已经搭建好Hadoop2.6了,现在准备在yarn上搭建spark。
一.安装Scala
1.解压
tar -xvzf scala-2.10.6.tgz
2.添加环境变量
vim ~/.bashrc
export SCALA_HOME=/usr/local/src/scala-2.10.6
export PATH=$PATH:$SCALA_HOME/bin
source一下,查看是否安装成功
二.安装spark

1.下载spark到指定目录
wget https://archive.apache.org/dist/spark/spark-1.6.1/spark-1.6.1-bin-hadoop2.6.tgz /usr/local/src
2.解压:
tar -xvzf scala-2.10.6.tgz
3.配置spark
vim ~/.bashrc
添加
export SPARK_HOME=/usr/local/src/spark-1.6.1-bin-hadoop2.6
export PATH=$PATH:$SCALA_HOME/bin:$SPARK_HOME/bin
cd 到spark目录的conf文件夹
cp spark-env.sh.template spark-env.sh
vim spark-env.sh
在末尾添加
export JAVA_HOME=/usr/local/src/jdk1.6.0_45 #Java环境变量
export SCALA_HOME=/usr/local/src/scala-2.10.6 #SCALA环境变量
export SPARK_WORKING_MEMORY=1g #每一个worker节点上可用的最大内存
export SPARK_MASTER_IP=master #驱动器节点IP
export HADOOP_HOME=/usr/local/src/hadoop-2.6.1 #Hadoop路径
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop #Hadoop配置目录
export SPARK_CLASSPATH=/usr/local/src/spark-1.6.1-bin-hadoop2.6/libext #把MySQL驱动jar包放里面这里记得把MySQL驱动放到libext目录里面,不然启动会报错。
配置slave
cp slaves.template slaves
vim slaves
末尾添加
slave1
slave2三验证是否成功
到spark安装目录的sbin文件夹下面
./start-all.sh
或者输入spark-shell
如果遇到报错:Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/spark/launcher/Main
是因为项目缺少slf4j-api.jar和slf4j-log4j12.jar这两个jar包导致的错误
在spark-env.sh文件中添加:
export SPARK_DIST_CLASSPATH=$(${HADOOP_HOME}/bin/hadoop classpath)如果还是不行,可能是java版本不对,换成1.7以上的版本,比如我
于是我就换成了JDK1.7版本。。
接着输入spark-shell,终于成功了
四、启动任务
spark有几种启动模式,通过--master来指定,具体可以通过spark-shell --help获得帮助,我们现在通过yarn模式启动。
spark-shell --master spark://master:7077
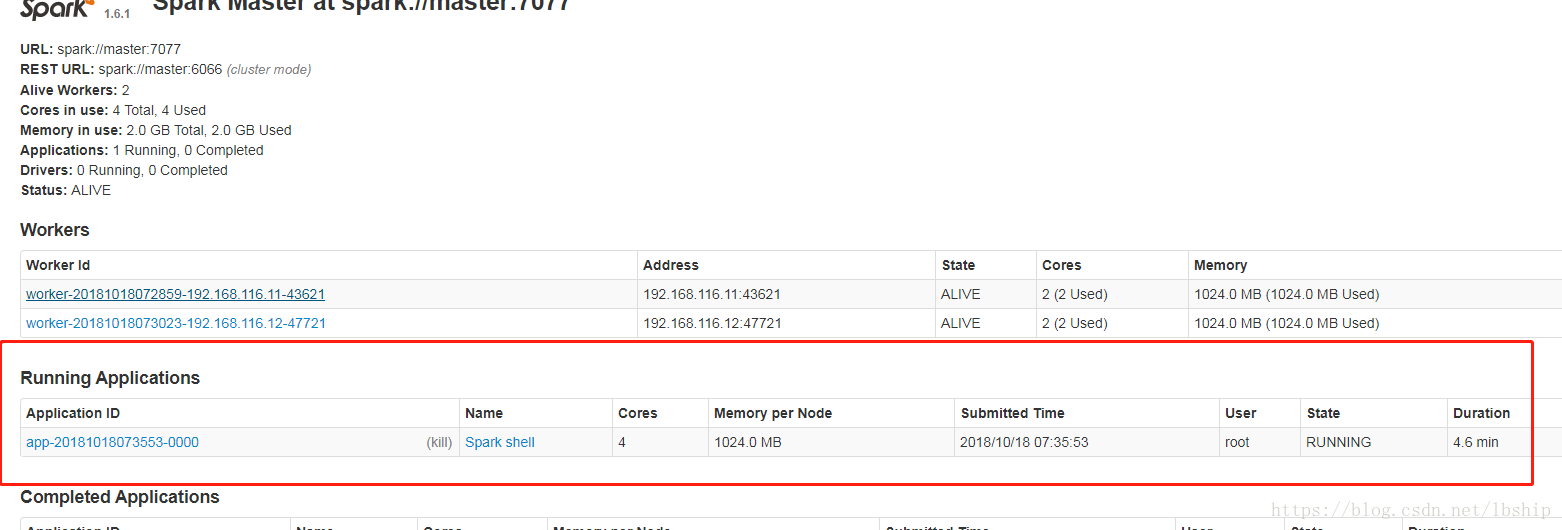
到http://192.168.116.10:8080/去 查看
可以看到增加了Running Applications这一行
五、连接Hive
把安装好的hive里面的hive-site.xml复制到spark的conf目录下:
cp hive-site.xml /usr/local/src/spark-1.6.1-bin-hadoop2.6/conf
启动
spark-shell --master local[2] --jars /usr/local/src/spark-1.6.1-bin-hadoop2.6/libext/com.mysql.jdbc.Driver.jar
import org.apache.spark.sql.hive.HiveContext
val hiveContext = new HiveContext(sc)
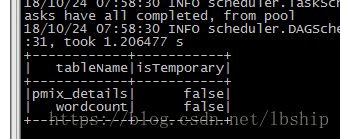
hiveContext.sql("show tables").show()
可以发现已经可以看到hive里面的表了
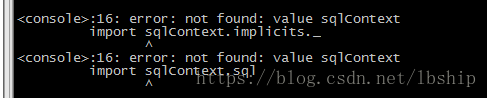
如果遇到报错,是因为没有指定MySQL的Jar包导致的,所以我在启动spark-shell的时候加入了--jars包来启动
<console>:16: error: not found: value sqlContext
import sqlContext.implicits._
^
<console>:16: error: not found: value sqlContext
import sqlContext.sql
这样使用SQL有点麻烦,接下来测试跟hive一样的方式,直接使用SQL,实际上就是把spark-shell改成spark-sql
spark-sql --master local[2] --jars /usr/local/src/spark-1.6.1-bin-hadoop2.6/libext/com.mysql.jdbc.Driver.jar
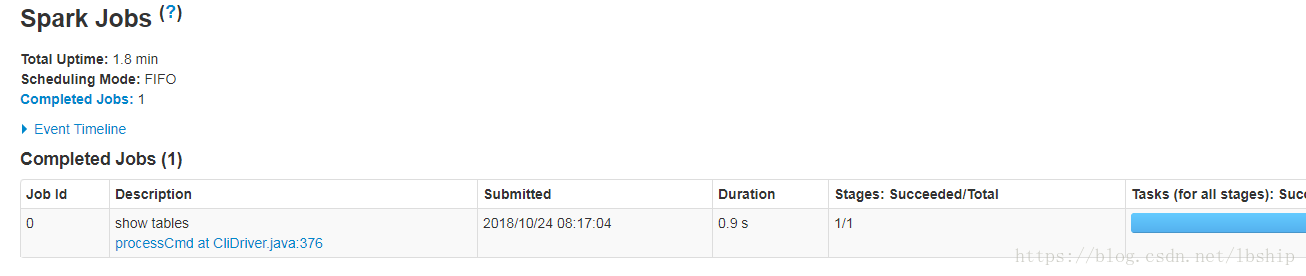
可以到http://192.168.116.10:4040/jobs/来查看任务的运行情况。
六、使用thriftserver和beeline
1.到spark安装目录的sbin目录底下启动服务:
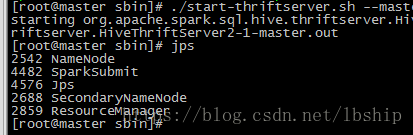
./start-thriftserver.sh --master local[2] --jars /usr/local/src/spark-1.6.1-bin-hadoop2.6/libext/com.mysql.jdbc.Driver.jar
然后通过jps或者jps-m可以看到多了一个sparksubmit这个任务就成功了。这个thriftserver默认端口是10000,可以在启动时候出入参数--hiveconf来修改端口
2.通过beeline来连接
到spark安装目录的bin文件夹下:
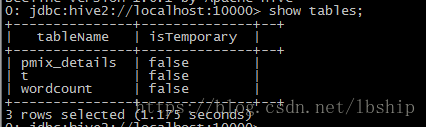
./beeline -u jdbc:hive2://localhost:10000 -n master (这里的-n是当前 机器登录名字不是用户名,-u表示url)
可以看到连接的相关信息

输入show tables可以看到表信息
使用thriftserver和使用spark-shell的区别好处是:
1.不论多少客户端(beeline/code)连接,都只有一个spark application
2.可以不同客户端之间可以数据共享。