特征提取与处理
分类变量特征提取
分类变量通常用独热编码(One-of-K or One-Hot Encoding),通过二进制数来表示每个解释变量的特征。
scikit-learn里有DictVectorizer类可以用来表示分类特征:
例如:
from sklearn.feature_extraction import DictVectorizer
onehot_encoder = DictVectorizer()
instances = [{'city': 'New York'},{'city': 'San Francisco'}, {'city': 'Chapel Hill'}]
print(onehot_encoder.fit_transform(instances).toarray())
输出结果为:
[[0. 1. 0.] [0. 0. 1.] [1. 0. 0.]]
文字特征提取
最常用的文字表示方法:词库模型(Bag-of-words model)。
对于一个文档(document),忽略其词序和语法,句法,将其仅仅看做是一个词集合,或者说是词的一个组合,文档中每个词的出现都是独立的,不依赖于其他词是否出现,或者说当这篇文章的作者在任意一个位置选择一个词汇都不受前面句子的影响而独立选择的。
例如以下文集:
corpus = [
'UNC played Duke in basketball',
'Duke lost the basketball game'
]
文集包括8个词:UNC, played, Duke, in, basketball, lost, the, game,这8个词即可以构成该文集的词汇表。
CountVectorizer类会把文档全部转换成小写,然后将文档词块化(tokenize)。文档词块化是把句子分割成词块(token)或有意义的字母序列的过程。词块大多是单词,但是他们也可能是一些短语,如标点符号和词缀。CountVectorizer类通过正则表达式用空格分割句子,然后抽取长度大于等于2的字母序列。
例如以下代码:
from sklearn.feature_extraction.text import CountVectorizer
corpus = [
'UNC played Duke in basketball',
'Duke lost the basketball game'
]
vectorizer =CountVectorizer()
print(vectorizer.fit_transform(corpus).todense())#将词表全部转为小写,获取词汇表,并转换为向量
print(vectorizer.vocabulary_)#输出词汇表中各个单词以及对应的顺序。
scikit-learn里面的euclidean_distances函数可以计算若干向量的距离
特征向量降维
特征向量降维的一个基本方法是单词全部转换成小写,另一种方法是去掉文集常用词。这里词称为停用词(Stop-word),像a,an,the,助动词do,be,will,介词on,around,beneath等。CountVectorizer类可以通过设置stop_words参数过滤停用词,默认是英语常用的停用词。
例如:
corpus = [
'UNC played Duke in basketball',
'Duke lost the basketball game',
'I ate a sandwich'
]
vectorizer =CountVectorizer(stop_words='english')#过滤停用词
print(vectorizer.fit_transform(corpus).todense())
print(vectorizer.vocabulary_)
词根还原与词形还原
停用词去掉之后,可能还会剩下许多词,还有一种常用的方法就是词根还原(stemming )与词形还原(lemmatization)。
特征向量里面的单词很多都是一个词的不同形式,比如jumping和jumps都是jump的不同形式。词根还原与词形还原就是为了将单词从不同的时态、派生形式还原。
from nltk import word_tokenize
from nltk.stem import PorterStemmer
from nltk.stem.wordnet import WordNetLemmatizer
from nltk import pos_tag
wordnet_tags = ['n', 'v']
corpus = [
'He ate the sandwiches',
'Every sandwich was eaten by him'
]
stemmer = PorterStemmer()#词干提取算法
print('Stemmed:', [[stemmer.stem(token) for token in word_tokenize(document)] for document in corpus])
最后一行中for document in corpus中的document表示的是corpus中的单词,word_tokenize是对句子进行分词,stemmer.stem()是提取单词中的词干。
上述程序运行结果如下所示:
Stemmed: [['He', 'ate', 'the', 'sandwich'], ['everi', 'sandwich', 'wa', 'eaten', 'by', 'him']]
pos_tag(token)该方法是对词进行词性标注。
很多单词可能在两个文档的频率一样,但是两个文档的长度差别很大,一个文档比另一个文档长很多
倍。scikit-learn的TfdfTransformer类可以解决这个问题,默认情况下,TfdfTransformer类用L2范数对特征向量归
一化:
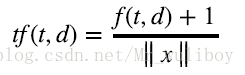
另外,还有对数词频调整方法(logarithmically scaled term frequencies),把词频调整到一个更小的范围,
或者词频放大法(augmented term frequencies),适用于消除较长文档的差异。对数词频公式如
下:
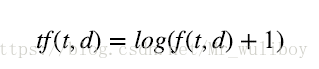
TfdfTransformer类计算对数词频调整时,需要将参数sublinear_tf设置为True
词频放大公式如下:
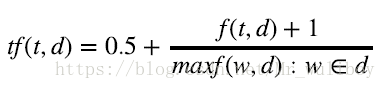
maxf(w,d)是文档d中的最大词频。scikit-learn没有现成可用的词频放大公式,不过通过CountVectorize可以轻松实现。