前言:
本专栏参考教材为《SPSS22.0从入门到精通》,由于软件版本原因,部分内容有所改变,为适应软件版本的变化,特此创作此专栏便于大家学习。本专栏使用软件为:SPSS25.0
本专栏所有的数据文件请点击此链接下载:SPSS数据分析专栏附件!
目录
1.快速聚类
快速聚类是一种针对大规模数据集的聚类方法,它能够快速地对数据进行划分和聚类。常见的快速聚类算法有K-Means、DBSCAN、层次聚类等。
K-Means是一种基于距离的聚类方法,通过不断迭代调整质心的位置,将数据划分为K个簇。
DBSCAN是一种基于密度的聚类方法,能够自动识别出不同密度的区域,并将点分别归为核心点、边界点或噪声点。
层次聚类是一种迭代的聚类方法,通过将最相似的数据点合并来不断构建树形结构,最终得到一棵聚类树。
SPSS快速聚类使用的是k-means聚类对数据进行聚类,聚类时注意选择合适的聚类数。
2.SPSS实现
(1)打开“data10-01”数据文件,选择“分析”——“分类”——“k-均值聚类”,弹出如图所示的对话框。
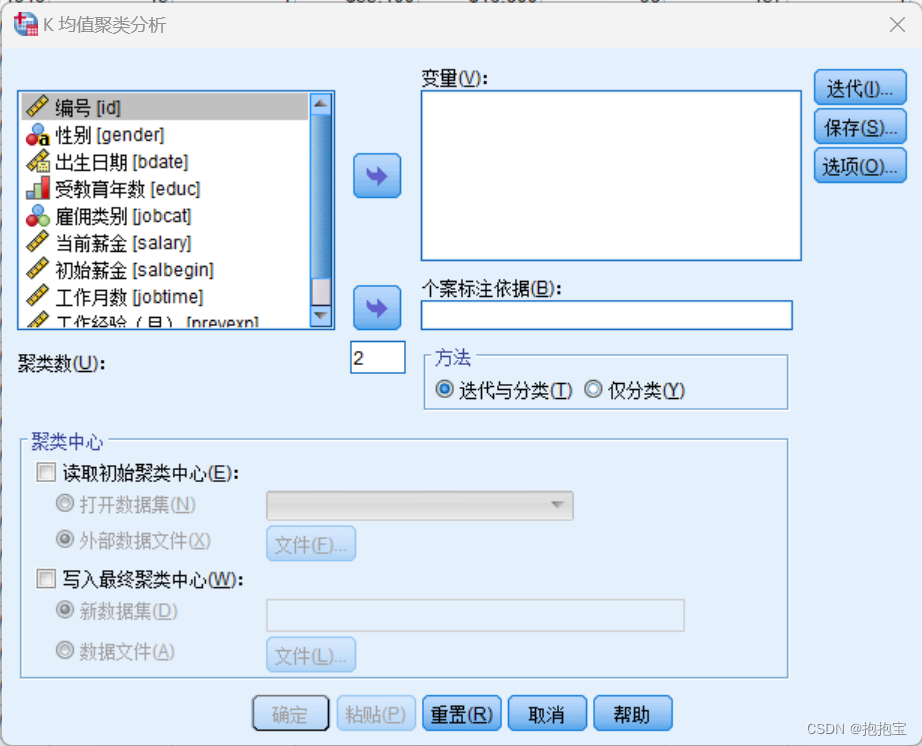
(2) 按照下图移动变量以及进行选项设置。

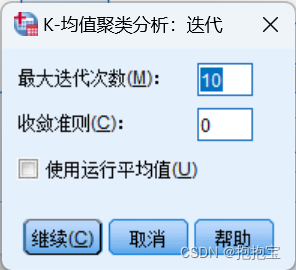
(3)单击“迭代”按钮,弹出下图所示的对话框,选项按照系统默认设置,单击继续返回主对话框。
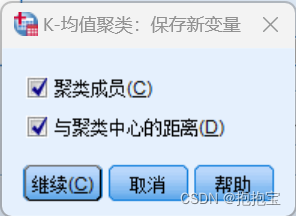
(4)单击“保存”按钮, 弹出“k-均值聚类:保存新变量”对话框,按照下图所示勾选对应选项,单击继续返回主对话框。
(5) 单击“选项”按钮,弹出“k-均值聚类分析:选项”对话框,按照下图所示勾选对应选项,单击继续返回主对话框。

(6)完成所有设置后,单击确定。
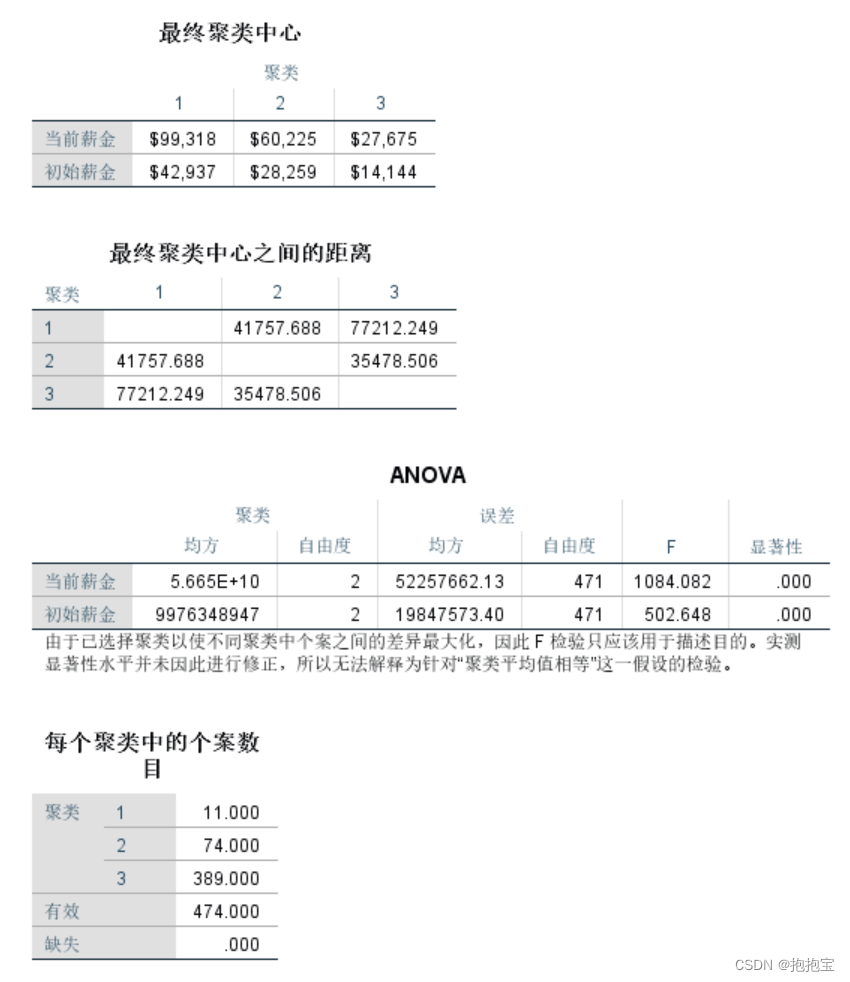
3.结果分析
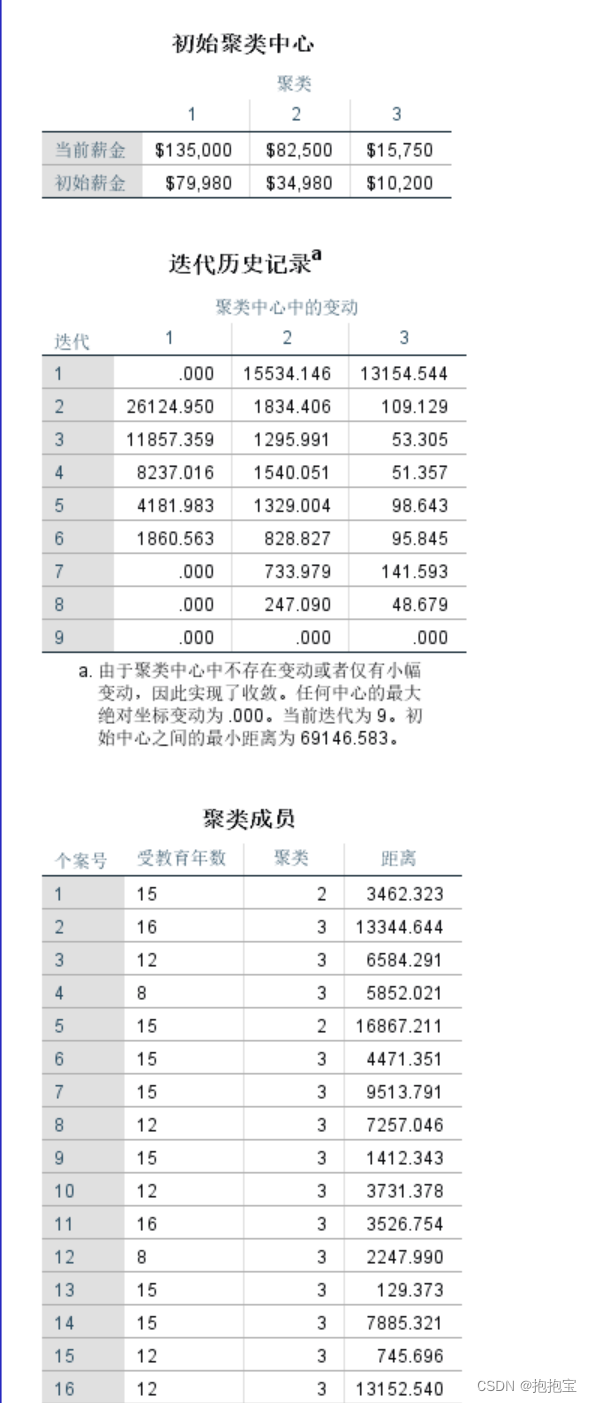
由于数据太多,此处只展示部分结果。