络环境可能不一致,所以网络通信的风险会导致Task丢失…
下面一个问题是:Client必然要和集群进行频繁的通信,例如说有100个Stage,每个Stage平均有10w个Task,此时一定会导致Client机器的网卡流量暴增,甚至会形成阻塞。
这个问题的解决只需要把Spark提交模式改为Yarn Cluster