感知器
感知器通常用下面的图形表示:
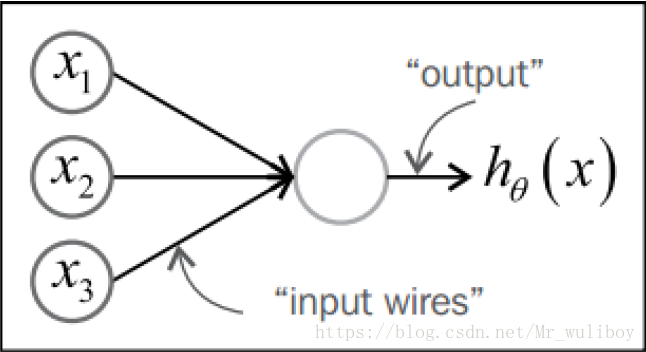
x1, 和是输入单元。每个输入单元分别代表一个特征。感知器通常用另外一个输入单元代表一个常用误差项,但是这个输入单元在图形中通常被忽略了。中间的圆圈是一个计算单元,类似神经元的细胞核。连接输入单元和计算单元的边类似于树突。每条边是一个权重,或者是一个参数。参数容易解释,如果某个解释变量与阳性类型(positive class)相关,其权重为正,某个解释变量与阴性类型(negative class)相关,其权重为负。连接计算单元和输出单元的边类似轴突。
激励函数
感知器通过使用激励函数(activation function )处理解释变量和模型参数的线性组合对样本分类,计算公式如下所示。解释变量和模型参数的线性组合有时也称为感知器的预激励(preactivation)。
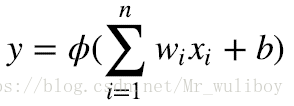
其中, 是模型参数, 是常误差项, 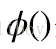
常用的激励函数:
1:阶跃函数:
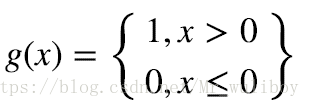
2:逻辑S形(logistic sigmoid )激励函数:
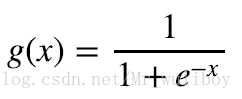
感知器解决文档分类
scikit-learn提供了感知器功能。和我们用过的其他功能类似,Perceptron类的构造器接受超参数设置。Perceptron类fit_transform()和predict()方法。Perceptron类还提供了partial_fit()方法,允许分类器训练流式数据(streaming data)并做出预测。
from sklearn.datasets import fetch_20newsgroups
from sklearn.metrics import f1_score, classification_report
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import Perceptron
categories = ['rec.sport.hockey', 'rec.sport.baseball', 'rec.autos']
newsgroups_train = fetch_20newsgroups(subset='train', categories=categori
es, remove=('headers', 'footers', 'quotes'))
newsgroups_test = fetch_20newsgroups(subset='test', categories=categories
, remove=('headers', 'footers', 'quotes'))
vectorizer = TfidfVectorizer()
X_train = vectorizer.fit_transform(newsgroups_train.data)
X_test = vectorizer.transform(newsgroups_test.data)
classifier = Perceptron(n_iter=100, eta0=0.1)
classifier.fit_transform(X_train, newsgroups_train.target)
predictions = classifier.predict(X_test)
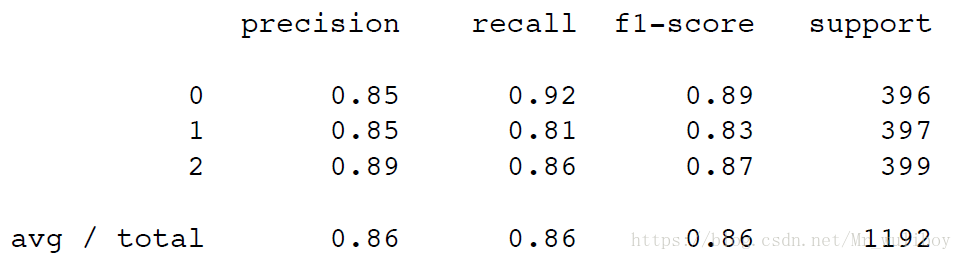
print(classification_report(newsgroups_test.target, predictions))
输出结果如下: