决策树——非线性回归与分类
决策树简介
决策树就是做出一个树状决策,就像猜猜看(Twenty Questions)的游戏。一个玩家(先知)选择一种常见物品,但是事先不能透露给其他玩家(提问者)。提问者最多问20个问题,而先知只能回答:是,否,可能三种答案。提问者的提问会根据先知的回答越来越具体,多个问题问完后,提问者的决策就形成了一颗决策树。决策树的分支由可以猜出响应变量值的最短的解释变量序列构成。因此,在猜猜看游戏中,提问者和先知对训练集的解释变量和响应变量都很了解,但是只有先知知道测试集的响应变量值。
信息熵
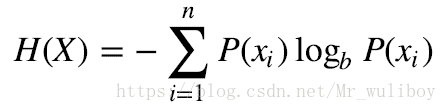
信息增益:
信息增益=划分前的信息熵-划分后的加权信息熵均值。
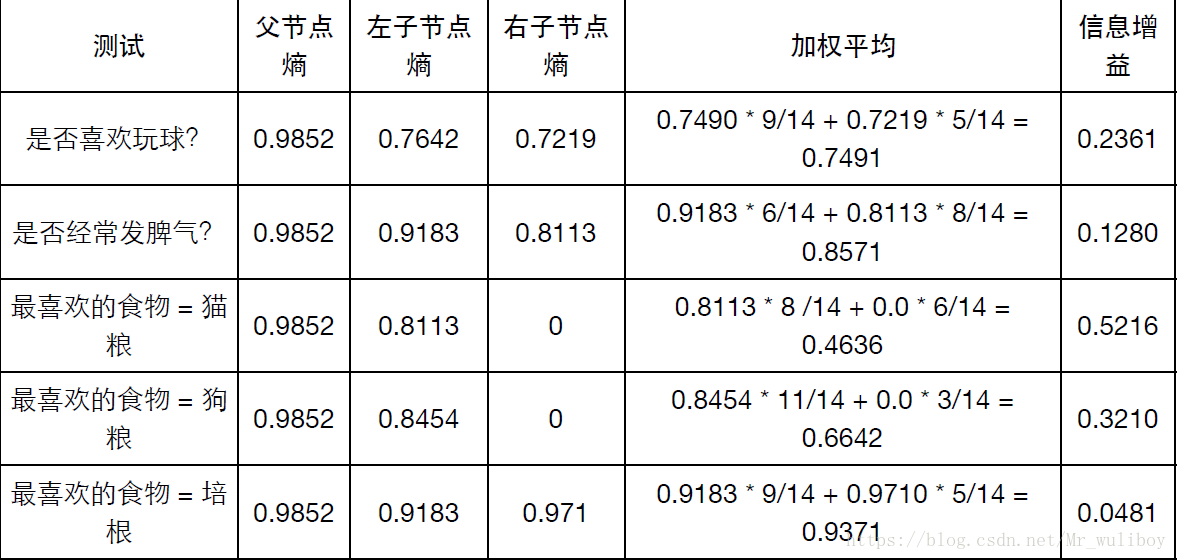
上表中的信息增益 = 父节点熵-加权平均。(信息增益越大表示该方法越好。)
scikit-learn的决策树实现算法是CART(Classification and Regression Trees,分类与回归树)算法,CART也是一种支持修剪的学习算法。
基尼不纯度
基尼不纯度格式如下:
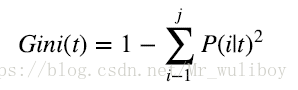
其中, 是类型的数量, 是节点样本的子集,p(i|t)表示的是从节点子集中选择一个类型的概率。
scikit-learn研究决策树的算法,既支持信息增益,也支持基尼不纯度。到底用哪种方法并没有规定,实际上,它们产生的结果类似。一般的决策树都是两个都用,比较一下结果,哪个好用哪个。
scikit-learn决策树
我们用互联网广告数据集(InternetAdvertisements Data Set) (http://archive.ics.uci.edu/ml/datasets/Internet+Advertisements)来实现分类器
代码如下:
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
from sklearn.cross_validation import train_test_split
from sklearn.metrics import classification_report
from sklearn.pipeline import Pipeline
from sklearn.grid_search import GridSearchCV
import zipfile
# 压缩节省空间
z = zipfile.ZipFile('D:\\dateset\\ad.zip')
df = pd.read_csv(z.open(z.namelist()[0]), header=None, low_memory=False)
explanatory_variable_columns = set(df.columns.values)
response_variable_column = df[len(df.columns.values)-1]
# The last column describes the targets
explanatory_variable_columns.remove(len(df.columns.values)-1)
y = [1 if e == 'ad.' else 0 for e in response_variable_column]
X = df.loc[:, list(explanatory_variable_columns)]#按列属性名输出处理后的数据赋值给X
X.replace(to_replace=' *\?', value=-1, regex=True, inplace=True)
X_train, X_test, y_train, y_test = train_test_split(X, y)
pipeline = Pipeline([#管道机制,如果有多个分类器的参数需要测试,则只需将多个分类器在pipeline中定义,训练的时候即可一次性同时训练。
('clf', DecisionTreeClassifier(criterion='entropy'))
])
parameters = {
'clf__max_depth': (150, 155, 160),
'clf__min_samples_split': (1.0, 2, 3),
'clf__min_samples_leaf': (1, 2, 3)
}
grid_search = GridSearchCV(pipeline, parameters, n_jobs=-1, verbose=1, scoring='f1')
grid_search.fit(X_train, y_train)
print('最佳效果:%0.3f' % grid_search.best_score_)
print('最优参数:')
best_parameters = grid_search.best_estimator_.get_params()
for param_name in sorted(parameters.keys()):
print('\t%s: %r' % (param_name, best_parameters[param_name]))
predictions = grid_search.predict(X_test)
print(classification_report(y_test, predictions))
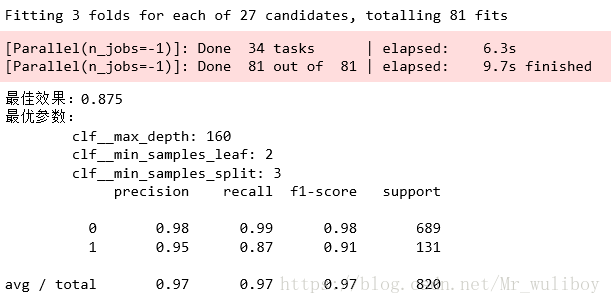
输出结果如下:
决策树集成
集成学习方法将一堆模型组合起来使用,比单个模型可以获取更好的效果。随机森林(randomforest)是一种随机选取训练集解释变量的子集进行训练,获得一系列决策树的集合的方法。随机森林通常用其决策树集合里每个决策树的预测结果的均值或众数作为最终预测值。scikit-learn里的随机森林使用均值作为预测值。下面我们用随机森林升级我们的广告屏蔽程序。把前面用的DecisionTreeClassifier替换成RandomForestClassifier就可以了。和前面一样,我们仍然用网格搜索来探索最优超参数。
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.cross_validation import train_test_split
from sklearn.metrics import classification_report
from sklearn.pipeline import Pipeline
from sklearn.grid_search import GridSearchCV
import zipfile
# 压缩节省空间
z = zipfile.ZipFile('D:\\dateset\\ad.zip')
df = pd.read_csv(z.open(z.namelist()[0]), header=None, low_memory=False)
explanatory_variable_columns = set(df.columns.values)
response_variable_column = df[len(df.columns.values)-1]
# The last column describes the targets
explanatory_variable_columns.remove(len(df.columns.values)-1)
y = [1 if e == 'ad.' else 0 for e in response_variable_column]
X = df.loc[:, list(explanatory_variable_columns)]
X.replace(to_replace=' *\?', value=-1, regex=True, inplace=True)
X_train, X_test, y_train, y_test = train_test_split(X, y)
pipeline = Pipeline([
('clf', RandomForestClassifier(criterion='entropy'))
])
parameters = {
'clf__n_estimators': (5, 10, 20, 50),
'clf__max_depth': (50, 150, 250),
'clf__min_samples_split': (1.0, 2, 3),
'clf__min_samples_leaf': (1, 2, 3)
}
grid_search = GridSearchCV(pipeline, parameters, n_jobs=-1, verbose=1, scoring='f1')
grid_search.fit(X_train, y_train)
print('最佳效果:%0.3f' % grid_search.best_score_)
print('最优参数:')
best_parameters = grid_search.best_estimator_.get_params()
for param_name in sorted(parameters.keys()):
print('\t%s: %r' % (param_name, best_parameters[param_name]))
predictions = grid_search.predict(X_test)
print(classification_report(y_test, predictions))
训练结果如下:
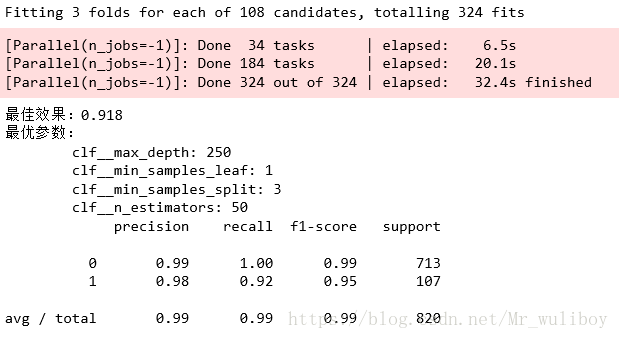
从结果可以看出,随机森林算法得出来的结果要明显好于单一决策树算法的结果。