1.1 总体说明
Scikit-Learn是基于Python的开源机器学习模块,最早由David Cournapeau在2007年发起的,目前也是由社区志愿者进行维护。官方网站是:http://scikit-learn.org/stable/,在上面可以找到相关的资源、模块下载、文档、例程等。
Scikit-Learn的安装需要numpy、scipy、matplotlib等模块,Windows系统可以在http://www.lfd.uci.edu/~gohlke/pythonlibs直接下载编译好的安装包以及依赖包,也可以到网址下载http://sourceforge.jp/projects/sfnet_scikit-learn/.
Scikit-learn的基本功能主要分为六个部分:分类、回归、聚类、数据降维、模型选择、数据预处理。对于具体的机器学习问题,通常可以分为三个步骤,数据准备与预处理,模型选择与训练,模型验证与参数调优。
1.2 代表性函数使用介绍
1.加载数据
#coding:utf-8
import numpy as np
import urllib
url = 'http://archive.ics.uci.edu/ml/machine-learning-databases/00396/Sales_Transactions_Dataset_Weekly.csv'
raw_data = urllib.urlopen(url)
dataset = np.loadtxt(raw_data,delimiter=",",skiprows=1,usecols=(1,2,3,4,5,6,7,8,54))
X = dataset[:,0:7]
Y = dataset[:,8]我们要使用该数据集作为例子,将特征矩阵作为x,目标变量作为y
2.数据归一化
大多数机器学习算法中的梯度方法对于数据的缩放和尺度都是很敏感的,在开始跑算法之前,我们应该进行归一化或标准化的过程,这使得特征数据缩放到0-1范围。scikit-learn提供了归一化的方法:
from sklearn import preprocessing
normalized_X = preprocessing.normalize(X)
standardized_X = preprocessing.scale(X)3.特征选择
在解决一个实际问题的过程中,选择适合的特征或者构建特征的能力特别重要。这称为特征选择或者特征工程。
特征选择是一个很需要创造力的过程,更多的依赖于直觉和专业知识,并且有很多现成的算法来进行特征选择。下面是使用树算法计算特征:
from sklearn import metrics
from sklearn.ensemble import ExtraTreesClassifier
model = ExtraTreesClassifier()
model.fit(X,Y)
print(model.feature_importances_)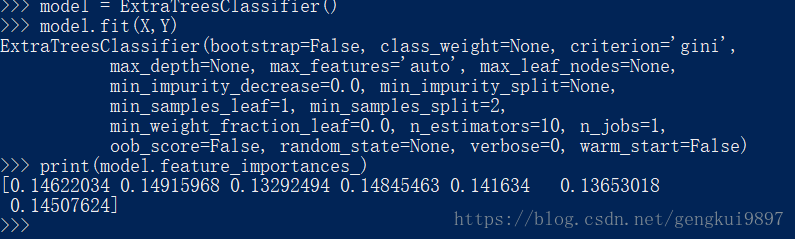
1.3 机器学习算法的使用
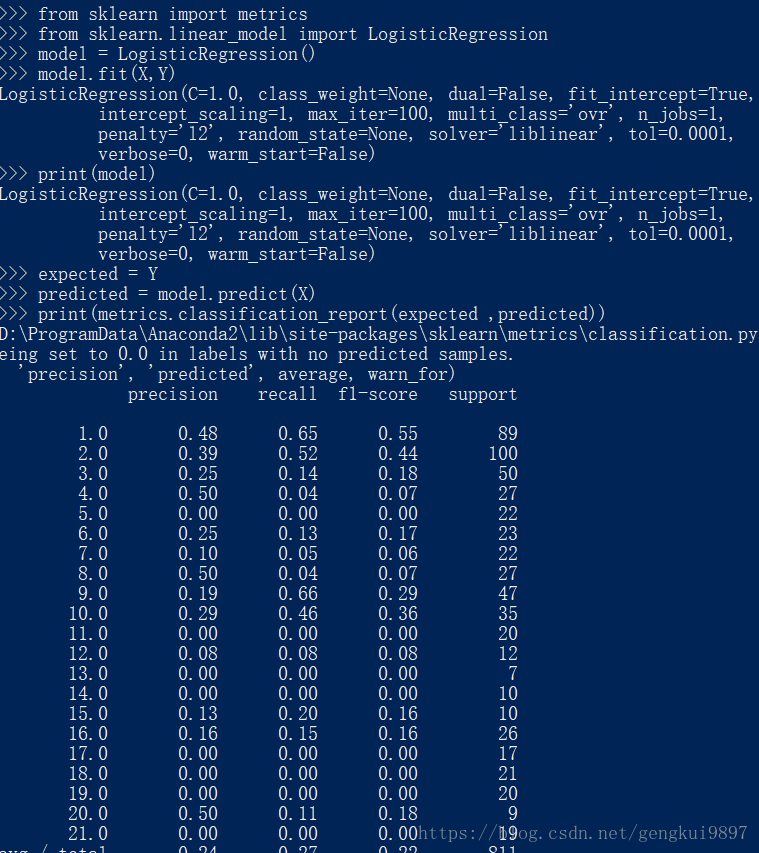
1.逻辑回归
大多数问题都可以归结为二元分类问题。这个算法的优点是可以给出数据所在类别的概率。
from sklearn import metrics
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
model.fit(X,Y)
print(model)
expected = Y
predicted = model.predict(X)
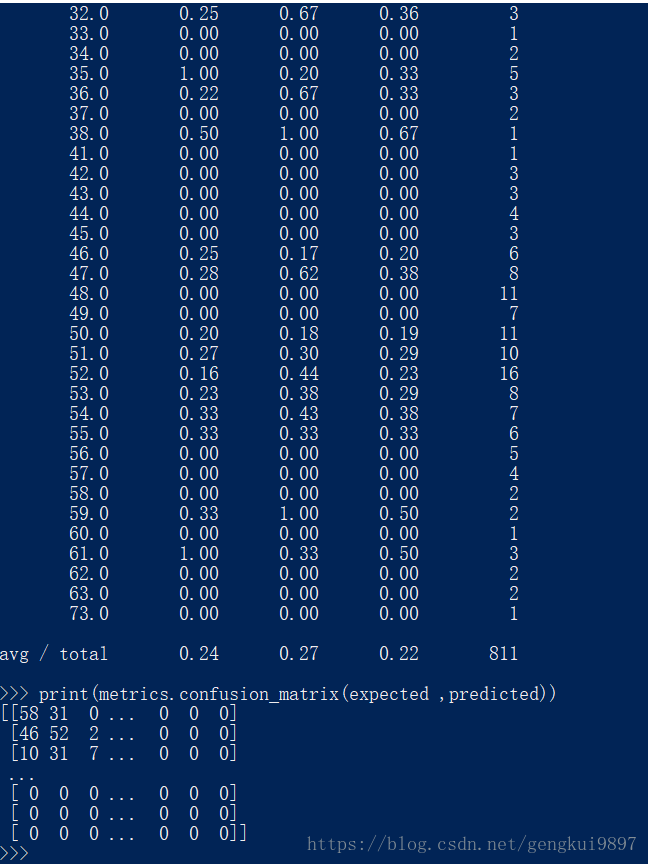
print(metrics.classification_report(expected ,predicted))
print(metrics.confusion_matrix(expected ,predicted))
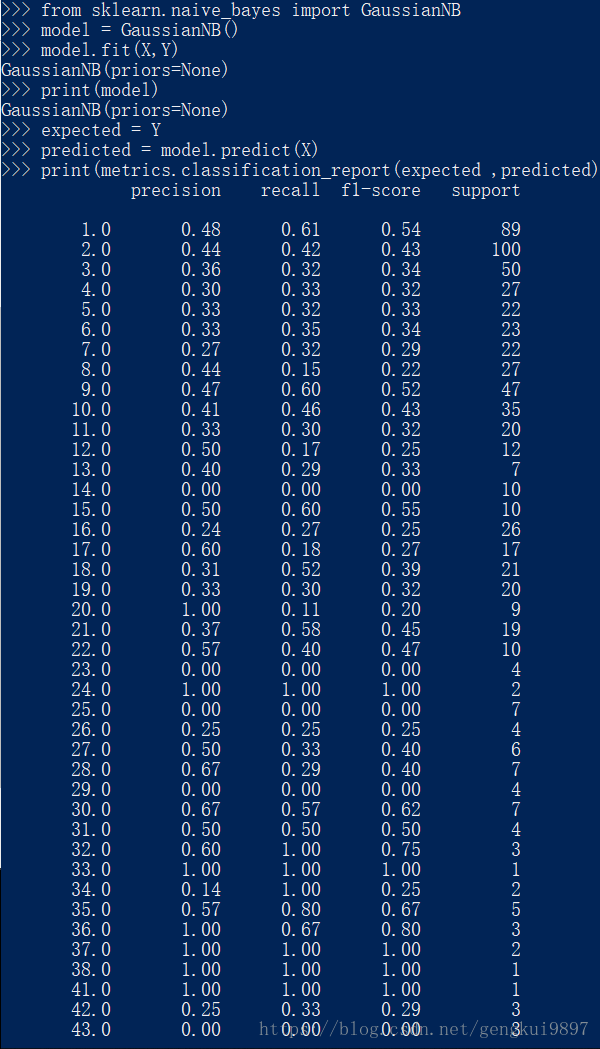
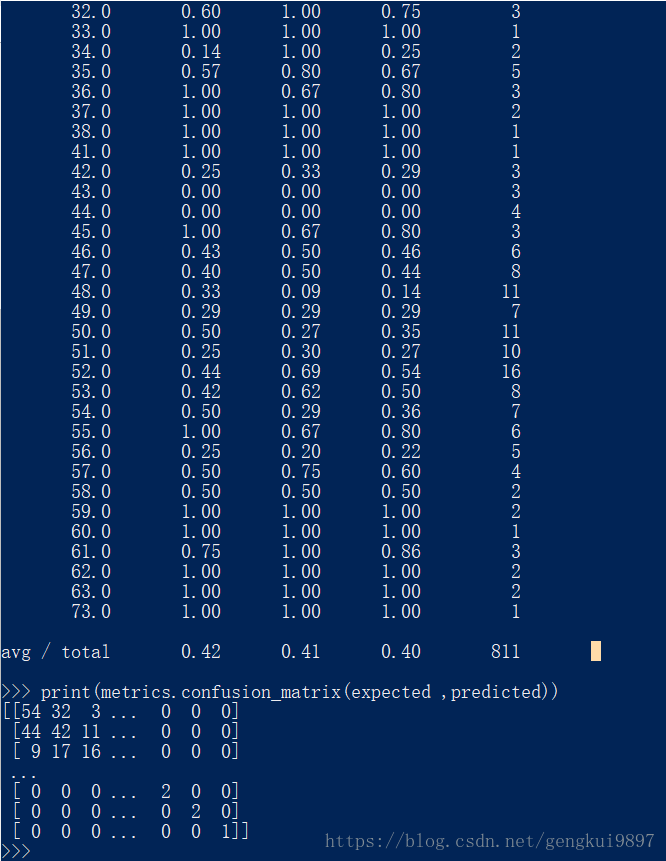
2.朴素贝叶斯
这也是著名的机器学习算法,该方法的任务是还原训练样本数据的分布密度,其在多类别分类中有很好的效果。
from sklearn import metrics
from sklearn.naive_bayes import GaussianNB
model = GaussianNB()
model.fit(X,Y)
print(model)
expected = Y
predicted = model.predict(X)
print(metrics.classification_report(expected ,predicted))
print(metrics.confusion_matrix(expected ,predicted))
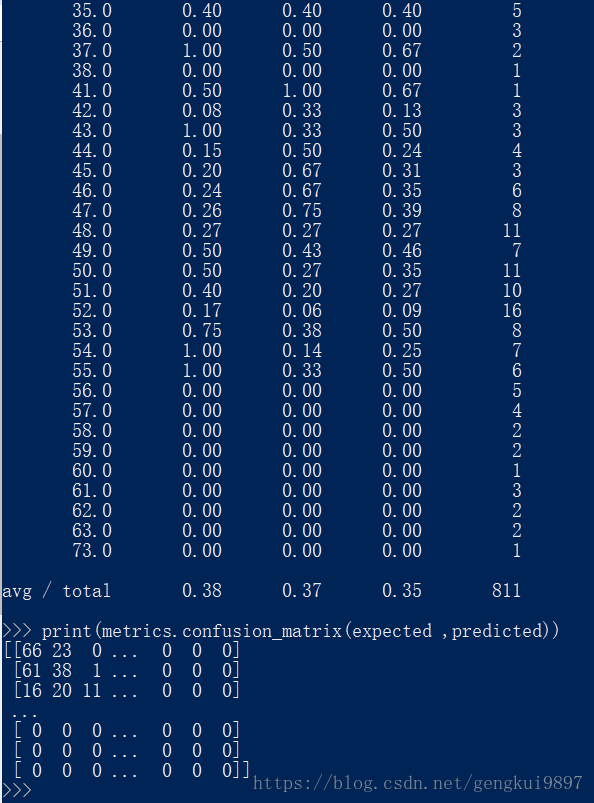
3.k近邻
k近邻算法常常被用作分类算法的一部分,比如可以用它来评估特征,在特征选择上我们可以用到它。
from sklearn import metrics
from sklearn.neighbors import KNeighborsClassifier
model = KNeighborsClassifier()
model.fit(X,Y)
print(model)
expected = Y
predicted = model.predict(X)
print(metrics.classification_report(expected ,predicted))
print(metrics.confusion_matrix(expected ,predicted))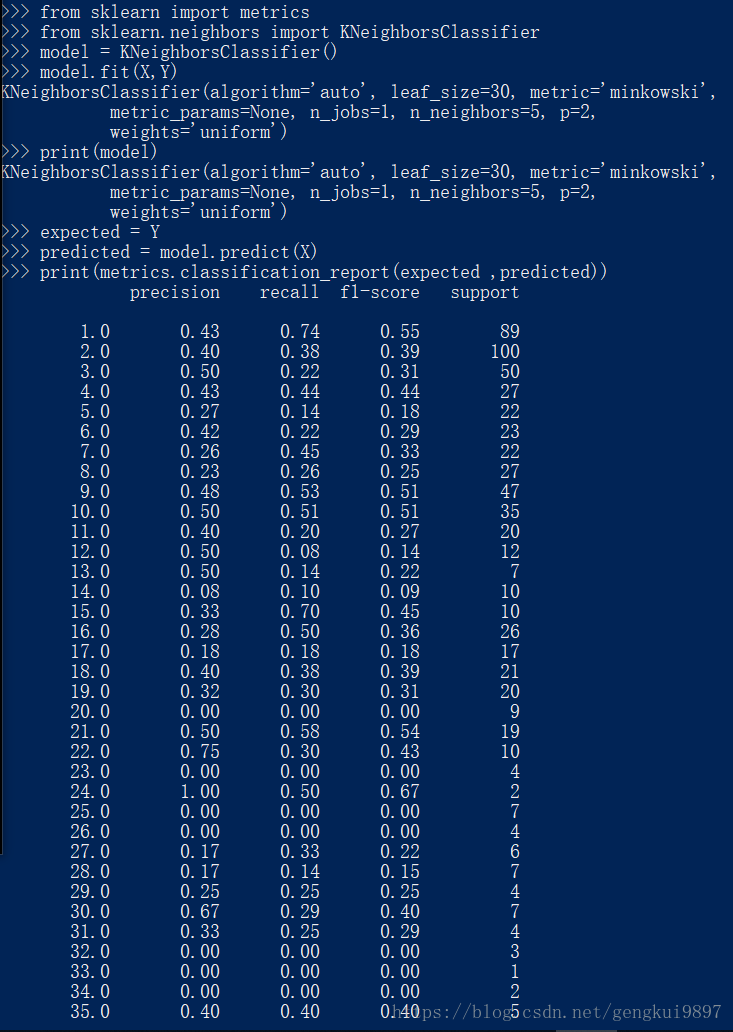
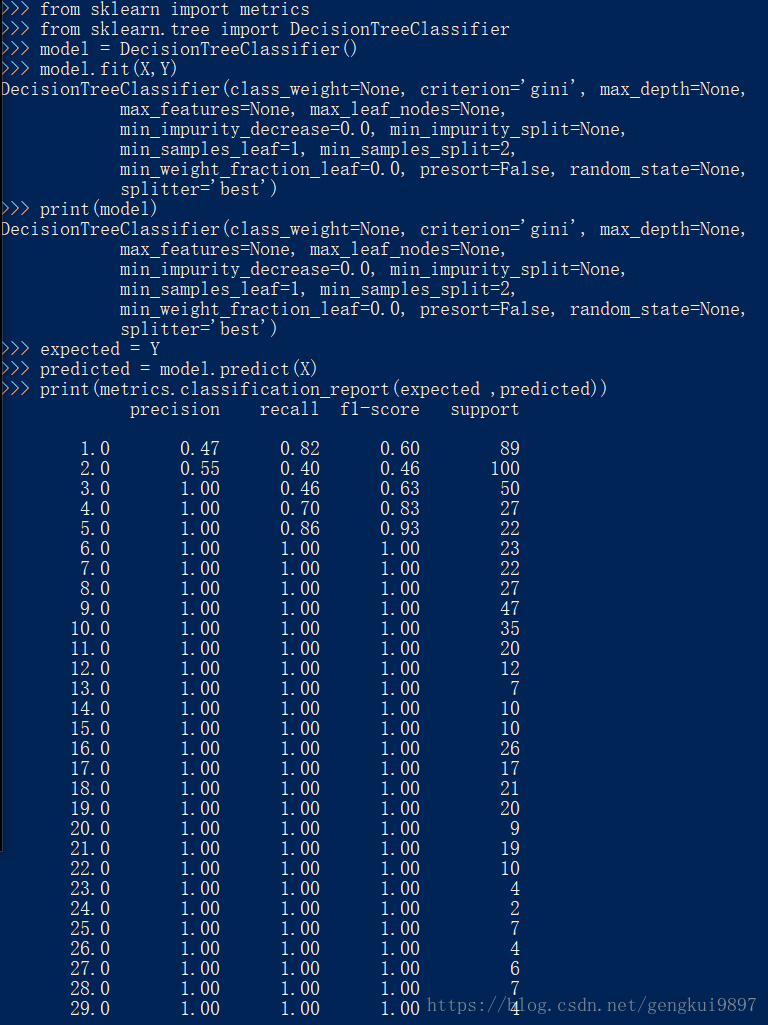
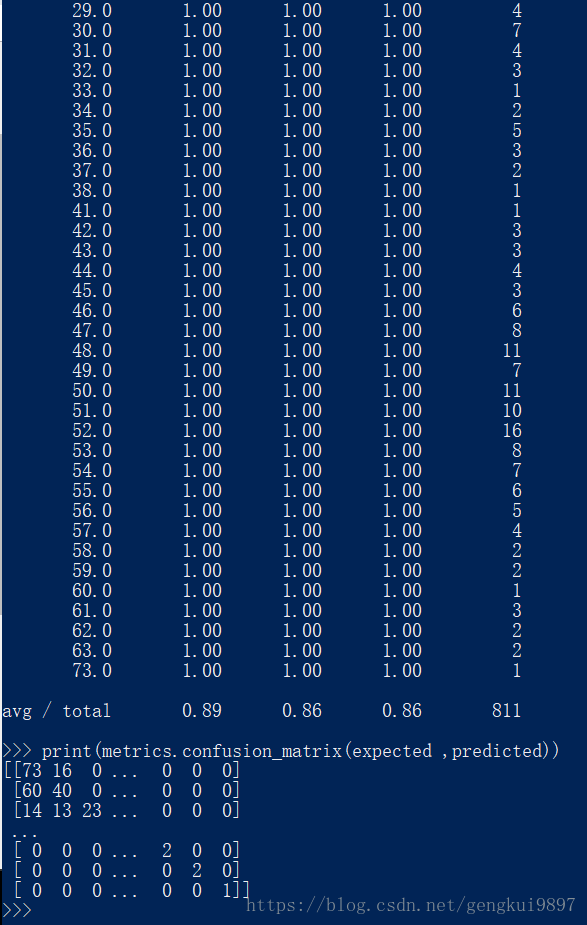
4.决策树
分类与回归树(CART)算法常用于特征含有类别信息的分类或者回归问题,这种方法非常适用于多分类情况。
from sklearn import metrics
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier()
model.fit(X,Y)
print(model)
expected = Y
predicted = model.predict(X)
print(metrics.classification_report(expected ,predicted))
print(metrics.confusion_matrix(expected ,predicted))
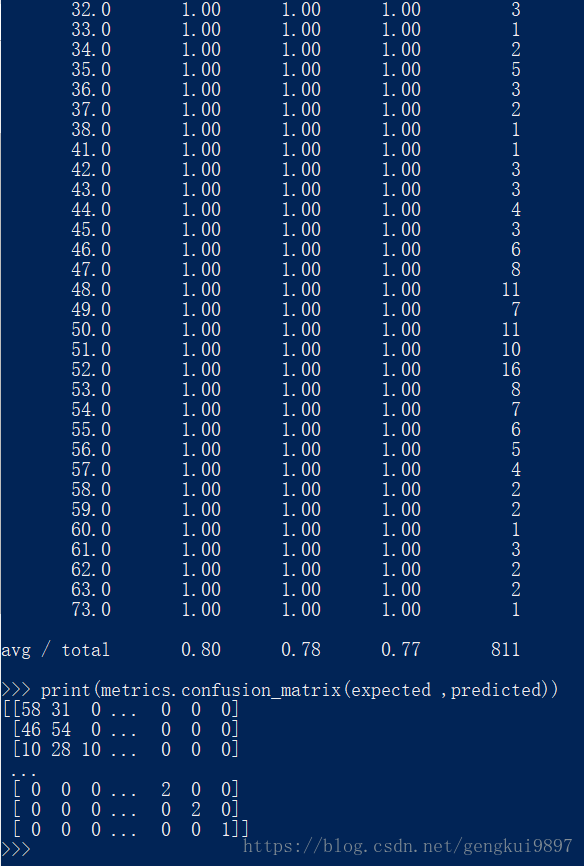
5.支持向量机
SVM是非常流行的机器学习算法,主要用于分类问题,如同逻辑回归问题,它可以使用一对多的方法进行多类别的分类。
from sklearn import metrics
from sklearn.svm import SVC
model = SVC()
model.fit(X,Y)
print(model)
expected = Y
predicted = model.predict(X)
print(metrics.classification_report(expected ,predicted))
print(metrics.confusion_matrix(expected ,predicted))

除了分类和回归算法外,scikit-learn提供了更加复杂的算法,比如聚类算法,还实现了算法组合的技术,如Bagging和Boosting算法。
1.4 如何优化算法参数
一项更加困难的任务是构建一个有效的方法用于选择正确的参数,我们需要使用搜索的方法来确定参数。scikit-learn提供了实现这一目标的函数。
下面例子是一个进行正则参数选择的程序:
import numpy as np
from sklearn.linear_model import Ridge
from sklearn.grid_search import GridSearchCV
alphas = np.array([1,0.1,0.01,0.001,0.0001,0])
model = Ridge()
grid = GridSearchCV(estimator=model,param_grid=dict(alpha=alphas))
grid.fit(X,Y)
print(grid)
print(grid.best_score_)
print(grid.best_estimator_.alpha)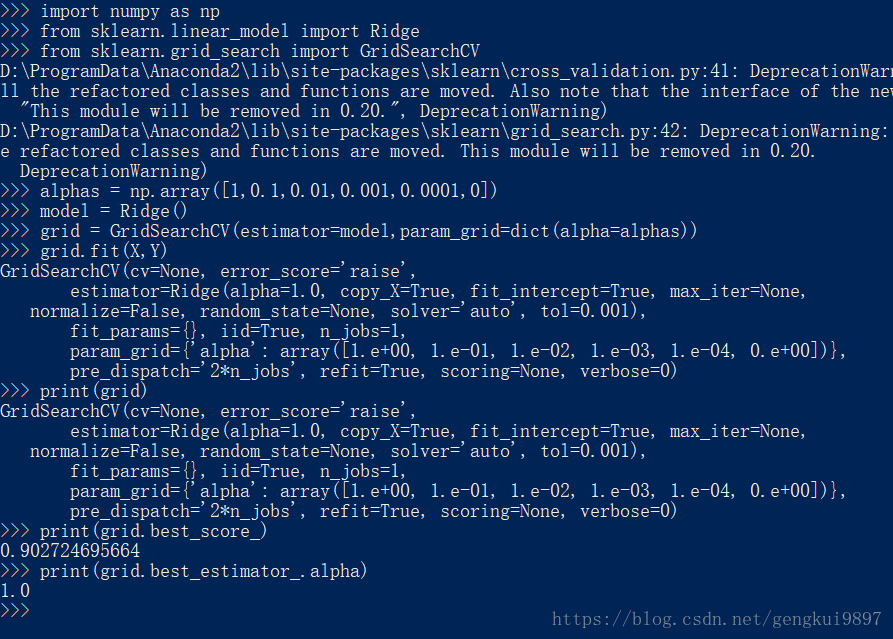
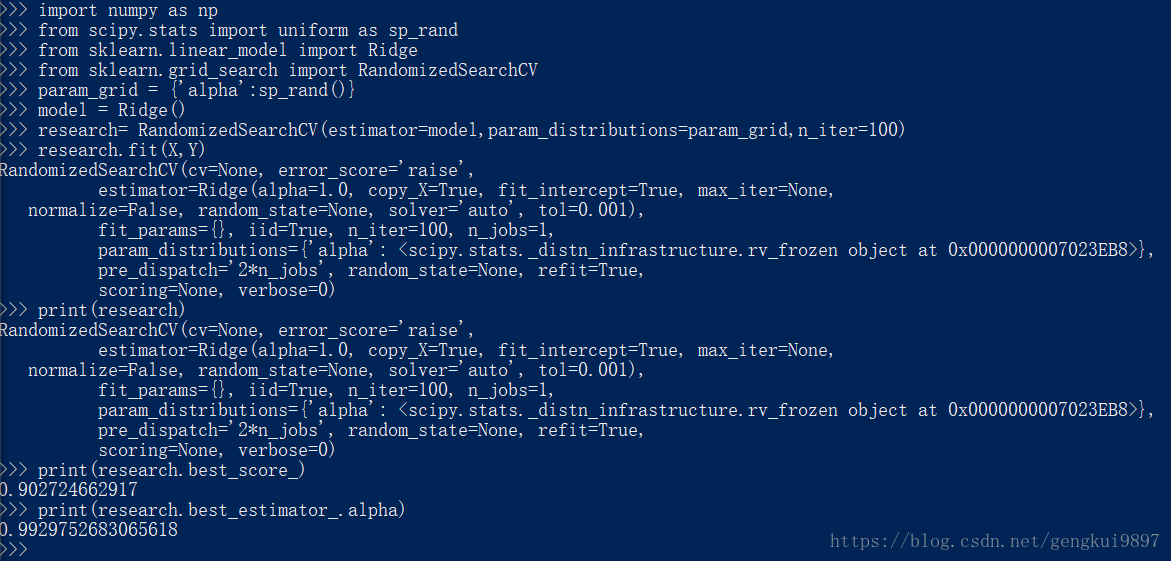
有时随机从给定的区间中选择参数是很有效的方法,然后根据这些参数来评估算法的效果,进而选择最佳的那个。
import numpy as np
from scipy.stats import uniform as sp_rand
from sklearn.linear_model import Ridge
from sklearn.grid_search import RandomizedSearchCV
param_grid = {'alpha':sp_rand()}
model = Ridge()
research= RandomizedSearchCV(estimator=model,param_distributions=param_grid,n_iter=100)
research.fit(X,Y)
print(research)
print(research.best_score_)
print(research.best_estimator_.alpha)