Spark运行模式较多,包含但是不止以下
local 就是单机,jobs都在这台机器上运行。
standalone 就是说多台机器组成一个集群,然后jobs可以分在多台机器上运行
yarn 就是说spark程序运行在yarn上(别的应用共享服务器建议用yarn)
client 就是jobs在不同机器运行,然后结果返回到这台机器上。
cluster 就是jobs在不同机器运行,结果返回到集群中的某一台机器上。
这篇文章主要讲Spark on Yarn和StandAlone
Spark on Yarn搭建
1.配置
a)安装Hadoop:需要安装HDFS模块和YARN模块,spark运行时要把jar包放到HDFS上。
b)安装Spark:不需要启动Spark集群,在client节点配置中spark-env.sh添加JDK和HADOOP_CONF_DIR目录,Spark程序将作 为yarn的客户端用户提交任务。其中HADOOP_CONF_DIR是Saprk On Yarn与StandAlone重要区别
export JAVA_HOME=/usr/local/jdk1.8.0_161
export HADOOP_CONF_DIR=/usr/local/src/hadoop-2.6.1/etc/hadoopc)启动HDFS和YARN(不用启动master和woker)
2.yarn-client和yarn-cluster提交任务的方式
client模式:
./bin/spark-submit \
--master yarn \
--driver-memory 1g \
--executor-memory 1g \
--executor-cores 2 \
--class org.apache.spark.examples.SparkPi \
examples/jars/spark-examples_2.11-2.0.2.jar \
1000
--master yarn(默认client模式) 等价于 yarn-client(已弃用)和--master yarn --deploy-mode client
spark-shell和pypark必须使用yarn-client模式,因为这是交互式命令,Driver需运行在本地。
cluster模式:
./bin/spark-submit \
--master yarn \
--deploy-mode cluster \
--class org.apache.spark.examples.SparkPi \
examples/jars/spark-examples_2.11-2.0.2.jar \
1000
3.两种模式的区别
cluster模式:Driver程序在YARN中运行,Driver所在的机器是随机的,应用的运行结果不能在客户端显示只能通过yarn查看,所以最好运行那些将结果最终保存在外部存储介质(如HDFS、Redis、Mysql)而非stdout输出的应用程序,客户端的终端显示的仅是作为YARN的job的简单运行状况。
client模式:Driver运行在Client上,应用程序运行结果会在客户端显示,所有适合运行结果有输出的应用程序(如spark-shell)
4.原理
cluster模式:
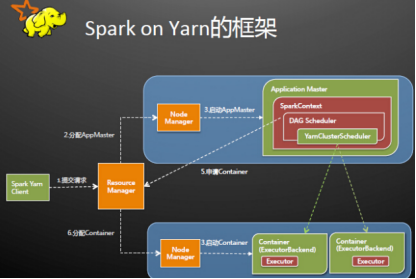
Spark Driver首先作为一个ApplicationMaster在YARN集群中启动,客户端提交给ResourceManager的每一个job都会在集群的NodeManager节点上分配一个唯一的ApplicationMaster,由该ApplicationMaster管理全生命周期的应用。具体过程:
1. 由client向ResourceManager提交请求,并上传jar到HDFS上
这期间包括四个步骤:
a).连接到RM
b).从RM的ASM(ApplicationsManager )中获得metric、queue和resource等信息。
c). upload app jar and spark-assembly jar
d).设置运行环境和container上下文(launch-container.sh等脚本)
2. ResouceManager向NodeManager申请资源,创建Spark ApplicationMaster(每个SparkContext都有一个ApplicationMaster)
3. NodeManager启动ApplicationMaster,并向ResourceManager AsM注册
4. ApplicationMaster从HDFS中找到jar文件,启动SparkContext、DAGscheduler和YARN Cluster Scheduler
5. ResourceManager向ResourceManager AsM注册申请container资源
6. ResourceManager通知NodeManager分配Container,这时可以收到来自ASM关于container的报告。(每个container对应一个executor)
7. Spark ApplicationMaster直接和container(executor)进行交互,完成这个分布式任务。
client模式:
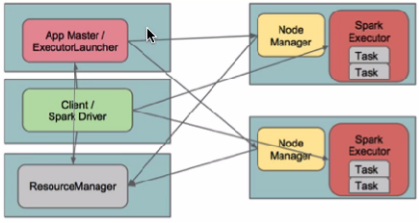
在client模式下,Driver运行在Client上,通过ApplicationMaster向RM获取资源。本地Driver负责与所有的executor container进行交互,并将最后的结果汇总。结束掉终端,相当于kill掉这个spark应用。一般来说,如果运行的结果仅仅返回到terminal上时需要配置这个。
客户端的Driver将应用提交给Yarn后,Yarn会先后启动ApplicationMaster和executor,另外ApplicationMaster和executor都 是装载在container里运行,container默认的内存是1G,ApplicationMaster分配的内存是driver- memory,executor分配的内存是executor-memory。同时,因为Driver在客户端,所以程序的运行结果可以在客户端显 示,Driver以进程名为SparkSubmit的形式存在。
Spark程序提交四种方式
提交方式分为Standalone(client\cluster)和Yarn(client\cluster) 四种。
首先编写好我们的wordcount程序然后打成jar包,传到我们的服务器上。
object Wordcount {
def main(args:Array[String]): Unit ={
val conf = new SparkConf().setAppName("WordCount")
val sc = new SparkContext(conf)
val inputpath = args(0)
val lines = sc.textFile(inputpath)
val words = lines.flatMap(line=>line.split(" "))
words.count()
val wordcounts = words.map(word=>(word,1)).reduceByKey(_+_)
wordcounts.saveAsTextFile(args(1))
}
}
我们需要使用spark的bin/spark-submit来提交我们的程序,具体参数使用help命令查看:bin/spark-submit --help

spark-submit
Standalone模式 client
bin/spark-submit \
--class cn.lyl.spark.Wordcount \
--master spark://master:7077 \
--executor-memory 1G \
wordcount.jar \
hdfs://master:8020/user/README.txt \
hdfs://master:8020/user/wordcount1

wordcount1文件目录
Standalone模式 cluster
bin/spark-submit \
--class cn.lyl.spark.Wordcount \
--master spark://master:7077 \
--executor-memory 1G \
--deploy-mode cluster \
wordcount.jar \
hdfs://master:8020/user/README.txt \
hdfs://master:8020/user/wordcount2

集群模式下Web监控界面
Yarn模式 client
bin/spark-submit \
--class cn.lyl.spark.Wordcount \
--deploy-mode client \
--master yarn \
--executor-memory 1G \
wordcount.jar \
hdfs://master:8020/user/README.txt \
hdfs://master:8020/user/wordcount3

Yarn Client
Yarn cluster
bin/spark-submit \
--class cn.lyl.spark.Wordcount \
--deploy-mode cluster \
--master yarn \
--executor-memory 1G \
wordcount.jar \
hdfs://master:8020/user/README.txt \
hdfs://master:8020/user/wordcount4