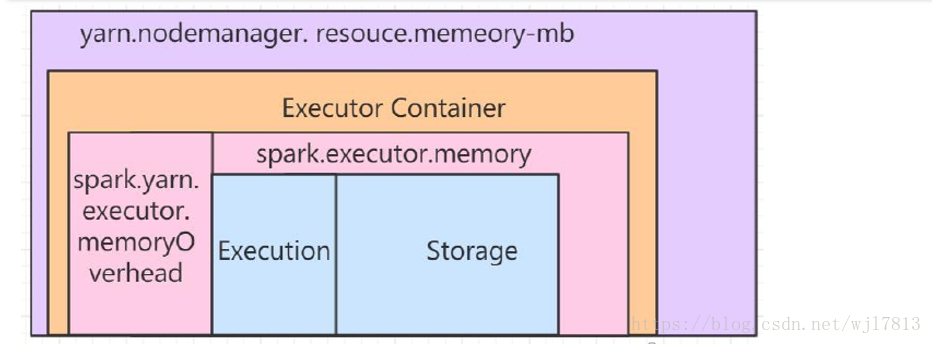
Spark的Excutor的Container内存有两大部分组成:堆外内存和Excutor内存
A) 堆外内存(spark.yarn.executor.memoryOverhead)
主要用于JVM自身的开销。默认:MAX(executorMemory*0.10,384m)
B) Excutor内存(spark.executor.memory)
Execution:shuffle、排序、聚合等用于计算的内存
Storage:用于集群中缓冲和传播内部数据的内存(cache、广播变量)
上面的 堆外内存和excutor 内存是可以相互转换使用的
两个重要参数:
spark.memory.fraction
用于设置Execution和Storage内存在内存(这个内存是JVM的堆内存-300M,这300M是预留内存)中
的占比,默认是60%(spark 2.x)。即Execution和Storage内存大小之和占堆内存比例。
spark 1.6.x 的spark.memory.fraction 默认是75%
参考链接: http://spark.apache.org/docs/1.6.3/tuning.html 搜索 spspark.memory.fraction
http://spark.apache.org/docs/latest/tuning.html
剩下的40%用于用户的数据结构、Spark的元数据和预留防止OOM的内存。
pspark.memory.storageFraction
表示Storage内存在Execution和Storage内存之和的占比。设置这个参数可避免缓冲的数据块被清理出
内存。
spark 1.6.3
Memory usage in Spark largely falls under one of two categories: execution and storage. Execution memory refers to that used for computation in shuffles, joins, sorts and aggregations, while storage memory refers to that used for caching and propagating internal data across the cluster. In Spark, execution and storage share a unified region (M). When no execution memory is used, storage can acquire all the available memory and vice versa. Execution may evict storage if necessary, but only until total storage memory usage falls under a certain threshold (R). In other words, R describes a subregion within M where cached blocks are never evicted. Storage may not evict execution due to complexities in implementation.
This design ensures several desirable properties. First, applications that do not use caching can use the entire space for execution, obviating unnecessary disk spills. Second, applications that do use caching can reserve a minimum storage space (R) where their data blocks are immune to being evicted. Lastly, this approach provides reasonable out-of-the-box performance for a variety of workloads without requiring user expertise of how memory is divided internally.
Although there are two relevant configurations, the typical user should not need to adjust them as the default values are applicable to most workloads:
spark.memory.fractionexpresses the size ofMas a fraction of the (JVM heap space - 300MB) (default 0.75). The rest of the space (25%) is reserved for user data structures, internal metadata in Spark, and safeguarding against OOM errors in the case of sparse and unusually large records.spark.memory.storageFractionexpresses the size ofRas a fraction ofM(default 0.5).Ris the storage space withinMwhere cached blocks immune to being evicted by execution.
内存管理概述
Spark中的内存使用大部分属于两类:执行和存储。执行内存是指用于在混洗,连接,排序和聚合中进行计算的内存,而存储内存指的是用于跨群集缓存和传播内部数据的内存。在Spark中,执行和存储共享统一区域(M)。当不使用执行内存时,存储可以获取所有可用内存,反之亦然。如有必要,执行可能会驱逐存储空间,但只能在总存储内存使用量低于特定阈值(R)时才执行。换句话说,R描述了M缓存块永远不会被驱逐的分区域。由于执行的复杂性,存储可能不会执行。
这种设计确保了几个理想的特性 首先,不使用缓存的应用程序可以使用整个空间执行,避免不必要的磁盘溢出。其次,使用高速缓存的应用程序可以保留最小的存储空间(R),使其数据块不会被驱逐。最后,这种方法为各种工作负载提供了合理的开箱即用性能,而不需要用户在内部划分内存的专业知识。
虽然有两种相关配置,但典型用户不需要调整它们,因为默认值适用于大多数工作负载:
spark.memory.fraction表示M(JVM堆空间 - 300MB)的一部分(默认值为0.75)的大小。其余空间(25%)保留给用户数据结构,Spark中的内部元数据,并在稀疏和异常大的记录情况下防范OOM错误。spark.memory.storageFraction表示大小R为M(默认0.5)的一部分。R是M缓存块不受执行驱逐的缓存块的存储空间。
Spark 2.3
Memory Management Overview
Memory usage in Spark largely falls under one of two categories: execution and storage. Execution memory refers to that used for computation in shuffles, joins, sorts and aggregations, while storage memory refers to that used for caching and propagating internal data across the cluster. In Spark, execution and storage share a unified region (M). When no execution memory is used, storage can acquire all the available memory and vice versa. Execution may evict storage if necessary, but only until total storage memory usage falls under a certain threshold (R). In other words, R describes a subregion within M where cached blocks are never evicted. Storage may not evict execution due to complexities in implementation.
This design ensures several desirable properties. First, applications that do not use caching can use the entire space for execution, obviating unnecessary disk spills. Second, applications that do use caching can reserve a minimum storage space (R) where their data blocks are immune to being evicted. Lastly, this approach provides reasonable out-of-the-box performance for a variety of workloads without requiring user expertise of how memory is divided internally.
Although there are two relevant configurations, the typical user should not need to adjust them as the default values are applicable to most workloads:
spark.memory.fractionexpresses the size ofMas a fraction of the (JVM heap space - 300MB) (default 0.6). The rest of the space (40%) is reserved for user data structures, internal metadata in Spark, and safeguarding against OOM errors in the case of sparse and unusually large records.spark.memory.storageFractionexpresses the size ofRas a fraction ofM(default 0.5).Ris the storage space withinMwhere cached blocks immune to being evicted by execution.
The value of spark.memory.fraction should be set in order to fit this amount of heap space comfortably within the JVM’s old or “tenured” generation. See the discussion of advanced GC tuning below for details.
内存管理概述
Spark中的内存使用大部分属于两类:执行和存储。执行内存是指用于在混洗,连接,排序和聚合中进行计算的内存,而存储内存指的是用于跨群集缓存和传播内部数据的内存。在Spark中,执行和存储共享统一区域(M)。当不使用执行内存时,存储可以获取所有可用内存,反之亦然。如有必要,执行可能会驱逐存储空间,但只能在总存储内存使用量低于特定阈值(R)时才执行。换句话说,R描述了M缓存块永远不会被驱逐的分区域。由于执行的复杂性,存储可能不会执行。
这种设计确保了几个理想的特性 首先,不使用缓存的应用程序可以使用整个空间执行,避免不必要的磁盘溢出。其次,使用高速缓存的应用程序可以保留最小的存储空间(R),使其数据块不会被驱逐。最后,这种方法为各种工作负载提供了合理的开箱即用性能,而不需要用户在内部划分内存的专业知识。
虽然有两种相关配置,但典型用户不需要调整它们,因为默认值适用于大多数工作负载:
spark.memory.fraction表示M(JVM堆空间 - 300MB)的一部分的大小(默认值为0.6)。其余空间(40%)保留用于用户数据结构,Spark中的内部元数据,以及在稀疏和异常大的记录情况下防止OOM错误。spark.memory.storageFraction表示大小R为M(默认0.5)的一部分。R是M缓存块不受执行驱逐的缓存块的存储空间。
spark.memory.fraction为了在JVM的旧时代或“终身”时代中适应这种堆空间,应该设置它的价值。有关详细信息,请参阅下面的高级GC调整讨论。
怎么配置呢? 如下
spark-shell \
--master yarn-client \
--num-executors 3 \
--driver-memory 10g \
--executor-memory 3g \
--executor-cores 2 \
--conf spark.yarn.executor.memoryOverhead=1024m
--conf spark.memory.storageFraction=0.5
================= 堆外内存====
堆外内存:除了前面介绍的Executor的堆外内存,Driver、ApplicationMaster进程也有堆外内存。
Driver的堆外内存设置
spark.driver.memoryOverhead
默认: MAX(Driver memory * 0.10, 384m)
Application Master的堆外内存设置
spark.yarn.am.memoryOverhead
默认: MAX(AM memory * 0.10, 384m)
Application Master的内存也是--conf参数设置
spark2-shell --master yarn \
--master yarn-client \
--num-executors 4 \
--conf spark.yarn.am.memory=1000m \
--conf spark.yarn.am.memoryOverhead=1000m \
--conf spark.driver.memoryOverhead=1g