SPSS计算FRM模型分值
在spss的直销模块下,可以对客户数据进行FRM计算客户的FRM的分值,1.交易数据
2.客户数据(相当于客户数据汇总后的数据)
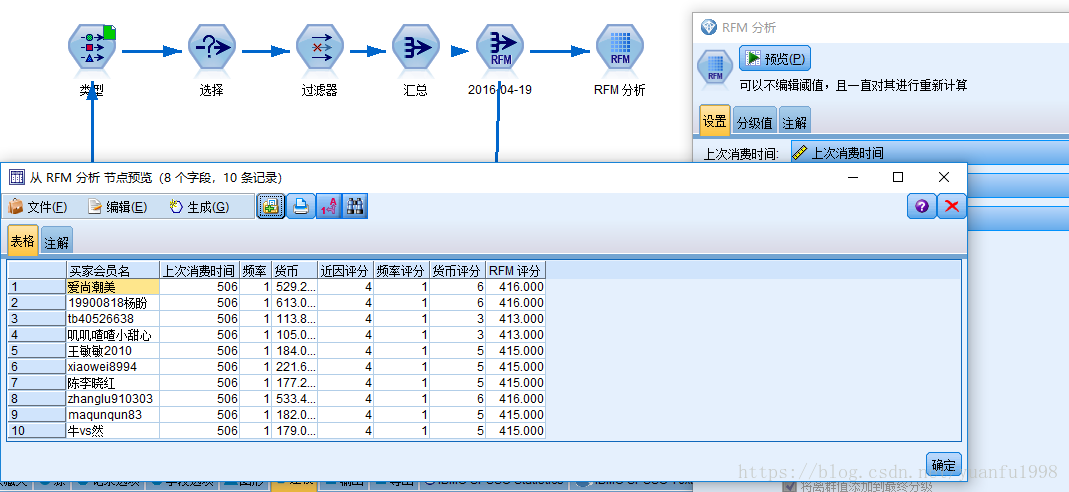
本例传入客户数据,计算后得到分值,及图表输出
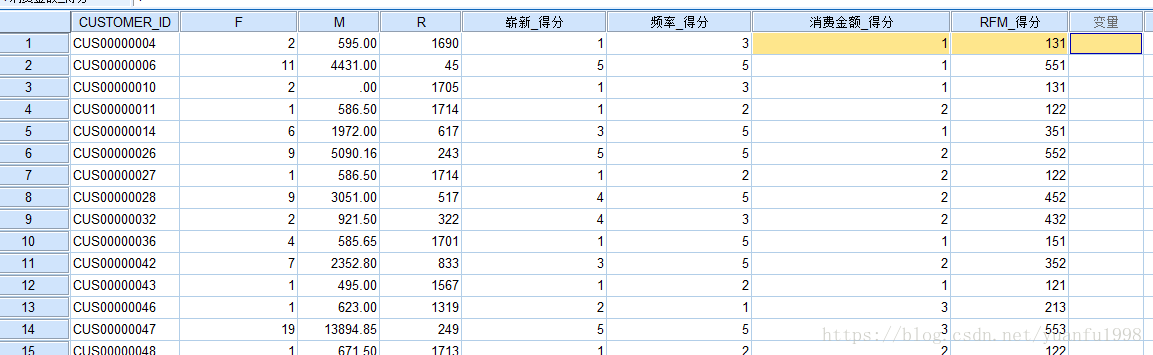
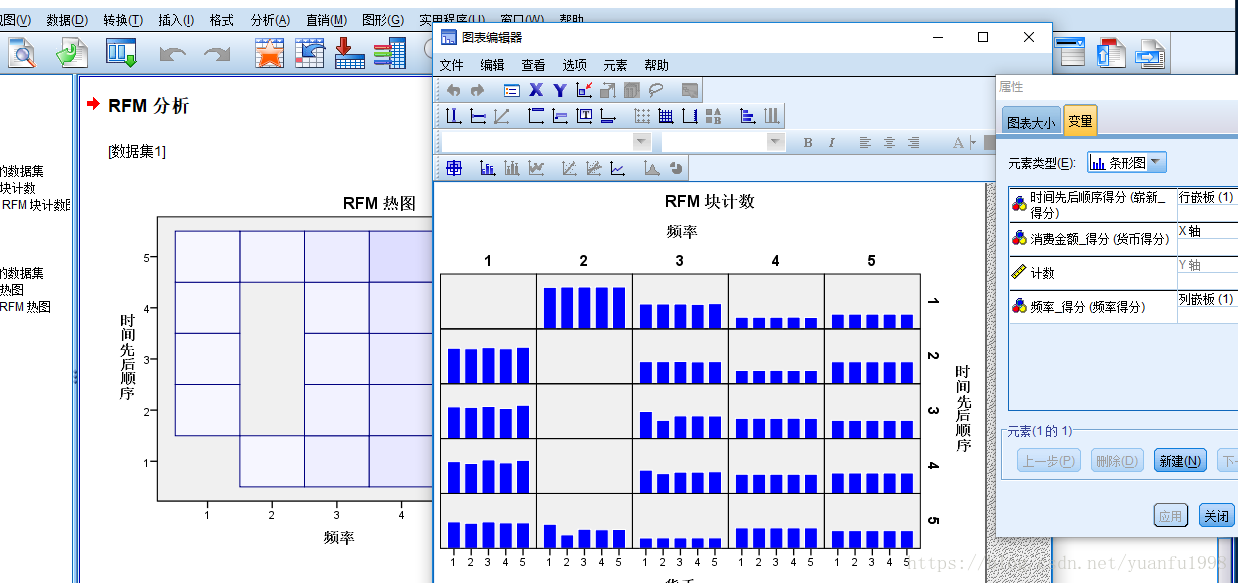
SPSS modeler——FRM分值计算及FRM聚类
spss modeler--仅能传入交易数据-原始数据,
模型结果输出
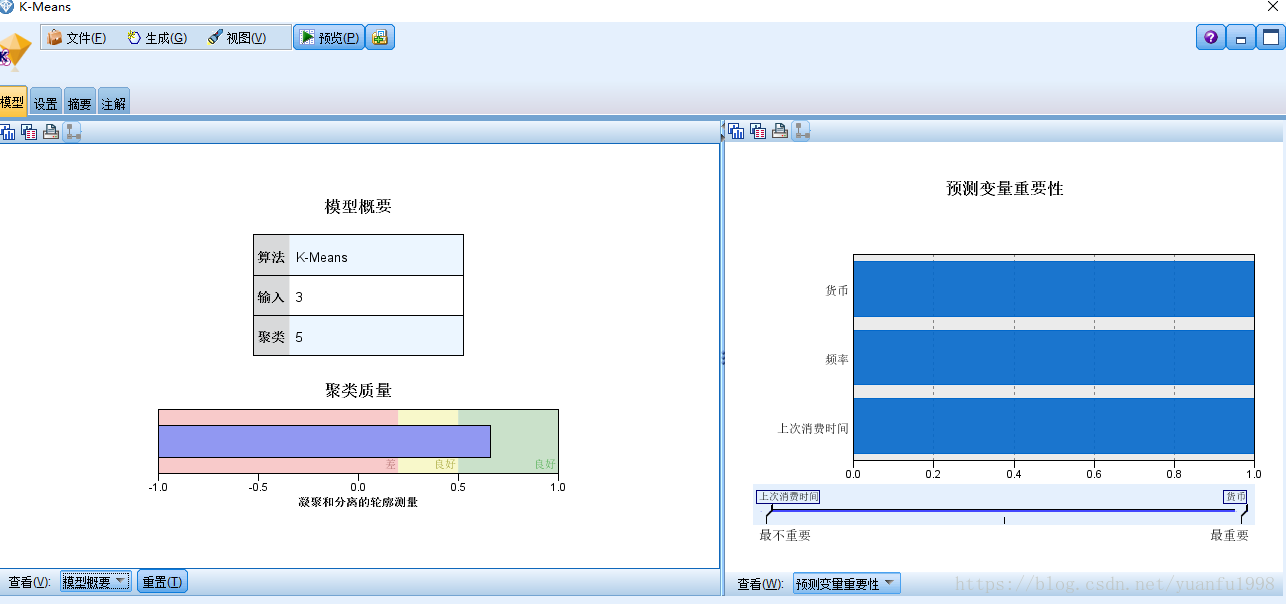
接常见的KM聚类

模型输出

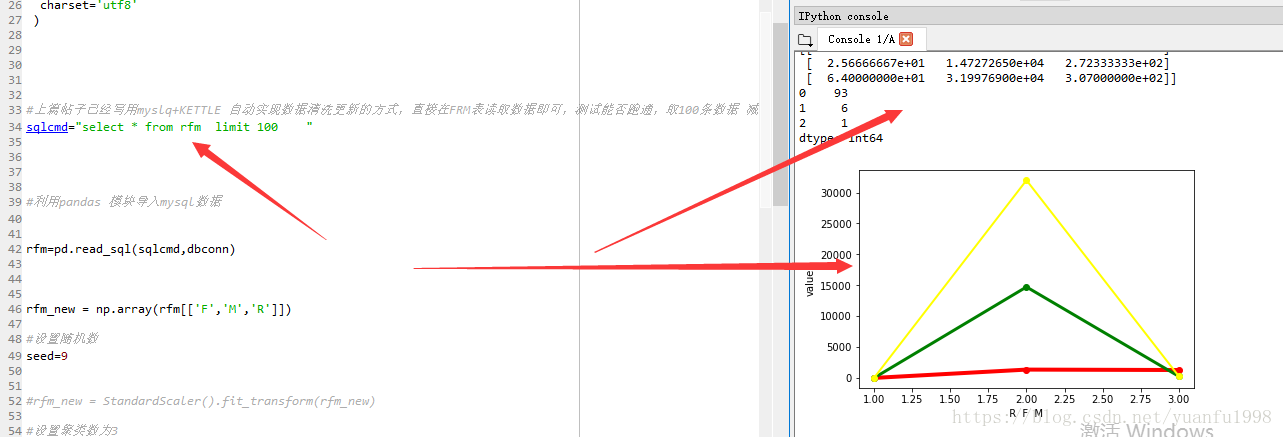
PYTHON实现FRM聚类
对数据取100条测试,输出
模型调优,聚类数选择
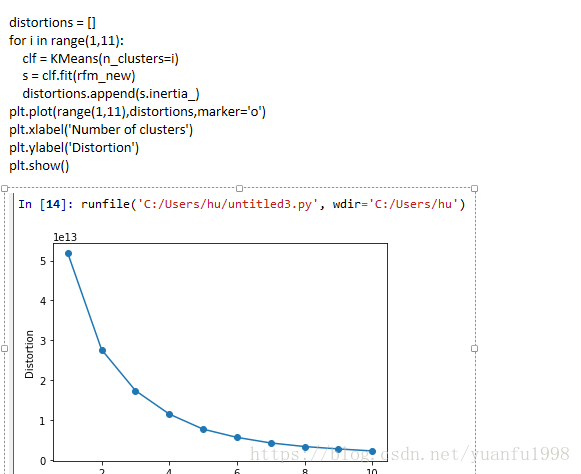
模型轮廓系数
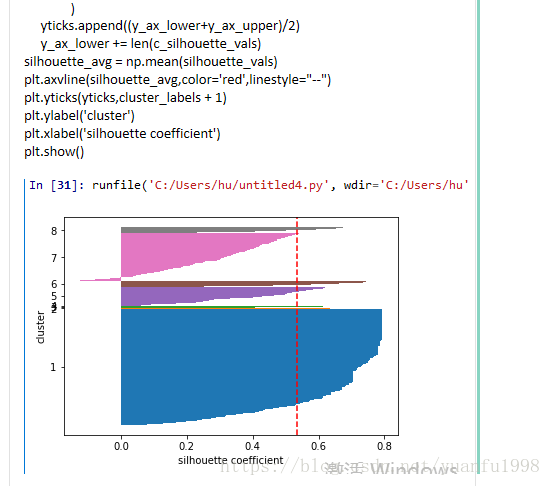
综上:SPSS计算FRM分值可以实现(交易数据及客户数据),及FRM分值分布,可视化输出,不能进行聚类操作
SPSS modeler可以计算FRM分值(仅交易数据),可接聚类模型,及模型可视化调优
Python 计算FRM分值,也可聚类,在模型的参数选择上非常具有优势(超参数),但是在模型调优,及可视化输出上,比较繁琐,且不友好。
很多人都会觉得用Python才高大上。其实SPSS和SPSS modeler 里都集成了R和Python的算法。
作为一个数据分析师,实现业务场景就行,其余的是算法工程师的事情。(分析师都做了,还要算法工程师干嘛?)
个人在工作中,除非确实需要用Python,就会用Python去做模型,譬如SPSS modeler 实现不了的 (协同过滤算法,推荐算法)。
一般在用IBM的SPSS modeler 做数据挖掘就够了。