以下内容笔记出自‘跟着迪哥学python数据分析与机器学习实战’,外加个人整理添加,仅供个人复习使用。
聚类为无监督算法
K-means聚类
基本思想简单,最典型的聚类算法。
工作流程
- 拿到数据集,指定K值(划分为K类);
- 既然分为K类,需要找到k个能代表每个类中心的点(质心:数据各维度的均值坐标点),但划分前不知质心在哪个位置,需要随机初始化k个坐标点;
- 选定k个中心点后,在所有数据样本中遍历,查看数据样本应属于哪个堆。具体来说,就是计算每个数据样本到中心点的距离,离哪个中心点近,属于哪一类;
- 第2步中的中心点是随机选择的,经过第3步,已经形成了K个以k各中心点为中心的类,此时需要计算得到各个类的中心点,更新中心点信息;
- 选定新的中心点后,再循环第3步;
- 反复不断迭代,不断求新的中心点位置,更新每一个数据点所属,最后,当中心点位置不变,也就是数据点所属类别固定下来时,K-means算法完成。
重要参数
- K值的确定
决定簇的个数 - 质心的选择
通常随机给出,但最初质心选择不同,最终结果也会有差异。所以只做一次实验是不够的。 - 距离的度量
常用欧式距离、余弦相似度等 - 评估方法
本身是无监督算法,没法用交叉验证来评估,只能大致观察结果的分布情况。
轮廓系数:
(1)计算样本 i 到同簇其他样本的平均距离a(i),越小说明样本越应该被聚类到该簇。a(i)称为样本 i 的簇内不相似度。
(2)计算样本 i 到其他某簇Ci 的所有样本的平均距离bi,称为样本 i 与簇Ci的不相似度。b(i)=min{b1,…,bk}.
(3)样本轮廓系数计算:
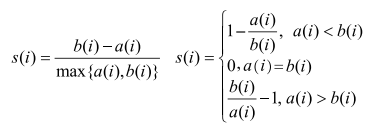
若s(i) 接近1,说明样本 i 聚类合理;s(i) 接近-1,说明样本 i 更应该分到另外的簇。若近似为0,说明样本 i 在两个簇的边界上。
所有样本的s(i)的均值,称为轮廓系数,是聚类是否合理的度量。
缺点:
1.K值难以估计;
2.初始质心选择有待改进;
3.在球形聚类上表现好,其他一般。
DBSCAN聚类
在kmeans聚类中,需要自己指定K值,能否让算法自己决定数据集划分为多少类别?不规则的簇该如何解决?
DBSCAN一定程度上解决这些问题。
DBSCAN算法常用于异常检测,注意力放在离群点上,当无监督问题中遇到检测任务时,是首选。
基本概念:
- 领域:给定对象半径r内的领域。DBSCAN中最核心的参数是半径,对结果会产生较大影响。
- 核心点:若对象的领域至少包含一定数目的数据点,则称该数据为核心对象,说明这个数据点周围比较密集。
- 边界点:边界点不是核心点,但落在某个核心点的邻域内,也就是数据集中的边界位置。
- 离群点:既不是核心点,也不是边界点的其他数据点,是落单的点。
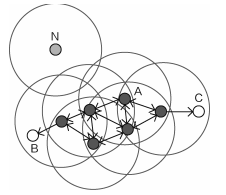
如图中,黑色点为核心对象,从每一个核心点发展出发都能将其他一部分数据点发展成为其营销对象(也就是其半径r邻域内圈到的数据点)。
空心点表示边界点,成为核心点的销售对象后,不能再继续发展,成为边界。
N为离群点。
对于一个数据点来说,直接的销售对象就是直接密度科大,通过它的已销售下属间接发展的就是密度可达。
工作流程

半径对结果的影响
需要指定半径r,通常情况下,半径越大,能够发展的对象越多,整体类别偏少,离群点也会偏少,而半径较小时,由于发展能力弱,出现类别会偏多,离群点也会偏多。
主要优点:
扫描二维码关注公众号,回复:
11701407 查看本文章

- 可对任意形状的稠密数据集聚类,而kmeans之类的算法一般只适用于秋装数据集;
- 非常适合检测任务,寻找离群点;
- 不需手动指定聚类的堆数,实际中也很难知道大致的堆数。
主要缺点:
- 若样本集的密度不均匀、聚类间距差相差很大时,聚类效果差;
- 半径选择较困难,不同半径的结果差异巨大。