第一章 概述
数据分为以下几类:
1.结构化数据 :数据库中的数据
2.半结构化数据:日志文件、XML/JSON
3.非结构化数据:图像、声音
数据储存处理
1.离线处理:按天进行数据处理,每天凌晨等数据采集和同步的数据到位后,相关的数据处理任务会被按照预先谁的ETL(抽取、转换、加载)逻辑以及ETL任务之间的拓扑关系一次调用。最终数据会被写入离线数据仓库中。离线数据仓库通常是按照某一种建模思想(维度建模)精心组织的。
离线数据通常放在一个Staging Area(暂存区)。
Google三篇论文:hdfs/mapreduce/hbase
2.实时处理:以秒为单位。依赖Storm/类 Storm 的流处理框架和 Spark 生态的 Spark Streaming
3.近线数据:以小时、15分钟为单位
数据采集传输–处理–储存
离线批处理:Sqoop作为采集和传输工具、Hive作为离线数据处理平台、HDFS、Hbase作为数据存储。
MapReduce HDFS 基础上实现了任务的分发、跟踪和执行等工作,并收
集结果,两者相互作用,共同完成了 Hadoop 分布式集群的主要任务
实时采集和传输:Flume 和Kafka作为采集和传输工具、Storm、Spark、Flink作为处理平台
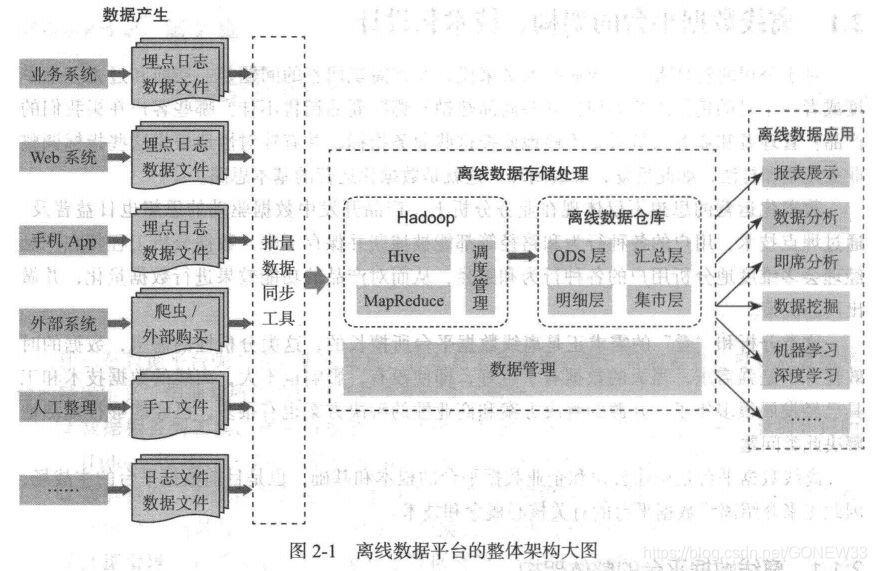
离线数据平台通常和 Hadoop Hive 、数据仓库、 ETL 、维度建模、 数据公共层等联系在一起。
离线数据平台的另一个关键技术是数据的建模,目前采用最为广泛也最为大家认同的是维度建模技术。
数据仓库技术
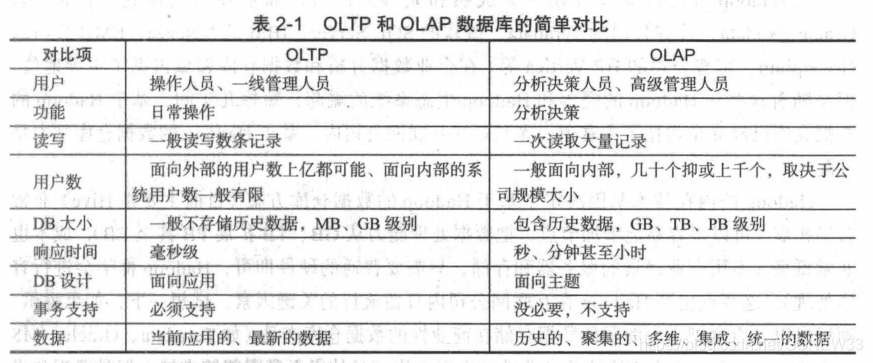
OLTP:是 Online Transaction ~rocessing ,顾名思义, OLTP 数据库主要用来进行事务处理,比如新增一个订单、修改一个订单、查询一个订单和作废一个订单等 OLTP 数据库最核心的需求是单条记录的高效快速处理,索引技术、分库分表等最根本的诉求就是解决此问题。问题是太慢了
OLAP:本身能够处理和统计大量的数据。一般只需要处理数据查询请求,数据都是批量导入的,因此通过列存储、列压缩、位图索引等技术可以大大加快相应请求速度。
Hadoop数据仓库
在hadoop出现之前,商业性的数据仓库产品占据主导。现在,基于hadoop的数据仓库以及是互联网公司的标配。hadoop内在的技术基因决定了其非常容易扩展,成本低廉。
面临的最大挑战是数据查询延迟(几分钟,甚至几个小时),Hive SQL 是高延迟的,不但翻译成的 MapReduce 任务执行延迟高,任务 提交和处理过程中也会消耗时间 因此,即使 ive 处理的数据集非常小(比如 MB ),在执行时 会出现延迟现象
第二章
HDFS:分布式文件系统,hadoop核心子项目。
优势:1.处理超大文件 2.高容错性和高可靠性3.运行于廉价的机器集群4.流式的访问数据
劣势:1.不合适低延迟数据访问2.无法高效储存大量小文件3.不支持多用户写入和随机文件修改
MapReduce:分布式计算模型 hadoop核心子项目。
优势:1.MapReduce易于编程2.良好的拓展性(加电脑)3.高容错性(任务转移到别的电脑)
劣势:1.高延迟2.静态,无法处理动态3.
HDFS MapReduce 基本架构
分工明确,HDFS负责分布式储存,MapReduce负责分布式计算
HDFS 采用了主从( Master/Slave )的结构模型,一个HDFS 集群是由一个 NameNode 和若干个 DataNode 组成的。NameNode 执行文件系统的命名空间操作,比如打开、关闭、重命名文件或目录等,它也 负责数据块到具体 DataNode 的映射 DataNode 责处理文件系统客户端的文件读写请求,并在 NameNode 的统一调度下进行数据块的创建、删除和复制工作
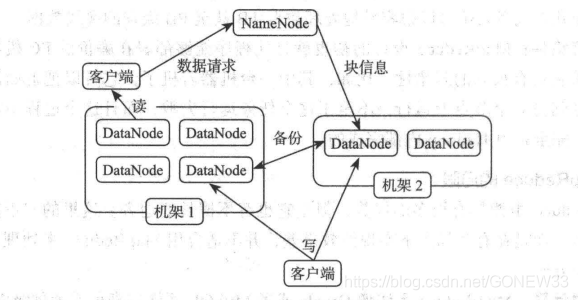
NameNode 是所有 HDFS 元数据的管理者用户数据不会经过 NameNode
MapReduce也是采用 Master/Slave 的主从架构。有4个部分。Client、JobTracker、TaskTracker、Task
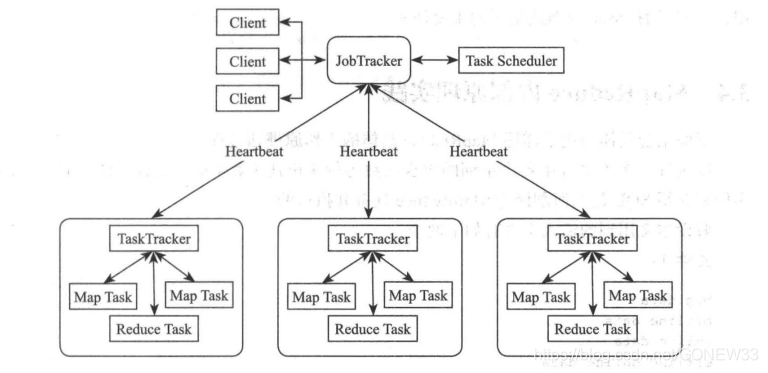
( 1 ) Client
每个 Job 都会在用户端通过 Client 类将应用程序以及配置参数 Configuration 打包成 JAR 文件存储在 HDFS 中,并把路径提交到 JobTracker Master 务,然后由 Master 创建每一个 Task (即 MapTask ReduceTask )将它们分发到各个 TaskTracker 服务中去执行
( 2 ) JobTracker
Job Tracker 负责资源监控和作业调度 JobTracker 监控所有 TaskTracker Job 的健康 状况,一旦发现失败,就将相应的任务转移到其他节点;同时,JobTracker会跟踪任务的执行进度、资源使用量等会信息,并将这些信息告诉任务调速器,而调速器在资源出现空闲时,会选择合适的任务使用这些资源。在hadoop中,任务调速器是一个可插拔的模块,用户可以根据自己的需要设计相应的调速器。
( 3) TaskTracker
TaskTracker 会周期性地通过 Heartbeat 将本节点上资源的使用情况和任务的运行进度汇报给 JobTracker 同时接收 JobTracker 发送过来的命令并执行相应的操作(如启动新任务、杀死任务等)
TaskTracker 使用 slot 来衡量划分本节点上的资源量, slot 代表单位的计算资源( CPU、内存等) 。一 τask 获取到一个 slot 后才有机会运行,而 Hadoop调度器的作用就是将各个 TaskTracker 上的空闲 slot 分配给 Task 使用, slot 分为 Map slot Reduce slot 两种,分别供 MapTask/Reduce Task 使用 TaskTracker 通过 slot 数目(可配置参数) 限定 Task 的并发度
(4)Task
Task 分为 Map Task Reduce Task 两种,均由 TaskTracker 启动 HDFS 以固定大小 block 为基本单位存储数据,而对于 MapReduce 而言,其处理单位是split

从上面的描述可以看出, HDFS 、MapReduce 共同组成了 HDFS 体系结构的核心 。HDFS 在集群上实现了分布式文件系统, MapReduce 在集群上实现了分布式计算和任务处理。 HDFS MapReduce 任务处理过程中提供了对文件操作和存储等的支持,而 Map Reduce 在HDFS 础上实现了任务的分发、跟踪和执行等工作,并收集结果,两者相互作用,完成了hadoop分布式集群的主要任务。
MapReduce内部事件原理实践
Map逻辑和Reduce逻辑和输入文件,丢给hadoop,hadoop将会自动完成所有分布式计算任务。
编写好的MapReduce程序是一个Job,Job——>jabTracker(检查、输入分片)——>让job排队——>作业调度器调度作业——>创建一个运行的Job对象——>jobTracker跟踪
完成后,客户端会查到Job完成的通知,如果Job中途失败,MapReduce也会有相应的机制处理。如果不是程序本身有BUG,MapReduce错误处理机制都能保证提交的Job正常完成。
MapReduce内部执行原理详解
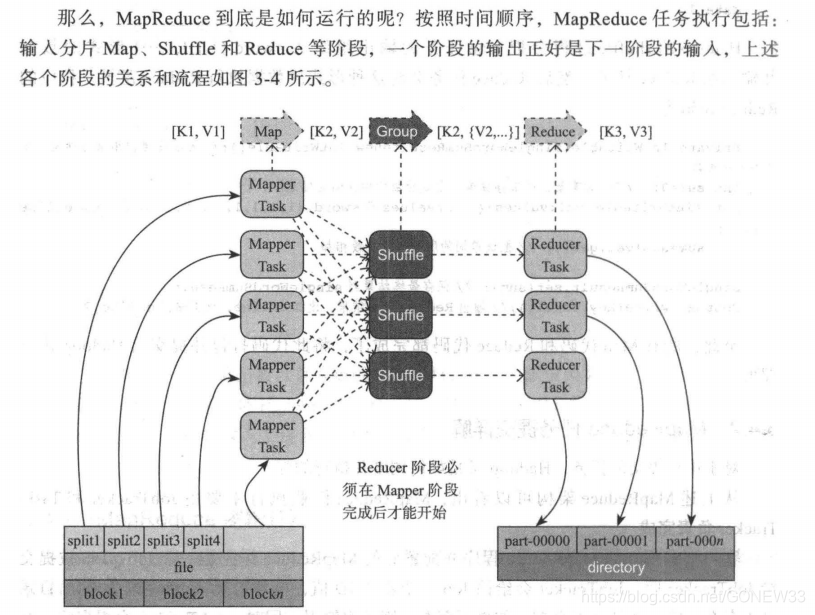
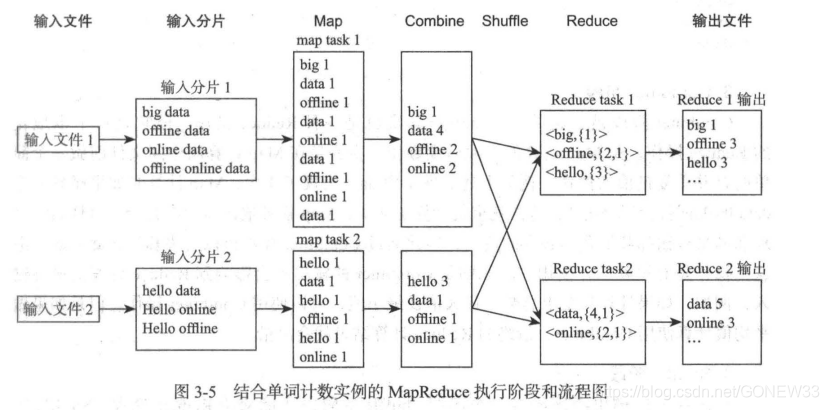
1.输入分片
如果输入文件都是小于HDFS的快大小(Block),那么一个文件就是一个分片
如果输入文件大于Block,那么就切块,最大不超过Block的大小。
(PS:过多的小文件会创建过多的map任务,合并小文件时MapReduce优化的一个关键点)
2.Map阶段
在Map阶段,各个Map任务会接受到所分配到的split,并调用Map函数,逐行执行并输出键值对。
3.Combiner阶段
Combiner阶段是可选的,它其实也是一种Reduce操作,但是她是一个本地化的Reduce操作,是Map运算的本地后续操作,主要是在Map计算出中间文件钱做一个简单的合并重复健值的操作。这一操作有风险:如果做平均值计算使用Conbiner,最终的Reduce计算结果就会出错。
4.Shuffle阶段
Map任务的输出必须经过一个名叫做Shuffle的阶段才交给Reduce处理,Shuffle阶段是MapReduce的核心。
1)Map阶段Shuddle
通常计算的是海量数据,开设缓冲区,设置阈值(80%),满了以后就写入磁盘(分割)。写入磁盘前会根据Reduce数目分区。每次分割产生一个分割文件,在Map任务结束前,对分割文件合并。最终生成的文件放在TaskTracker能访问的本地目录内。等待Reduce Task去获取。
2)Reduce阶段Shuddle
第一步:获取Map 输出
第二步:Merge:把各个Map合并
第三步:Reduce Task的输入
5.Redece阶段
经过Shuffle阶段,Reduce任务的输入终于准备完毕,相关的数据以及被合并和汇总
第三章 Hive原理实践
持续更新
