1、流计算SQL原理和架构
流计算SQL通常是一个类SQL的声明式语言,主要用于对流式数据(Streams)的持续性查询,目的是在常见流计算平台和框架(如Storm、Spark Streaming、Flink、Beam等)的底层API上,
通过使用简易通用的的SQL语言构建SQL抽象层,降低实时开发的门槛。
流计算SQL的原理其实很简单,就是在SQL和底层的流计算引擎之间架起一座桥梁---流计算SQL被用户提交,被SQL引擎层翻译为底层的API并在底层的流计算引擎上执行。比如对Storm
来说,会自动翻译成Storm的任务拓扑并在Storm集群上运行。
流计算SQL引擎是流计算SQL的核心,主要负责对用户SQL输入进行语法分析、语义分析、逻辑计划生成、逻辑计划执行、物理执行计划生成等操作。而真正执行计算的是底层的流计算平台。
不同于离线任务,实时的数据是不断流入的,所以为了使用SQL来对流处理进行抽象,流计算SQL也引入了“表”的概念,不过这里的表是动态表。
流计算SQL的架构如下:
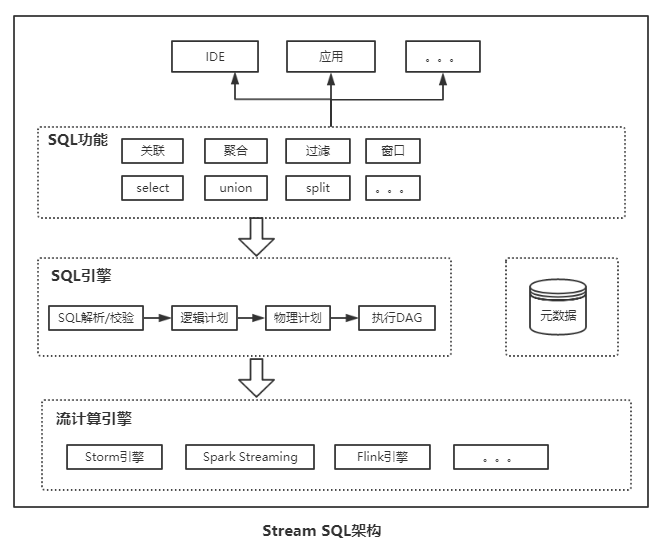
SQL层:流计算SQL给用户的接口,它提供过滤、转换、关联、聚合、窗口、select、union、split等各种功能。
SQL引擎层:负责SQL解析/校验、逻辑计划生成优化和物理计划执行等。
流计算引擎层:具体执行SQL引擎层生成的执行计划。
2、流计算SQL:未来主要的实时开发技术
目前流计算SQL在各个计算框架的进度和支持力度不一。
Storm SQL还只是一个实验性的功能。Flink SQL是Flink大力推广的核心API。Flink是一个原生的开源流计算引擎,而且目前还没有其它开源流计算引擎能提供比Flink 更优秀的流
计算SQL框架和语法等,所以Flink SQL实际上在定义流计算SQL的标注。
阿里云Stream SQL 的底层就是Flink引擎(实际是Blink,也就是Alibaba Flink),可以认为Blink是Flink的企业版本,
3、Stream SQL