一、系统聚类
- 选中系统聚类并把变量移入变量框内,聚类选择按照个案聚类
在Display栏中选择Statistics和Plots复选框,这样在结果输出窗口中可以同时得到聚类结果统计量和统计图。
选中绘图中的谱系图
单击保存选项卡,方案范围选择2到4,显示分为2、3和4类时的结果。
得到的谱系图如下所示:
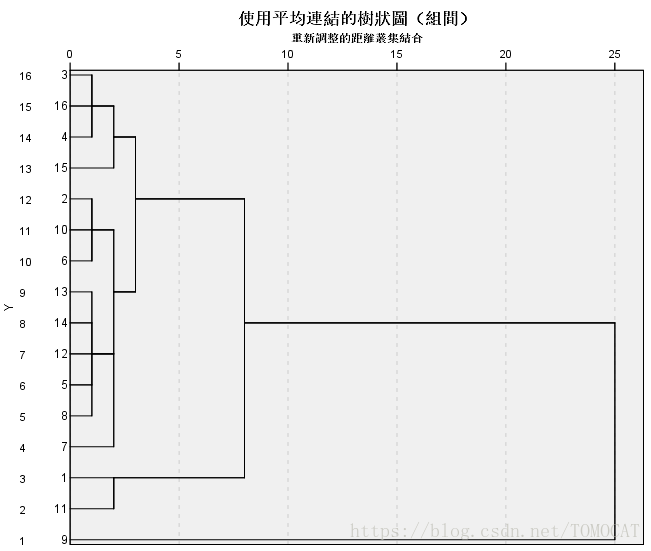
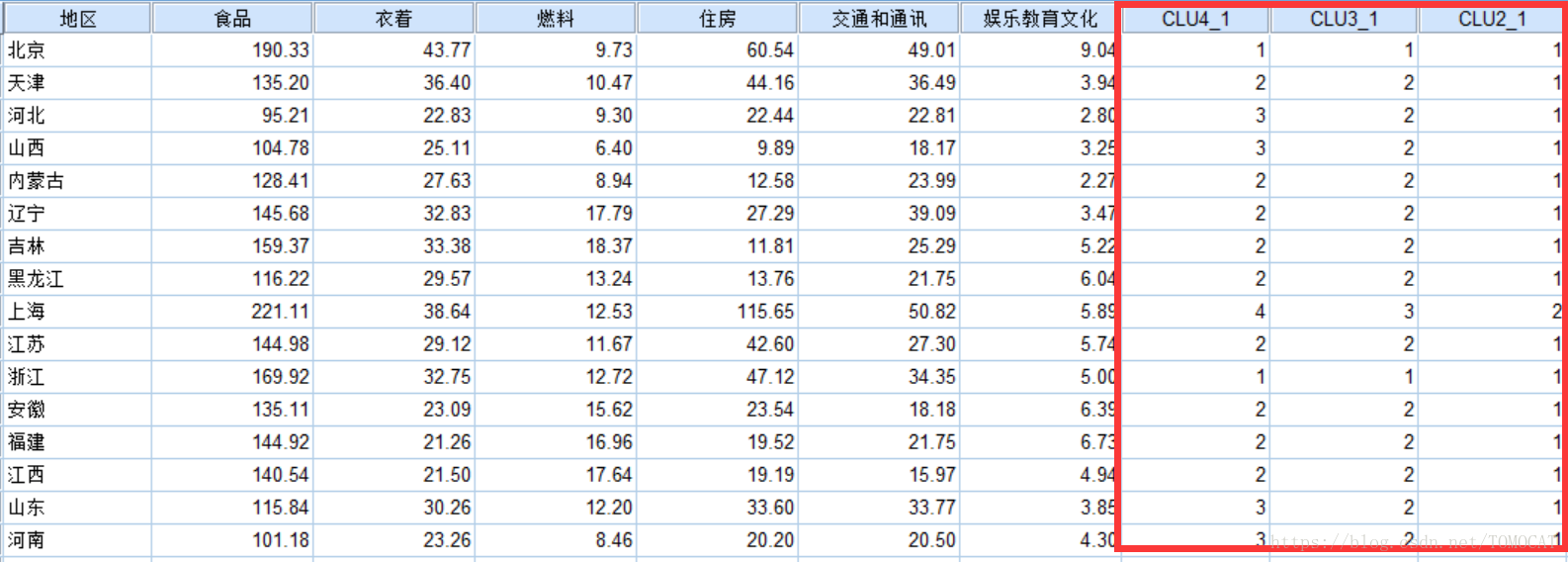
在变量视图中可以很明显看到个案被分为2、3和4类的情况,其中上海在三种方案中都自成一类,尤其是分为两类并不合适。
二、k-means聚类
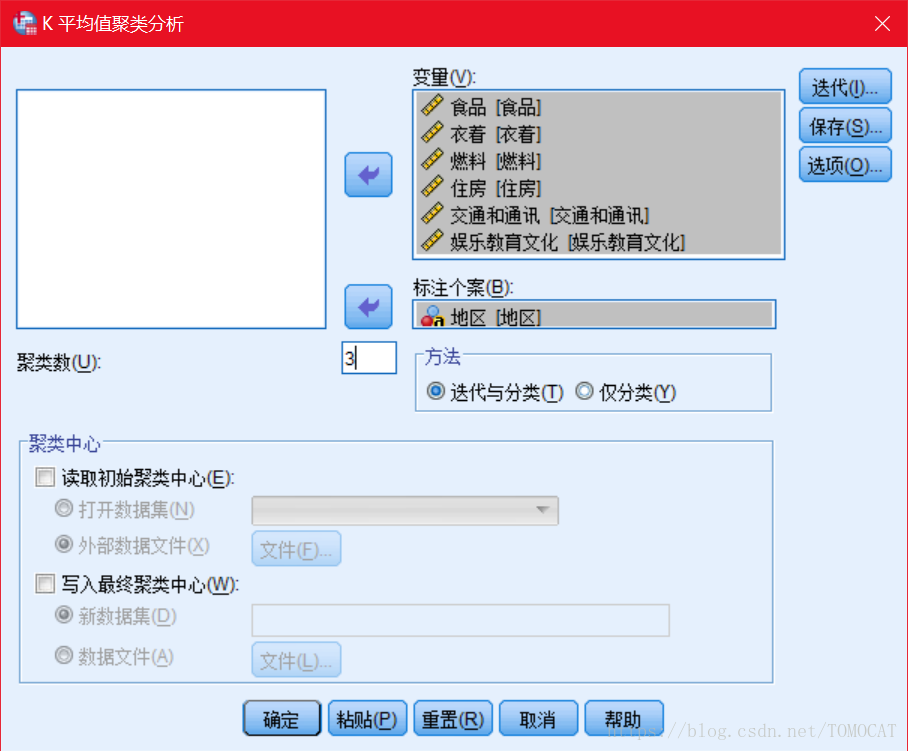
1、选择K-means聚类并把变量移入变量框。
选择聚类数为3且方法选择迭代与分类保证一直计算新的分类中心。
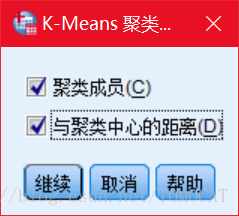
保存选项中同时选中聚类成员和与聚类中心的距离
在选项中选中初始聚类中心和对每个个案的聚类信息,则在输出窗口中将给出聚类的初始类中心和每个观测量的分类信息。
- 结果解释:
起始聚集中心给出了初始类的中心。
| 起始叢集中心 |
|||
|
|
叢集 |
||
| 1 |
2 |
3 |
|
| 食品 |
169.92 |
221.11 |
104.78 |
| 衣着 |
32.75 |
38.64 |
25.11 |
| 燃料 |
12.72 |
12.53 |
6.40 |
| 住房 |
47.12 |
115.65 |
9.89 |
| 交通和通讯 |
34.35 |
50.82 |
18.17 |
| 娱乐教育文化 |
5.00 |
5.89 |
3.25 |
迭代历程显示了经过两次迭代,故两次迭代后中心的变化为0。
| 疊代歷程a |
|||
| 疊代 |
叢集中心的變更 |
||
| 1 |
2 |
3 |
|
| 1 |
17.986 |
.000 |
16.864 |
| 2 |
.000 |
.000 |
.000 |
最终聚集中心显示除了每一类在每个变量标准下的平均值。
| 最終叢集中心 |
|||
|
|
叢集 |
||
| 1 |
2 |
3 |
|
| 食品 |
155.77 |
221.11 |
117.16 |
| 衣着 |
32.79 |
38.64 |
25.41 |
| 燃料 |
13.96 |
12.53 |
11.48 |
| 住房 |
36.15 |
115.65 |
19.40 |
| 交通和通讯 |
33.33 |
50.82 |
21.89 |
| 娱乐教育文化 |
5.59 |
5.89 |
4.23 |
三、两种方法的比较
1、关于聚类个数:系统聚类和k-means都需要自己选择聚类个数,但是系统聚类可以根据谱系图自己选择分类效果较好的几类。
2、聚类效果比较:
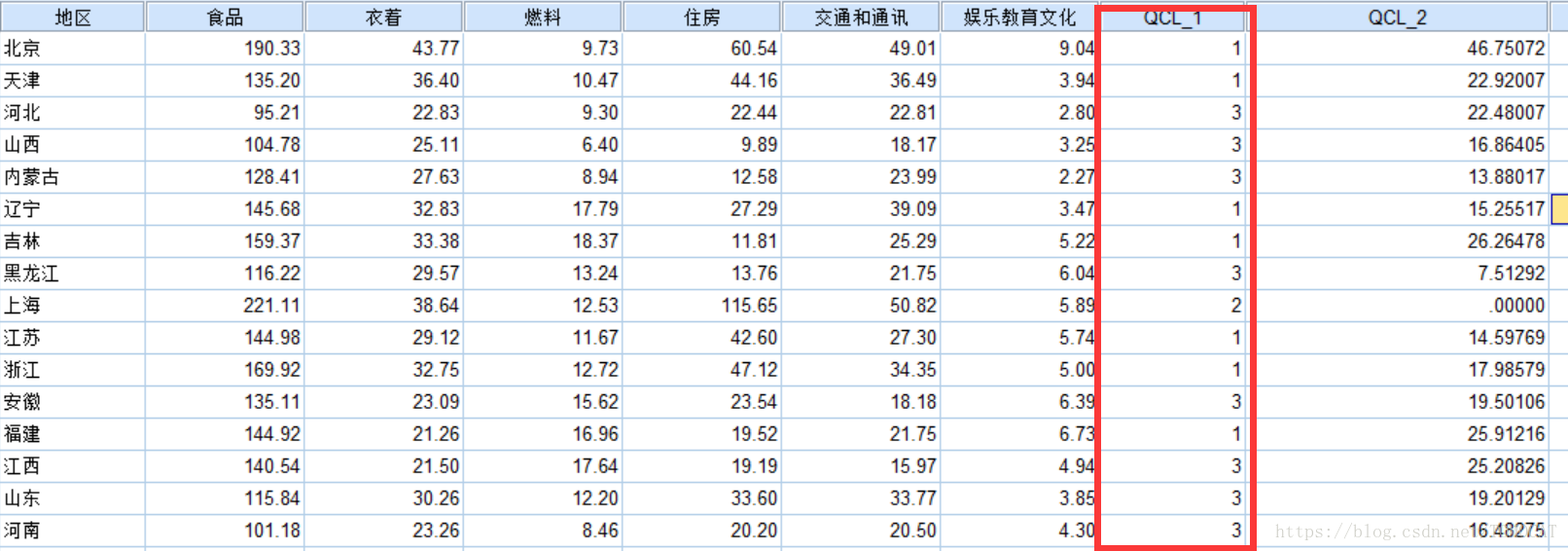
上图是k-means聚类的聚类结果,可以看到上海仍然自称一类,可见对于差异比较大的个案,两种方法都能区分出来,因而聚类效果基本一致。
但是系统聚类能看出各个个案之间关系的远近。
- 聚类能力比较:
在这个案例中没有体现出来,但是k-means由于计算量少,在处理大样本的时候更加有效率。